Hadoop概述
来源:互联网 发布:ios7cydia网络错误 编辑:程序博客网 时间:2024/04/20 06:47
hadoop是什么:Hadoop是一个开发和运行处理大规模数据的软件平台,是Appach的一个用
java语言实现开源软件框架,实现在大量计算机组成的集群中对海量数据进行分布式计算.
Hadoop框架中最核心设计就是:HDFS和MapReduce.HDFS提供了海量数据的存储,
MapReduce提供了对数据的计算.
大文件被分成默认64M一块的数据块分布存储在集群机器中.
结果以key--value的形式输出,hadoop负责按key值将map的输出整理后作为Reduce的输入,
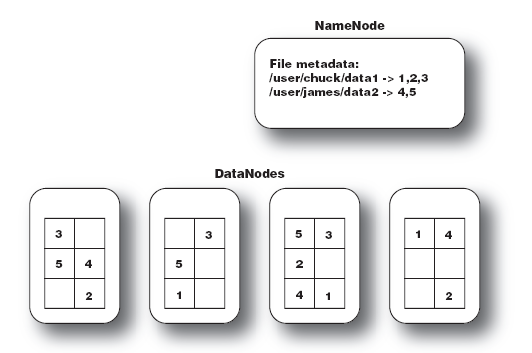
NameNode同时保存了文件系统运行的状态信息.
DataNode中存储的是被拆分的blocks.
Secondary NameNode帮助NameNode收集文件系统运行的状态信息.
JobTracker当有任务提交到Hadoop集群的时候负责Job的运行,负责调度多个TaskTracker.
TaskTracker负责某一个map或者reduce任务.
java语言实现开源软件框架,实现在大量计算机组成的集群中对海量数据进行分布式计算.
Hadoop框架中最核心设计就是:HDFS和MapReduce.HDFS提供了海量数据的存储,
MapReduce提供了对数据的计算.
数据在hadoop中处理的流程可以简单的按照下图来理解:数据通过Haddop的集群处理后得到结果.
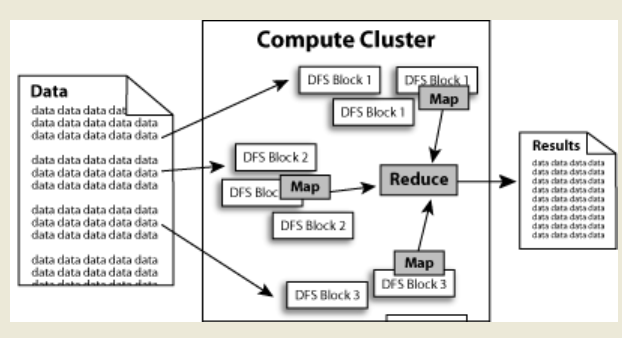
大文件被分成默认64M一块的数据块分布存储在集群机器中.
如下图中的文件 data1被分成3块,这3块以冗余镜像的方式分布在不同的机器中.
结果以key--value的形式输出,hadoop负责按key值将map的输出整理后作为Reduce的输入,
Reduce Task的输出为整个job的输出,保存在HDFS上.
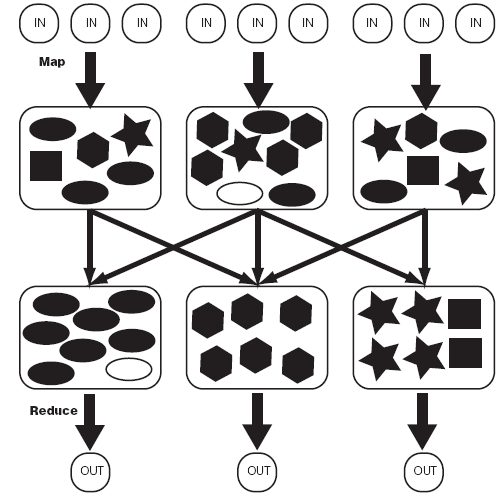
如下图所示:
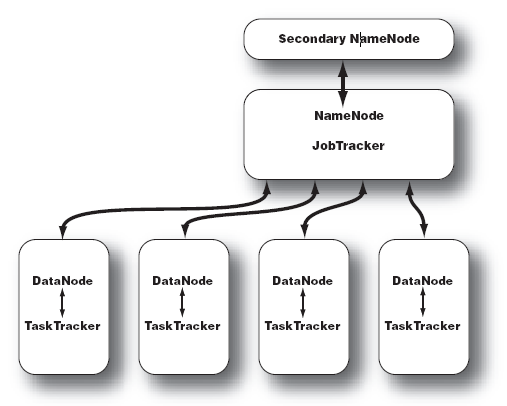
NameNode同时保存了文件系统运行的状态信息.
DataNode中存储的是被拆分的blocks.
Secondary NameNode帮助NameNode收集文件系统运行的状态信息.
JobTracker当有任务提交到Hadoop集群的时候负责Job的运行,负责调度多个TaskTracker.
TaskTracker负责某一个map或者reduce任务.
- Hadoop概述
- Hadoop概述
- Hadoop概述
- hadoop概述
- hadoop概述
- Hadoop概述
- Hadoop概述
- Hadoop概述
- hadoop概述
- Hadoop概述
- hadoop---概述
- Hadoop概述
- Hadoop概述
- Hadoop概述
- Hadoop概述
- Hadoop小结连载:Hadoop概述
- Hadoop实战之一~Hadoop概述
- Hadoop实战之一~Hadoop概述
- OLE Drop Target
- ext.net d动态添加GridPanel到window中
- c#数据结构
- linux内核分析笔记----进程地址空间
- Oracle学习笔记点滴
- Hadoop概述
- Linux 逻辑卷管理 与 文件系统(LVM 与 FileSystem)的关系
- 设置组件为圆角的方法
- 2012半程盘点之最佳新酷炫科技产品
- 收藏的网址
- android环境抓Wireshark码流数据包,shell命令操作
- Lex & Yacc 语法树应用
- linux c/c++ 自己安装libevent在虚拟机上的linux系统里
- linux内核多点触摸文档 mtdev工程介绍


