IT运维平台算法背后的两大“神助攻”
来源:互联网 发布:如何判断存在sql注入 编辑:程序博客网 时间:2024/04/25 08:41
http://os.51cto.com/art/201705/541225.htm?utm_source=tuicool&utm_medium=referral
一、异常检测
异常检测,是运维工程师们最先可能接触的地方了。毕竟监控告警是所有运维工作的基础。设定告警阈值是一项耗时耗力的工作,需要运维人员在充分了解业务的前提下才能进行,还得考虑业务是不是平稳发展状态,否则一两周改动一次,运维工程师绝对是要发疯的。
如果能将这部分工作交给算法来解决,无疑是推翻一座大山。这件事情,机器学习当然可以做到。但是不用机器学习,基于数学统计的算法,同样可以,而且效果也不差。
异常检测之Skyline异常检测模块
2013年,Etsy 开源了一个内部的运维系统,叫 Kale。其中的 skyline 部分,就是做异常检测的模块,它提供了 9 种异常检测算法:
first_hour_average、
simple_stddev_from_moving_average、
stddev_from_moving_average、
mean_subtraction_cumulation、
least_squares
histogram_bins、
grubbs、
median_absolute_deviation、
Kolmogorov-Smirnov_test
简要的概括来说,这9种算法分为两类:
从正态分布入手:假设数据服从高斯分布,可以通过标准差来确定绝大多数数据点的区间;或者根据分布的直方图,落在过少直方里的数据就是异常;或者根据箱体图分析来避免造成长尾影响。
从样本校验入手:采用 Kolmogorov-Smirnov、Shapiro-Wilk、Lilliefor 等非参数校验方法。
这些都是统计学上的算法,而不是机器学习的事情。当然,Etsy 这个 Skyline 项目并不是异常检测的全部。
首先,这里只考虑了一个指标自己的状态,从纵向的时序角度做异常检测。而没有考虑业务的复杂性导致的横向异常。其次,提供了这么多种算法,到底一个指标在哪种算法下判断的更准?这又是一个很难判断的事情。
问题一:实现上的抉择。同样的样本校验算法,可以用来对比一个指标的当前和历史情况,也可以用来对比多个指标里哪个跟别的指标不一样。
问题二:Skyline 其实自己采用了一种特别朴实和简单的办法来做补充——9 个算法每人一票,投票达到阈值就算数。至于这个阈值,一般算 6 或者 7 这样,即占到大多数即可。
异常检测之Opprentice系统
作为对比,面对相同的问题,百度 SRE 的智能运维是怎么处理的。在去年的 APMcon 上,百度工程师描述 Opprentice 系统的主要思想时,用了这么一张图:
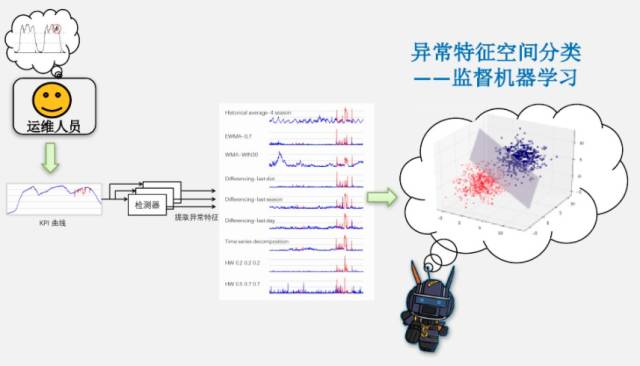
