云计算的利刃:快速部署Hadoop集群
来源:互联网 发布:超数据恢复软件破解版 编辑:程序博客网 时间:2024/04/26 06:16
云计算的利刃:快速部署Hadoop集群
【IT168 专稿】近来云计算越来越热门了,云计算已经被看作IT业的新趋势。云计算可以粗略地定义为使用自己环境之外的某一服务提供的可伸缩计算资源,并按使用量付费。可以通过 Internet 访问“云”中的任何资源,而不需要担心计算能力、带宽、存储、安全性和可靠性等问题。
从企业的角度来说,日益增长的信息已经很难存储在标准关系型数据库甚至数据仓库中。这些问题提到了一些在实践中已存在多年的难题。例如:怎样查询一个十亿行的表?怎样跨越数据中心所有服务器上的所有日志来运行一个查询?更为复杂的问题是,大量需要处理的数据是非结构化或者半结构化的,这就更难查询了。
“云计算”领域已经成为众多跨国IT巨头未来“决斗”的主战场。由于意识到“云计算”将是一场改变IT格局的划时代变革,几乎所有重量级跨国IT巨头从不同领域和角度开始在“云计算”领域扎根,这个阵营的主力包括Amazon、Google、IBM、Mircosoft、VMware、Cisoco、Intel、AMD、Oracle、SAP、HP、Dell、Citrix、 Redhat、Novell、Yahoo等等。美国硅谷目前已约有150家涉及“云计算”的企业,新的商业模式层出不穷。
“云计算”庞大的市场规模超乎想象。按照最乐观估计,IDC推算未来3年全球“云计算”领域将有8000亿美元的新业务收入。显然,全球各IT巨头竞相进入“云计算”领域背后的原因是未来天文数字般的市场规模以及由此带来的无比光明的发展前景。自2011年开始,各大IT企业已经展开一场硝烟滚滚的争夺战,以实现自己在“云计算”市场中未来的霸主地位。
Hadoop简介
Apache Hadoop 是一个软件框架,它可以分布式地操纵大量数据。它于2006年首次提及,由 Google、Yahoo! 和 IBM 等公司支持。可以认为它是一种 PaaS 模型。
它的设计核心是 MapReduce 实现和 HDFS (Hadoop Distributed File System),它们源自 MapReduce(由一份 Google 文件引入)和 Google File System。
MapReduce 是 Google 引入的一个软件框架,它支持在计算机(即节点)集群上对大型数据集进行分布式计算。它由两个过程组成,映射(Map)和缩减(Reduce)。
在映射过程中,主节点接收输入,把输入分割为更小的子任务,然后把这些子任务分布到工作者节点。
工作者节点处理这些小任务,把结果返回给主节点。
然后,在缩减过程中,主节点把所有子任务的结果组合成输出,这就是原任务的结果。
MapReduce 的优点是它允许对映射和缩减操作进行分布式处理。因为每个映射操作都是独立的,所有映射都可以并行执行,这会减少总计算时间。
对外部客户机而言,HDFS 就像一个传统的分级文件系统。可以创建、删除、移动或重命名文件,等等。但是 HDFS 的架构是基于一组特定的节点构建的,这是由它自身的特点决定的。这些节点包括 NameNode(仅一个),它在 HDFS 内部提供元数据服务;DataNode,它为 HDFS 提供存储块。由于仅存在一个 NameNode,因此这是 HDFS 的一个缺点(单点失败)。
存储在 HDFS 中的文件被分成块,然后将这些块复制到多个计算机中(DataNode)。这与传统的 RAID 架构大不相同。块的大小(通常为 64MB)和复制的块数量在创建文件时由客户机决定。NameNode 可以控制所有文件操作。HDFS 内部的所有通信都基于标准的 TCP/IP 协议。
NameNode 是一个通常在 HDFS 实例中的单独机器上运行的软件。它负责管理文件系统名称空间和控制外部客户机的访问。NameNode 决定是否将文件映射到 DataNode 上的复制块上。对于最常见的 3 个复制块,第一个复制块存储在同一机架的不同节点上,最后一个复制块存储在不同机架的某个节点上。注意,这里需要您了解集群架构。
实际的 I/O 事务并没有经过 NameNode,只有表示 DataNode 和块的文件映射的元数据经过 NameNode。当外部客户机发送请求要求创建文件时,NameNode 会以块标识和该块的第一个副本的 DataNode IP 地址作为响应。这个 NameNode 还会通知其他将要接收该块的副本的 DataNode。
NameNode 在一个称为 FsImage 的文件中存储所有关于文件系统名称空间的信息。这个文件和一个包含所有事务的记录文件(这里是 EditLog)将存储在 NameNode 的本地文件系统上。FsImage 和 EditLog 文件也需要复制副本,以防文件损坏或 NameNode 系统丢失。
Hadoop实战
下面将一步一步演示如何部署一个5节点的集群,并测试一下MapReduce分布式处理的强大功能。
1、应用场景
接下来我们将实际部署一个5节点的集群,并采用MapReduce计算出2个namelist文件中各个名字出现的次数,程序架构设计如下所示。
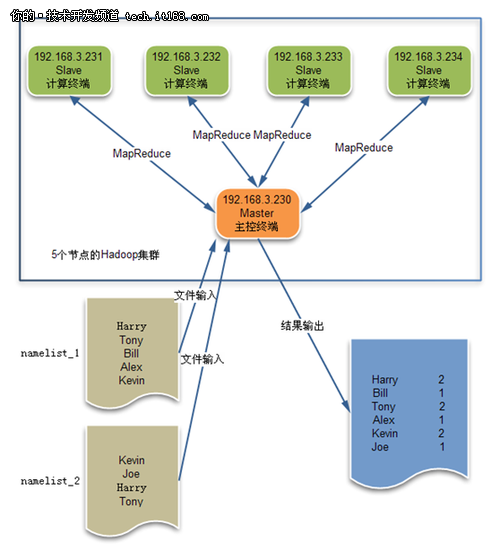
其中NameNode主节点和DataNode从节点的分布情况如下:
NameNode主节点
DataNode从节点
192.168.3.230
192.168.3.231
192.168.3.232
192.168.3.233
192.168.3.234
2、准备集群环境
1)配置ssh无密码登录机器
