sqlite 视图、触发器、索引和事务总结
来源:互联网 发布:网站域名一年多少钱 编辑:程序博客网 时间:2024/04/25 13:03
一 视图
视图即虚拟表,它的内容都是派生自其他表的查询结果,虽然看起来像基本表,但不是基本表,因为视图的内容是动态生成的。
视图的用处是将频繁使用的复杂的查询放进一个虚拟表,方便查询。
- 创建视图
creat view name as select-stmt;
1). 最简单的视图:
sqlite> CREATE VIEW testview AS SELECT * FROM testtable WHERE first_col > 100;
2). 创建临时视图:
sqlite> CREATE TEMP VIEW tempview AS SELECT * FROM testtable WHERE first_col > 100;
3). "IF NOT EXISTS"从句:
sqlite> CREATE VIEW testview AS SELECT * FROM testtable WHERE first_col > 100;
Error: table testview already exists
sqlite> CREATE VIEW IF NOT EXISTS testview AS SELECT * FROM testtable WHERE first_col > 100;
- 删除视图
sqlite> DROP VIEW testview;
sqlite> DROP VIEW testview;
Error: no such view: testview;
sqlite> DROP VIEW IF EXISTS testview;
创建一个关系复杂的视图:
creat view details as
select f.name as fd, ft.name as tp, e.name as ep, e.season as ssn
from foods f
inner join food_types ft on f.type_id=ft.id,
inner join foods_episodes fe on f.id=fe.ffod_id,
inner join episodes e on fe.episode_id=e.id;
注意:sqlite目前不支持可更新的视图,即只允许select操作,insert 和update操作不行
不过可以借助触发器实现更新
二 触发器
当具体的表发生特定的数据库事件时,触发器执行对应的SQL指令。触发器可以用来创建自定义完整性约束、日志改变、更新表和其他操作。
- 创建触发器
creat [temp|temporary] trigger name
[before|after] [insert|update|delete of columns] on table
begin
SQL语句
end;
- new old
sqlite提供对表中已经更新和更新前的行的访问 。如new.id old.id - 冲突解决
replace
ignore
faile
abort
rollback - raise()函数
一个特殊的SQL函数RAISE()可用于触发器程序,使用如下语法:
raise-function ::= RAISE ( ABORT, error-message ) |
RAISE ( FAIL, error-message ) |
RAISE ( ROLLBACK, error-message ) |
RAISE ( IGNORE )
当触发器程序执行中调用了上述前三个之一的形式时,则执行指定的ON CONFLICT进程(ABORT, FAIL或者ROLLBACK) 且终止当前查询,返回一个SQLITE_CONSTRAINT错误并说明错误信息。
当调用RAISE(IGNORE),当前触发器程序的余下部分,触发该触发器的语句和任何之后的触发器程序被忽略并且 不恢复对数据库的已有改变。 若触发触发器的语句是一个触发器程序本身的一部分,则原触发器程序从下一步起继续执行。
一个例子:参考:http://blog.csdn.net/lzq_it/article/details/6960176
--创建班级表
create table class
(
id integer primary key autoincrement, --班级编号
className text --班级名称
);
--创建学生表
create table student
(
id integer primary key autoincrement, --编号
stuName text, --学生名称
stuSex btext, --性别
stuAge integer , --年龄
classId --班级编号
);
--创建插入触发器 (创建学生时要触发插入触发器去判断是否存在该班级,存在插入成功,反之插入失败)
create trigger fk_Insert
before insert on student
for each row
begin
select raise(rollback,'还没有该班级')
where (select id from class where id = new.classId ) is null;
end;
--创建更新触发器 (更新学生时要触发更新触发器去判断是否存在更新班级,存在更新成功,反之更新失败)
create trigger fk_Update
before update on student
for each row
begin
select raise(rollback,'还没有该班级')
where (select id from class where id = new.classId)is null;