Opprentice 系统的主体流程为:
KPI 数据经过各式 detector 计算得到每个点的诸多 feature;
通过专门的交互工具,由运维人员标记 KPI 数据的异常时间段;
采用随机森林算法做异常分类。
其中 detector 有14种异常检测算法,如下图:

我们可以看到其中很多算法在 Etsy 的 Skyline 里同样存在。不过,为避免给这么多算法调配参数,直接采用的办法是:每个参数的取值范围均等分一下——反正随机森林不要求什么特征工程。如,用 holt-winters 做为一类 detector。holt-winters 有α,β,γ 三个参数,取值范围都是 [0, 1]。那么它就采样为 (0.2, 0.4, 0.6, 0.8),也就是 4 ** 3 = 64 个可能。那么每个点就此得到 64 个特征值。
异常检测之
Opprentice 系统与 Skyline 很相似
Opprentice 系统整个流程跟 skyline 的思想相似之处在于先通过不同的统计学上的算法来尝试发现异常,然后通过一个多数同意的方式/算法来确定最终的判定结果。
只不过这里百度采用了一个随机森林的算法,来更靠谱一点的投票。而 Etsy 呢?在 skyline 开源几个月后,他们内部又实现了新版本,叫 Thyme。利用了小波分解、傅里叶变换、Mann-whitney 检测等等技术。
另外,社区在 Skyline 上同样做了后续更新,Earthgecko 利用 Tsfresh 模块来提取时序数据的特征值,以此做多时序之间的异常检测。我们可以看到,后续发展的两种 Skyline,依然都没有使用机器学习,而是进一步深度挖掘和调整时序相关的统计学算法。
开源社区除了 Etsy,还有诸多巨头也开源过各式其他的时序异常检测算法库,大多是在 2015 年开始的。列举如下:
Yahoo! 在去年开源的 egads 库。(Java)
Twitter 在去年开源的 anomalydetection 库。(R)
Netflix 在 2015 年开源的 Surus 库。(Pig,基于PCA)
其中 Twitter 这个库还被 port 到 Python 社区,有兴趣的读者也可以试试。
二、归因分析
归因分析是运维工作的下一大块内容,就是收到报警以后的排障。对于简单故障,应对方案一般也很简单,采用 service restart engineering~ 但是在大规模 IT 环境下,通常一个故障会触发或导致大面积的告警发生。如果能从大面积的告警中,找到最紧迫最要紧的那个,肯定能大大的缩短故障恢复时间(MTTR)。
这个故障定位的需求,通常被归类为根因分析(RCA,Root Cause Analysis)。当然,RCA 可不止故障定位一个用途,性能优化的过程通常也是 RCA 的一种。
归因分析之 Oculus 模块