在 Hadoop 分布式环境中,NameNode主节点需要通过 SSH 来启动和停止DataNode从节点上的各类进程。我们需要保证环境中的各台机器均可以通过SSH 登录访问,并且 Name Node 用 SSH 登录 Data Node 时,不需要输入密码,这样 Name Node 才能在后台自如地控制其它结点。可以将各台机器上的 SSH 配置为使用无密码公钥认证方式来实现。
现在流行的各类 Linux 发行版一般都安装了 SSH 协议的开源实现 OpenSSH, 并且已经启动了 SSH 服务, 即这些机器缺省应该就是支持 SSH 登录的。如果你的机器缺省不支持 SSH, 请下载安装 OpenSSH,以下是配置 SSH 的无密码公钥认证的过程。
首先,在NameNode主节点机器上执行命令,具体如下面的代码所示:
[root@localhost hadoop-0.20.203.0]#ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
Generating public/private dsa key pair.
Your identification has been saved in /root/.ssh/id_dsa.
Your public key has been saved in /root/.ssh/id_dsa.pub.
The key fingerprint is:
09:1b:94:6a:98:35:3c:0b:d6:3f:b1:a5:30:4b:ce:14 root@localhost.localdomain
[root@localhost hadoop-0.20.203.0]#
然后,在NameNode主节点机器上将生成的公钥文件放到/tmp目录下,具体操作如下所示:
[root@localhost hadoop-0.20.203.0]# cp ~/.ssh/id_dsa.pub /tmp
[root@localhost hadoop-0.20.203.0]#
其次,将这个NameNode主节点的公钥文件放到4台DataNode从节点机器的/tmp目录下。
最后,我们在NameNode主节点和DataNode从节点机器上同时执行下面的命令:
[root@localhost tmp]# cat /tmp/id_dsa.pub >> ~/.ssh/authorized_keys
[root@localhost tmp]#
以上都做完了以后,我们就可以用SSH无密码的方式来登录这5台的机器了,可以用如下的方法进行一下简单测试:
[root@localhost tmp]# ssh 192.168.3.230
[root@localhost tmp]# ssh 192.168.3.231
[root@localhost tmp]# ssh 192.168.3.232
[root@localhost tmp]# ssh 192.168.3.233
[root@localhost tmp]# ssh 192.168.3.234
2)安装必须的软件
Hadoop的NameNode主节点,是通过Java程序来跟各DataNode从节点进行通信,并控制它们的,所以我们除了要安装Hadoop的二进制版本之外,我们还需要安装一个JDK来确保Hadoop运行环境的稳定。
首先,我们需要下载Hadoop和Java的安装程序。推荐大家去官网下载,具体怎么样下载不是本文的重点,请大家自行解决。
其次,下载之后我们在NameNode主节点上解压并安装JDK和Hadoop软件,具体操作如下代码所示:
[root@localhost opt]# ll
total 152068
-rw-r--r-- 1 root root 60569605 Aug 15 10:13 hadoop-0.20.203.0rc1.tar.gz
-rw-r--r-- 1 root root 94971634 Aug 15 10:28 jdk-7-linux-x64.tar.gz
[root@localhost opt]#
[root@localhost opt]#tar zxf jdk-7-linux-x64.tar.gz
[root@localhost opt]#tar zxf hadoop-0.20.203.0rc1.tar.gz
[root@localhost opt]# ll
total 152084
drwxr-xr-x 12 root root 4096 May 4 14:30 hadoop-0.20.203.0
-rw-r--r-- 1 root root 60569605 Aug 15 10:13 hadoop-0.20.203.0rc1.tar.gz
drwxr-xr-x 10 500 500 4096 Jun 27 16:51 jdk1.7.0
-rw-r--r-- 1 root root 94971634 Aug 15 10:28 jdk-7-linux-x64.tar.gz
[root@localhost opt]#
之后, 我们在NameNode主节点和DataNode从节点上将java加入到PATH中,只需要在/etc/profile中添加export PATH=/opt/jdk1.7.0/bin:$PATH即可,/opt/jdk1.7.0/bin是Java程序集的路径。
最后,在NameNode主节点和DataNode从节点的机器上,执行”su –“ 刷新一下用户的环境变量,具体如下:
[root@test1 ~]# su -
[root@test1 ~]#