end;
--创建删除触发器 (删除班级时,首先根据班级编号删除该班级学生)
create trigger fk_Delete
before delete on class
for each row
begin
delete from student where classId = old.classId;
end ;
insert into class(className) values('s1t64');
insert into student(stuName,stuSex,stuAge,classId)values('zhangsan',1,23,1);
update student set stuName='lishi',classId=1 where id = 1;
select * from class ;
select * from student limit 0,100 ; -- 分页查询从索引0开始查找,100条数据
三 索引
索引是一种用来在某种条件下加速查询的结构。SQLite使用B-树做索引。索引会增加数据库的大小,索引使用使用首先要考虑什么时候使用索引,要不要使用索引。
- 创建索引:
creat index [unique] index_name on table_name[columns]
可以对字段进行约束,如collate nocase ,unique等
- 使用索引:
在单字段索引的情况下,对于下面的where子句中出现的表达式,SQLite将使用索引:
column {=|<|>|<=|>=} expression
expression {=|<|>|<=|>=} column
column in (expression_list)
column in (subquery) //子查询
多字段索引有更复杂的情况
creat table foo (a, b, c, d);
creat index foo_index on foo(a, b, c, d)
foo_index 字段的顺序是从左往右的,在查询select * from foo where a=1 and b=2 and d=3;只有前两个条件使用索引,因为没有有效条件来缩小c到d的d 差距
所以,多字段索引时,查询时从左往右使用字段索引的,直到where子句无法找出有效条件来继续进行索引。
Sqlite数据库中索引的使用、索引的优缺点,参考http://www.cr173.com/html/17298_1.html
要使用索引对数据库的数据操作进行优化,那必须明确几个问题:
1.什么是索引
2.索引的原理
3.索引的优缺点
4.什么时候需要使用索引,如何使用
围绕这几个问题,来探究索引在数据库操作中所起到的作用。
1.数据库索引简介
回忆一下小时候查字典的步骤,索引和字典目录的概念是一致的。字典目录可以让我们不用翻整本字典就找到我们需要的内容页数,然后翻到那一页就可以。索引也是一样,索引是对记录按照多个字段进行排序的一种展现。对表中的某个字段建立索引会创建另一种数据结构,其中保存着字段的值,每个值还包括指向与它相关记录的指针。这样,就不必要查询整个数据库,自然提升了查询效率。同时,索引的数据结构是经过排序的,因而可以对其执行二分查找,那就更快了。
2. B-树与索引
大多数的数据库都是以B-树或者B+树作为存储结构的,B树索引也是最常见的索引。先简单介绍下B-树,可以增强对索引的理解。
B-树是为磁盘设计的一种多叉平衡树,B树的真正最准确的定义为:一棵含有t(t>=2)个关键字的平衡多路查找树。一棵M阶的B树满足以下条件:
1)每个结点至多有M个孩子;
2)除根结点和叶结点外,其它每个结点至少有M/2个孩子;
3)根结点至少有两个孩子(除非该树仅包含一个结点);
4)所有叶结点在同一层,叶结点不包含任何关键字信息,可以看作一种外部节点;
5)有K个关键字的非叶结点恰好包含K+1个孩子;
B树中的每个结点根据实际情况可以包含大量的关键字信息和分支(当然是不能超过磁盘块的大小,根据磁盘驱动(disk drives)的不同,一般块的大小在1k~4k左右);这样树的深度降低了,这就意味着查找一个元素只要很少结点从外存磁盘中读入内存,很快访问到要查找的数据。B-树上操作的时间通常由存取磁盘的时间和CPU计算时间这两部分构成。而相对于磁盘的io速度,cpu的计算时间可以忽略不计,所以B树的意义就显现出来了,树的深度降低,而深度决定了io的读写次数。
B树索引是一个典型的树结构,其包含的组件主要是:
1)叶子节点(Leaf node):包含条目直接指向表里的数据行。
2)分支节点(Branch node):包含的条目指向索引里其他的分支节点或者是叶子节点。
3) 根节点(Root node):一个B树索引只有一个根节点,它实际就是位于树的最顶端的分支节点。
如下图所示: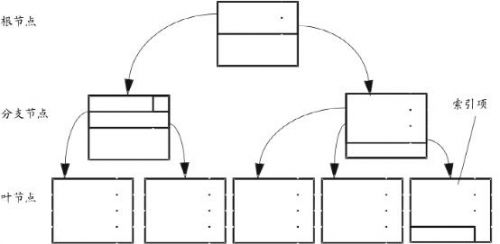
每个索引都包含两部分内容,一部分是索引本身的值,第二部分即指向数据页或者另一个索引也的指针。每个节点即为一个索引页,包含了多个索引。
当你为一个空表建立一个索引,数据库会分配一个空的索引页,这个索引页即代表根节点,在你插入数据之前,这个索引页都是空的。每当你插入数据,数据库就会在根节点创建索引条目,。当根节点插满的时候,再插入数据时,根节点就会分裂。举个例子,根节点插入了如图所示的数据。(超过4个就分裂),这时候插入H,就会分裂成2个节点,移动G到新的根节点,把H和N放在新的右孩子节点中。如图所示:

根节点插满4个节点

插入H,进行分裂。
大致的分裂步骤如下:
1)创建两个儿子节点
2)将原节点中的数据近似分为两半,写入两个新的孩子节点中。
3)在跟节点中放置指向页节点的指针
