【deep learning学习笔记】Autoencoder
来源:互联网 发布:linux vim 保存 编辑:程序博客网 时间:2024/04/25 15:06
继续学习deep learning,看yusugomori的code,看到里面DA(Denoising Autoencoders)和SDA(Stacked Denoising Autoencoders)的code,与RBM非常像。心里有个问题,autoencoder和RBM有什么区别和联系?又上网上找了些资料(前面转载那两篇),学习了一下。下面记一下笔记。
1. autoencoder是多层神经网络,其中输入层和输出层表示相同的含义,具有相同的节点数,如图:
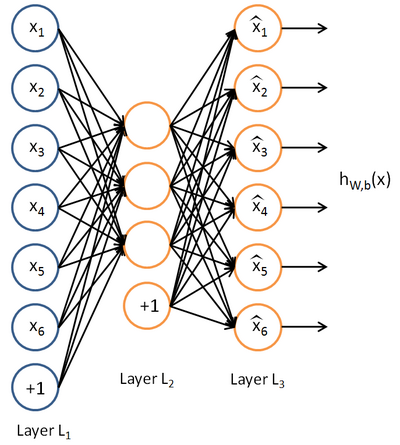
2. 从1中可以看到,autoencoder学习的还是输入的特征表示。
3. 不过输入和输出相同,使得这个网络的输出没有任何意义。autoencoder的意义在于学习的(通常是节点数更少的)中间coder层(最中间的那一层),这一层是输入向量的良好表示。这个过程起到了“降维”的作用。
4. 当autoencoder只有一个隐含层的时候,其原理相当于主成分分析(PCA)
5. 当autoencoder有多个隐含层的时候,每两层之间可以用RBM来pre-training,最后由BP来调整最终权值
6. 网络权重更新公式很容易用求偏导数的方法推导出来,算法是梯度下降法。
7. denoising autoencoder是autoencoder的一个变种,与autoencoder不同的是,denoising autoencoder在输入的过程中加入了噪声信息,从而让autoencoder能够学习这种噪声。
8. denoising autoencoder与RBM非常像:
(1)参数一样:隐含层偏置、显示层偏置、网络权重
(2)作用一样:都是输入的另一种(压缩)表示
(3)过程类似:都有reconstruct,并且都是reconstruct与input的差别,越小越好
9. denoising autoencoder与RBM的区别:
背后原理就不说了哈(RBM是能量函数),区别在于训练准则。RBM是隐含层“产生”显示层的概率(通常用log表示),denoising autoencoder是输入分布与reconstruct分布的KL距离。所用的训练方法,前者是CD-k,后者是梯度下降。
10. 再补充一下,RBM固定只有两层;autoencoder,可以有多层,并且这些多层网络可以由标准的bp算法来更新网络权重和偏置,与标准神经网络不同的是,autoencoder的输入层和最终的输出层是“同一层”,不仅仅是节点数目、输出相同,而是完完全全的“同一层”,这也会影响到这一层相关的权值更新方式。总之,输入与输出是同一层,在此基础上,再由输入与输出的差别构造准则函数,再求各个参数的偏导数,再用bp方式更新各个权重......
- 【deep learning学习笔记】Autoencoder
- Deep Learning 学习笔记1--AutoEncoder
- Deep Learning的学习实践 3 -- AutoEncoder
- Deep learning:(Sparse Autoencoder)
- 【Deep Learning】1、AutoEncoder
- Deep Learning(深度学习)学习笔记整理系列之(四) --AutoEncoder自动编码器
- Deep Learning(深度学习)学习笔记整理系列之(六)AutoEncoder自动编码器
- Deep learning:(Sparse Autoencoder练习)
- Deep learning:八【sparse autoencoder】
- Deep learning:八(Sparse Autoencoder)
- Deep learning:八(Sparse Autoencoder)
- Deep learning:八(Sparse Autoencoder)
- Deep Learning:Sparse Autoencoder练习
- Deep learning:八(Sparse Autoencoder)
- deep learning 学习笔记
- Deep Learning 学习笔记
- Deep Learning 学习笔记
- Deep Learning(学习笔记)
- Android 修改Bitmap 图片像素的信息 R G B 颜色值 详解
- NBUT1482:嘛~付钱吧!(完全背包)
- my97 WdatePicker 使用大全
- Linux根文件系统结构再认识
- poj 1847
- 【deep learning学习笔记】Autoencoder
- Diskless / remote boot with Open-iSCSI
- JS中 prototype 关键字的使用
- jsp servlet 乱码
- Combination Sum
- poj 2585 Window Pains (建图+拓扑排序)
- 为MediaPlayer设置监听器
- POJ2485 最短路的水题
- “SQ3R”+“知识管理五步骤”定制适合我自己的知识力提升法