以上工作都完后,说明我们的准备工作都已经完成了,接下来我们将进行到实际的配置集群的阶段了。
3、配置集群
我们用变量$HADOOP_HOME代表Hadoop的主目录,它的值为: $HADOOP_HOME=/opt/hadoop-0.20.203.0。
1)将Java添加到Hadoop运行环境
首先,在NameNode主节点,编辑$HADOOP_HOM /conf/hadoop-env.sh文件,将Java加入到Hadoop的运行环境中,具体如下:
# The java implementation to use. Required.
# export JAVA_HOME=/usr/lib/j2sdk1.5-sun
export JAVA_HOME=/opt/jdk1.7.0
2)配置NameNode主节点信息
其次,在NameNode主节点上,编辑$HADOOP_HOM /conf/core-site.xml文件,添加NameNode主节点的IP和监听端口的相关信息。
[root@localhost hadoop-0.20.203.0]# cat conf/core-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://192.168.3.230:9000</value>
</property>
</configuration>
[root@localhost hadoop-0.20.203.0]#
3)配置数据冗余数量
再次,在NameNode主节点上,编辑$HADOOP_HOM /conf/hdfs-site.xml文件,配置数据冗余的数据的备份数量。
[root@localhost hadoop-0.20.203.0]# cat conf/hdfs-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
[root@localhost hadoop-0.20.203.0]#
4)配置jobtracker信息
然后,在NameNode主节点上,编辑$HADOOP_HOM /conf/mapred-site.xml文件,配置NameNode主节点上的jobtracker服务的端口。
[root@localhost hadoop-0.20.203.0]# cat conf/mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>192.168.3.230:9001</value>
</property>
</configuration>
[root@localhost hadoop-0.20.203.0]#
5)配置master信息
接下来,在NameNode主节点上,编辑$HADOOP_HOM /conf/masters文件,配置主节点的IP信息。
[root@localhost hadoop-0.20.203.0]# cat conf/masters
192.168.3.230
[root@localhost hadoop-0.20.203.0]#
6)配置slave信息
最后,在NameNode主节点上,编辑$HADOOP_HOM /conf/slave文件,配置从节点的IP信息,这个从节点可以有一个,也可以有多个,对于本例有4个slave。
[root@localhost hadoop-0.20.203.0]# cat conf/slaves
192.168.3.231
192.168.3.232
192.168.3.233
192.168.3.234
[root@localhost hadoop-0.20.203.0]#
7)分发Hadoop配置信息
以上操作都做完以后,我们在NameNode主节点上,将JDK和Hadoop软件分发到各DataNode从节点上,并保持安装路径与NameNode主节点相同,就像下面代码演示的一样:
scp -r jdk1.7.0 hadoop-0.20.203.0 192.168.3.231:/opt/
scp -r jdk1.7.0 hadoop-0.20.203.0 192.168.3.232:/opt/
scp -r jdk1.7.0 hadoop-0.20.203.0 192.168.3.233:/opt/
scp -r jdk1.7.0 hadoop-0.20.203.0 192.168.3.234:/opt/
8)格式化分布式文件系统
跟Windows和Linux一样,要想使用HDFS也需要事先格式化,否则文件系统是不可用的,具体方法见下面的代码:
[root@localhost hadoop-0.20.203.0]#bin/hadoop namenode -format
11/08/16 02:38:40 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = localhost.localdomain/127.0.0.1
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 0.20.203.0
……
11/08/16 02:38:40 INFO util.GSet: VM type = 64-bit
11/08/16 02:38:40 INFO namenode.NameNode: Caching file names occuring more than 10 times
11/08/16 02:38:41 INFO common.Storage: Image file of size 110 saved in 0 seconds.
