算法技巧总结
来源:互联网 发布:淘宝怎么搜烟 编辑:程序博客网 时间:2024/04/23 16:41
1.排序对算法性能的影响
大家都知道排序算法,这个应该不是很难了吧,技巧在于很多时候可以利用排序算法来提供性能,比如:
例1:给定一个数组a[n],求数组中是否存在两个数的和等于给定值sum并输出?
这个问题很常见,解决方法有很多种,这里我就不赘述。这里采用双指针遍历法的。数组不一定有序,我们这里先不假定排序(即里边的数据不是有序的),这时按照常规想法,则用一下循环判断:
如果a[i]+a[j] == sum,显然,这里i的范围是0~n,j的范围也是n~i。每当i++时,j都要从n开始递减,这样没有一点智能的效果,明显会增加循环的次数。但如果我们对数组提前进行排好序呢(提前就有序就最好)?
在数组有序的情况下,分下边的三种情况说明:
如果a[i]+a[j] > sum,说明当前遍历的数值偏大,所以可以把j-1以减小和的值,在继续比较.
如果a[i]+a[j] < sum,说明当前遍历的数值偏小,同样为了加大和可以把i+1。
这时,多了些智能的味道哦,总的时间复杂度取决于排序即O(nlogn)。
2.去其糟粕,留其精华.删减留存相结合
这叫什么意思呢?其实是这样的,我们说当一个问题正面不好回答时,那就从反面排除,最后的那一个当然就是正确的了:
例二:某论坛有一个“水王”,经常发帖,据说该“水王”发帖数目超过了帖子总数的一半,那么如何在id发帖列表中快速的查找到这一“水王”?
这道题如果直接去求这个水王,方法也不少,例如按发帖数对用户ID进行排序排序,但是这至少是O(nlogn)时间复杂度。实际上从反面出发可能会得到更好的结果:尽可能的去减少解空间,把不可能的去除掉,留下的自然是要求的的解。
分析如下: 每次去除两个不同ID的发帖,由于默认水王发帖超过一半,那么去除任何两个不同ID后仍然是超过一半的,可能会问为什么?可以这样想,开始满足的公式是 x>y/2(x代表水王ID在列表中存在的总数,y代表所有ID的条目数),那么减去两个不同ID后,最坏情况,这两个不同ID中有一个是水王的ID,所以就有(x-1)/(y-2) > (y/2-1)/(y-2) > 1/2,即仍然是大于二分之一的, 所以可以不断的这样做直到最终剩下水王ID为止。
实际上这类思想的应用场景可以认为如果看到要求的东西占总体数量一半以上情况的时候,可以考虑排除法。当然还有其他情况,例如正面求解屡试不行的时候,也可以考虑这样的方法。
3.经典的公平以小胜大法
我自己是常遇见这样的一个问题,比如:
例三:给你一个n个长度的链表,以及一个函数,这个函数50%的概率返回0,50%的概率则返回1,问如何用这些条件从这n个链表中随机的抽取k个节点。注意这里的n不知道具体的大小哦,也可能很大。
好吧,也许你说你没见过这样的题,那么我们先把问题类比化处理:在不知道文件总行数的情况下,如何从文件中随机的抽取一行。还是不懂?好吧,再次处理:假设文件为固定n行,随机从中取出一行,这时好做了吧,用C的rand()就可以了,可问题是我们的n不是固定的行。固定的好处就在于让每次取出行的概率对所有行是相等的。当n不固定的时候,概率1/n就不固定,也不相等。那么怎么办呢?
这里提到蓄水池抽样模型,用这个模型重新考虑这个问题:定义取出的行号为choice,第一次直接以第一行作为取出行 choice ,而后第二次以二分之一概率决定是否用第二行替换 choice ,第三次以三分之一的概率决定是否以第三行替换 choice ……,以此类推。这种方法的巧妙之处在于成功的构造出了一种方式使得最后可以证明对每一行的取出概率都为1/n(其中n为当前扫描到的文件行数),换句话说对每一行取出的概率均相等,也即完成了随机的选取。我们现在用数学归纳法证明刚才的等概率性如下:
(1)当有k=1行,此时第一行被选中的概率为1/1=1;
(2)假设当有k=i行时,此时a行最后被选中的概率是1/i成立。那么当有k=i+1行时,这时a行最后被选中的概率是它在前边i行中被选中的概率*后面都没有被替换的概率,我们知道替换的概率是1/(i+1),那么不被替换的概率就是i/(i+1),所以:
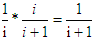
(3)由k=1,k=i,k=i+1成立可知,对于任意k都有命题成立。
好了,现在我们将问题推广:如何从未知或者很大样本空间随机地取k个数。类比下即可得到答案,即先把前k个数放入蓄水池,把这k都当成要选的,对第k+1个,我们以k/(k+1)概率决定是否要把它换入蓄水池,换入时随机的选取一个作为替换项,这样一直做下去,对于任意的样本空间n,对每个数的选取概率都为k/n。也就是说对每个数选取概率相等。这时计算时,任何一个元素a被选中的概率等于它被选中的概率*[它后面元素b没有被选中的概率+它后边元素b被选中(即在后面被选中)*但没有替换a的概率].
最后回到开始的问题,利用蓄水池抽样思想,先指定前k个节点为所求,并把指针指向第k+1个节点,此时以k/(k+1)决定是否与前k个等概率随机选定的一个节点进行替换,替换时随机选,并以此类推直至结尾。最后剩余的节点即为所求。
- 算法技巧总结
- 算法小技巧总结
- 《程序算法与技巧精选》总结
- 链表算法题技巧总结
- AVL 树插入算法记忆技巧总结
- 数据结构总结1-算法设计技巧
- Python 学习 (Leetcode 算法题解【easy部分 技巧总结】)
- 蓝桥杯C_C++/Java程序设计常用算法&技巧总结
- 算法技巧
- 算法技巧
- 技巧总结
- 技巧总结
- 【算法复习三】算法设计技巧与优化----各种背包问题总结
- 【算法】算法设计技巧
- RMQ 之 ST算法的使用 【总结】 【附带求固定区间长度的一维技巧】
- 各类算法技巧核心代码,知识点归纳总结之单调递增子序列
- 各类算法技巧核心代码,知识点归纳总结之最长公共子序列
- 与位运算相关的编程算法技巧的总结java实现
- android-仿美丽说具有按下效果的顶部导航栏
- IOS多线程读写Sqlite问题解决
- Android控件Gallery3D效果
- rpm的用法
- Eclipse下配置使用glib库的方法【linux版本】
- 算法技巧总结
- 微信高仿导航页开门效果(送上源码)
- 网络设备驱动 和 DM9000 驱动程序分析
- find用法
- MySQL dbcp 下连接空闲8小时自动断开问题解决方案
- 在c# / ASP.net中获取当前日期
- DataSet数据集
- 15、backbone实战:webchat(四)server端开发
- javascript面向对象编程