和异常检测一样,做 RCA 同样是可以统计学和机器学习方法并行的~我们还是从统计学的角度开始。依然是 Etsy 的 kale 系统,其中除了做异常检测的 skyline 以外,还有另外一部分,叫 Oculus。而且在 Etsy 重构 kale 2.0 的时候,Oculus 被认为是1.0 最成功的部分,完整保留下来了。
Oculus 的思路,用一句话描述,就是:如果一个监控指标的时间趋势图走势,跟另一个监控指标的趋势图长得比较像,那它们很可能是被同一个根因影响的。那么,如果整体 IT 环境内的时间同步是可靠的,且监控指标的颗粒度比较细的情况下,我们就可能近似的推断:跟一个告警比较像的最早的那个监控指标,应该就是需要重点关注的根因了。
Oculus 截图如下:
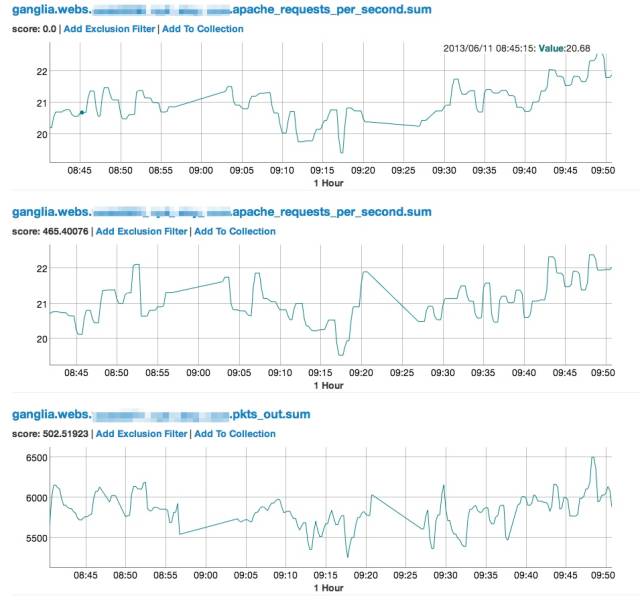
这部分使用的计算方式有两种:
欧式距离,就是不同时序数据,在相同时刻做对比。假如0分0秒,a和b相差1000,0分5秒,也相差1000,依次类推。
FastDTW,则加了一层偏移量,0分0秒的a和0分5秒的b相差1000,0分5秒的a和0分10秒的b也相差1000,依次类推。当然,算法在这个简单假设背后,是有很多降低计算复杂度的具体实现的,这里就不谈了。
唯一可惜的是 Etsy 当初实现 Oculus 是基于 ES 的 0.20 版本,后来该版本一直没有更新。现在停留在这么老版本的 ES 用户应该很少了。除了 Oculus,还有很多其他产品,采用不同的统计学原理,达到类似的效果。
归因分析之 Granger causality
Granger causality(格兰杰因果关系)是一种算法,简单来说它通过比较“已知上一时刻所有信息,这一时刻 X 的概率分布情况”和“已知上一时刻除 Y 以外的所有信息,这一时刻 X 的概率分布情况”,来判断 Y 对 X 是否存在因果关系。
可能有了解过一点机器学习信息的读者会很诧异了:不是说机器只能反应相关性,不能反应因果性的么?需要说明一下,这里的因果,是统计学意义上的因果,不是我们通常哲学意义上的因果。
统计学上的因果定义是:『在宇宙中所有其他事件的发生情况固定不变的条件下,如果一个事件 A 的发生与不发生对于另一个事件 B 的发生的概率有影响,并且这两个事件在时间上有先后顺序(A 前 B 后),那么我们便可以说 A 是 B 的原因。』
归因分析之皮尔逊系数
另一个常用的算法是皮尔逊系数。下图是某 ITOM 软件的实现:
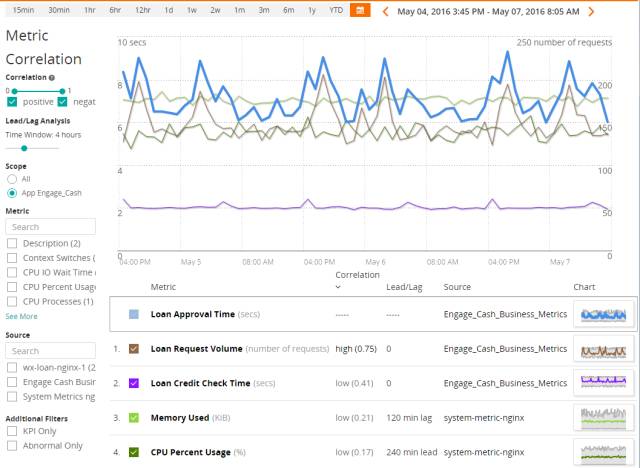
我们可以看到,其主要元素和采用 FastDTW 算法的 Oculus 类似:correlation 表示相关性的评分、lead/lag 表示不同时序数据在时间轴上的偏移量。
皮尔逊系数在 R 语言里可以特别简单的做到。比如我们拿到同时间段的访问量和服务器 CPU 使用率:
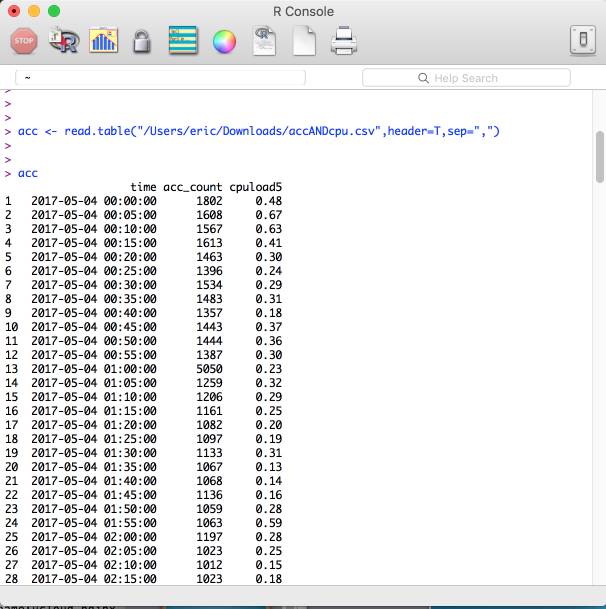
然后运行如下命令:
- acc_count<-scale(acc$acc_count,center=T,scale=T)