11/08/16 02:38:41 INFO common.Storage: Storage directory /tmp/hadoop-root/dfs/name has been successfully formatted.
11/08/16 02:38:41 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at localhost.localdomain/127.0.0.1
************************************************************/
[root@localhost hadoop-0.20.203.0]#
9)启动Hadoop集群
只需要在NameNode主节点上执行下面的start-all.sh命令即可,同时Master节点可以通过ssh登录到各slave节点去启动其它相关进程。
[root@localhost hadoop-0.20.203.0]#bin/start-all.sh
starting namenode, logging to /opt/hadoop-0.20.203.0/bin/../logs/hadoop-root-namenode-localhost.localdomain.out
192.168.3.232: starting datanode, logging to /opt/hadoop-0.20.203.0/bin/../logs/hadoop-root-datanode-localhost.localdomain.out
192.168.3.233: starting datanode, logging to
……
/opt/hadoop-0.20.203.0/bin/../logs/hadoop-root-jobtracker-localhost.localdomain.out
192.168.3.233: starting tasktracker, logging to
……
[root@localhost hadoop-0.20.203.0]#
10)查看Master和slave进程状态
在NameNode主节点上,查看Java进程情况:
[root@localhost hadoop-0.20.203.0]# jps
867 SecondaryNameNode
735 NameNode
1054 Jps
946 JobTracker
[root@localhost hadoop-0.20.203.0]#
在4台DataNode从节点上,查看Java进程情况:
[root@localhost opt]# jps
30012 TaskTracker
29923 DataNode
30068 Jps
[root@localhost opt]#
各节点上进程都在的话,说明集群部署成功。
4、常见异常的处理
这部分将讲解Hadoop集群配置中最容易犯的错误及解决方案,希望可以让大家尽快的解决问题。
1) Unrecognized option: -jvm
异常现象:
[root@localhost hadoop-0.20.203.0]# bin/start-all.sh
…….
192.168.3.232: Unrecognized option: -jvm
192.168.3.232: Error: Could not create the Java Virtual Machine.
192.168.3.232: Error: A fatal exception has occurred. Program will exit.
…….
解决方案:
需要修改$HADOOP_HOM /bin/hadoop,注释掉这2行:
if [[ $EUID -eq 0 ]]; then
# HADOOP_OPTS="$HADOOP_OPTS -jvm server $HADOOP_DATANODE_OPTS"
# else
HADOOP_OPTS="$HADOOP_OPTS -server $HADOOP_DATANODE_OPTS"
fi
2) Shuffle Error: Exceeded MAX_FAILED_UNIQUE_FETCHES; bailing-out.
异常现象:
11/08/16 03:37:41 INFO mapred.JobClient: map 100% reduce 0%
11/08/16 03:37:58 INFO mapred.JobClient: Task Id : attempt_201108160249_0001_r_000000_0, Status : FAILED
Shuffle Error: Exceeded MAX_FAILED_UNIQUE_FETCHES; bailing-out.