- cpu<-scale(acc$cpuload5,center=T,scale=T)
- cor.test(acc_count,cpu)
可以看到如下结果输出:
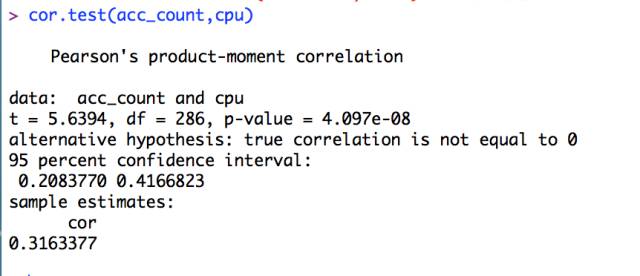
对应的可视化图形如下:
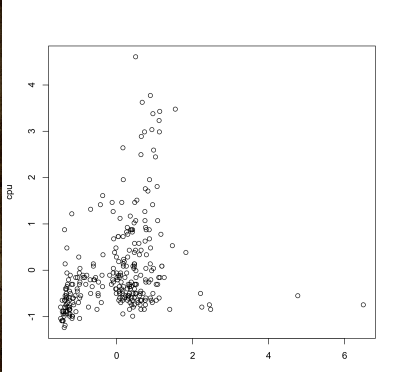
这就说明网站数据访问量和 CPU 存在弱相关,同时从散点图上看两者为非线性关系。因此访问量上升不一定会真正影响 CPU 消耗。
其实 R 语言不太适合嵌入到现有的运维系统中。那这时候使用 Elasticsearch 的工程师就有福了。ES 在大家常用的 metric aggregation、bucket aggregation、pipeline aggregation 之外,还提供了一种 matrix aggregation,目前唯一支持的 matrix_stats 就是采用了皮尔逊系数的计算,接口文档见:
https://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations-matrix-stats-aggregation.html
唯一需要注意的就是,要求计算相关性的两个字段必须同时存在于一个 event 里。所以没法直接从现成的 ES 数据中请求不同的 date_histogram,然后计算,需要自己手动整理一遍,转储回 ES 再计算。
- IT运维平台算法背后的两大“神助攻”
- 看板背后两大基础性原则
- Linux的神之助攻——Vim
- iphone背后的IT规律
- IT运维的五大基础知识
- IT规划的两大困惑及未来之路
- “双十一”背后的隐形战场:电商后台IT技术大检阅
- IT大牛养成指南(一鸣惊人背后是1万小时的不断练习)
- 300亿电商背后的IT架构美学与运维经验
- 琅琊靠谱鸟榜-北大夺嫡,武大助攻
- 线下活动 | 揭秘大数据背后的京东虚拟平台(免费报名中)
- IT运维服务外包管理的两种模式
- 背后实力大比拼 探秘七大IT巨头实验室
- 网络管理工具与IT运维管理平台的差别
- IT运维管理平台的事实标准ITIL
- “平台模式”将成IT运维建设的根基
- Google背后的IT架构策略揭秘
- Google背后的IT架构策略揭秘
- Java类的初始化顺序
- AngularJS 06(路由)
- Log分析
- 数据库的数据库及表的修改和删除基础知识
- GNU C attribute section的一个使用例子
- IT运维平台算法背后的两大“神助攻”
- mybatis1-mybatis介绍
- MyBatis逆向工程自动生成代码
- 散列表查找实现
- 教你防范勒索软件:加强网络环境的6条建议
- 各种选项卡
- 设计模式-单例模式
- 设计模式之单例模式
- Jmeter后置处理器-正则表达式提取器