11/08/16 03:37:58 WARN mapred.JobClient: Error reading task outputConnection refused
11/08/16 03:37:58 WARN mapred.JobClient: Error reading task outputConnection refused
11/08/16 03:38:08 INFO mapred.JobClient: map 100% reduce 16%
解决方案:
需要修改2个文件:
vi /etc/security/limits.conf
加上:
* soft nofile 102400
* hard nofile 409600
vi /etc/pam.d/login
加上:
session required /lib/security/pam_limits.so
3) Too many fetch-failures
异常现象:
11/08/16 03:38:28 INFO mapred.JobClient: Task Id : attempt_201108160249_0001_m_000001_0, Status : FAILED
Too many fetch-failures
11/08/16 03:38:28 WARN mapred.JobClient: Error reading task outputConnection refused
11/08/16 03:38:28 WARN mapred.JobClient: Error reading task outputConnection refused
解决方案:
需要在/etc/hosts中添加:
192.168.3.230 test1
192.168.3.231 test2
192.168.3.232 test3
192.168.3.233 test4
192.168.3.234 test5
但做这个之前需要修改集群中所有5台节点的计算机名,即修改/etc/sysconfig/network和/etc/hosts。
5、MapReduce测试
首先,我们在NameNode主节点上准备2个名单文件,希望最终能够统计出2个名单文件中提及到的每个名字的数量,名单文件的内容如下:
[root@localhost hadoop-0.20.203.0]# cat 70_input/namelist_1
Harry
Tony
Bill
Alex
Kevin
[root@localhost hadoop-0.20.203.0]# cat 70_input/namelist_2
Kevin
Joe
Harry
Tony
[root@localhost hadoop-0.20.203.0]#
其次,将这些文件考贝到hadoop文件系统中:
[root@localhost hadoop-0.20.203.0]#bin/hadoop fs -put 70_input input
[root@localhost hadoop-0.20.203.0]# bin/hadoop fs -ls
Found 1 items
drwxr-xr-x - root supergroup 0 2011-08-16 03:35 /user/root/input
[root@localhost hadoop-0.20.203.0]# bin/hadoop fs -ls input
Found 2 items
-rw-r--r-- 2 root supergroup 49 2011-08-16 03:35 /user/root/input/namelist_1
-rw-r--r-- 2 root supergroup 31 2011-08-16 03:35 /user/root/input/namelist_2
[root@localhost hadoop-0.20.203.0]#
再次,我们直接调用系统自带的hadoop-examples-0.20.203.0.jar包中的wordcount程序来统计名字出现的数量:
[root@localhost hadoop-0.20.203.0]#bin/hadoop jar hadoop-examples-0.20.203.0.jar wordcount input output
11/08/16 05:26:31 INFO input.FileInputFormat: Total input paths to process : 2
11/08/16 05:26:32 INFO mapred.JobClient: Running job: job_201108160517_0002
11/08/16 05:26:33 INFO mapred.JobClient: map 0% reduce 0%
11/08/16 05:26:46 INFO mapred.JobClient: map 33% reduce 0%
11/08/16 05:26:47 INFO mapred.JobClient: map 66% reduce 0%
11/08/16 05:26:49 INFO mapred.JobClient: map 100% reduce 0%
11/08/16 05:26:58 INFO mapred.JobClient: map 100% reduce 100%
11/08/16 05:27:03 INFO mapred.JobClient: Job complete: job_201108160517_0002
……
[root@localhost hadoop-0.20.203.0]#
最终,我们查看一下执行结果是否跟我们的期望相符合:
[root@localhost hadoop-0.20.203.0]# bin/hadoop fs -ls output
Found 3 items
-rw-r--r-- 1 root supergroup 0 2011-08-16 05:30 /user/root/output/_SUCCESS
drwxr-xr-x - root supergroup 0 2011-08-16 05:30 /user/root/output/_logs
-rw-r--r-- 1 root supergroup 81 2011-08-16 05:30 /user/root/output/part-r-00000
[root@localhost hadoop-0.20.203.0]#bin/hadoop fs -cat output/part-r-00000
Harry 2
Bill 1
Tony 2
Alex 1
Kevin 2
Joe 1
[root@localhost hadoop-0.20.203.0]#
结果跟我们期望的一样,那么通过本文的学习我们做了第一个Hadoop架构的整体实验,下一步大家可以分两步进行Hadoop学习:第一步,HDFS的运维管理;第二步,MapReduce程序的编写。
- 云计算的利刃:快速部署Hadoop集群
- hadoop集群的部署
- 部署Hadoop集群的步骤
- 安装部署Hadoop集群的方法
- Ganglia监控Hadoop集群的安装部署
- Ganglia监控Hadoop集群的安装部署
- Ganglia监控Hadoop集群的安装部署
- Ganglia监控Hadoop集群的安装部署
- Ganglia监控Hadoop集群的安装部署
- Ganglia监控Hadoop集群的安装部署
- 部署hadoop集群需要配置的文件
- hadoop 三个节点集群的安装部署
- 部署一个伪分布式的Hadoop集群
- 集群上部署hadoop
- hadoop集群部署lzo
- hadoop集群部署
- Hadoop 集群部署介绍
- hadoop集群部署
- Set IDENTITY _INSERTY用法
- ucos OSTimeDly
- 动态类型简介(3)
- windows2003自动识别移动硬盘的解决方法
- Gay+Groupon=GayPon
- 云计算的利刃:快速部署Hadoop集群
- 学习FPGA二 Verilog HDL硬件描述语言
- C# 动态调用WebService
- XML的转义字符
- volatile
- 从贫血领域模型到丰富领域模型
- Iphone代码片段导航
- Javascript鼠标滚轮编程
- 使用DirectX截屏