当你不断向表中插入数据,根节点中指向叶节点的指针也被插满,当叶子还需要分裂的时候,根节点没有空间再创建指向新的叶节点的指针。那么数据库就会创建分支节点。随着叶子节点的分裂,根节点中的指针都指向了这些分支节点。随着数据的不断插入,索引会增加更多的分支节点,使树结构变成这样的一个多级结构。
3. 索引的种类
1)聚集索引:表中行的物理顺序与键值的逻辑(索引)顺序相同。因为数据的物理顺序只能有一种,所以一张表只能有一个聚集索引。如果一张表没有聚集索引,那么这张表就没有顺序的概念,所有的新行都会插入到表的末尾。对于聚集索引,叶节点即存储了数据行,不再有单独的数据页。就比如说我小时候查字典从来不看目录,我觉得字典本身就是一个目录,比如查裴字,只需要翻到p字母开头的,再按顺序找到e。通过这个方法我每次都能最快的查到老师说的那个字,得到老师的表扬。
2)非聚集索引:表中行的物理顺序与索引顺序无关。对于非聚集索引,叶节点存储了索引字段值以及指向相应数据页的指针。叶节点紧邻在数据之上,对数据页的每一行都有相应的索引行与之对应。有时候查字典,我并不知道这个字读什么,那我就不得不通过字典目录的“部首”来查找了。这时候我会发现,目录中的排序和实际正文的排序是不一样的,这对我来说很苦恼,因为我不能比别人快了,我需要先再目录中找到这个字,再根据页数去找到正文中的字。
4.索引与数据的查询,插入与删除
1)查询。查询操作就和查字典是一样的。当我们去查找指定记录时,数据库会先查找根节点,将待查数据与根节点的数据进行比较,再通过根节点的指针查询下一个记录,直到找到这个记录。这是一个简单的平衡树的二分搜索的过程,我就不赘述了。在聚集索引中,找到页节点即找到了数据行,而在非聚集索引中,我们还需要再去读取数据页。
2)插入。聚集索引的插入操作比较复杂,最简单的情况,插入操作会找到对于的数据页,然后为新数据腾出空间,执行插入操作。如果该数据页已经没有空间,那就需要拆分数据页,这是一个非常耗费资源的操作。对于仅有非聚集索引的表,插入只需在表的末尾插入即可。如果也包含了聚集索引,那么也会执行聚集索引需要的插入操作。
3)删除。删除行后下方的数据会向上移动以填补空缺。如果删除的数据是该数据页的最后一行,那么这个数据页会被回收,它的前后一页的指针会被改变,被回收的数据页也会在特定的情况被重新使用。与此同时,对于聚集索引,如果索引页只剩一条记录,那么该记录可能会移动到邻近的索引表中,原来的索引页也会被回收。而非聚集索引没办法做到这一点,这就会导致出现多个数据页都只有少量数据的情况。
5. 索引的优缺点
其实通过前面的介绍,索引的优缺点已经一目了然。
先说优点:
1)大大加快数据的检索速度,这也是创建索引的最主要的原因
2)加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
3)在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间。
再说缺点:
1)创建索引需要耗费一定的时间,但是问题不大,一般索引只要build一次
2)索引需要占用物理空间,特别是聚集索引,需要较大的空间
3)当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,降低了数据的维护速度,这个是比较大的问题。
6.索引的使用
根据上文的分析,我们大致对什么时候使用索引有了自己的想法(如果你没有,回头再看一遍。。。)。一般我们需要在这些列上建立索引:
1)在经常需要搜索的列上,这是毋庸置疑的;
2)经常同时对多列进行查询,且每列都含有重复值可以建立组合索引,组合索引尽量要使常用查询形成索引覆盖(查询中包含的所需字段皆包含于一个索引中,我们只需要搜索索引页即可完成查询)。 同时,该组合索引的前导列一定要是使用最频繁的列。对于前导列的问题,在后面sqlite的索引使用介绍中还会做讨论。
3)在经常用在连接的列上,这些列主要是一些外键,可以加快连接的速度,连接条件要充分考虑带有索引的表。;
4)在经常需要对范围进行搜索的列上创建索引,因为索引已经排序,其指定的范围是连续的,同样,在经常需要排序的列上最好也创建索引。
6)在经常放到where子句中的列上面创建索引,加快条件的判断速度。要注意的是where字句中对列的任何操作(如计算表达式,函数)都需要对表进行整表搜索,而没有使用该列的索引。所以查询时尽量把操作移到等号右边。
对于以下的列我们不应该创建索引:
1)很少在查询中使用的列
2)含有很少非重复数据值的列,比如只有0,1,这时候扫描整表通常会更有效
3)对于定义为TEXT,IMAGE的数据不应该创建索引。这些字段长度不固定,或许很长,或许为空。
当然,对于更新操作远大于查询操作时,不建立索引。也可以考虑在大规模的更新操作前drop索引,之后重新创建,不过这就需要把创建索引对资源的消耗考虑在内。总之,使用索引需要平衡投入与产出,找到一个产出最好的点。
7. 在sqlite中使用索引
1)Sqlite不支持聚集索引,android默认需要一个_id字段,这保证了你插入的数据会按“_id”的整数顺序插入,这个integer类型的主键就会扮演和聚集索引一样的角色。所以不要再在对于声明为:INTEGER PRIMARY KEY的主键上创建索引。
2)很多对索引不熟悉的朋友在表中创建了索引,却发现没有生效,其实这大多数和我接下来讲的有关。对于where子句中出现的列要想索引生效,会有一些限制,这就和前导列有关。所谓前导列,就是在创建复合索引语句的第一列或者连续的多列。比如通过:CREATE INDEX comp_ind ON table1(x, y, z)创建索引,那么x,xy,xyz都是前导列,而yz,y,z这样的就不是。下面讲的这些,对于其他数据库或许会有一些小的差别,这里以sqlite为标准。在where子句中,前导列必须使用等于或者in操作,最右边的列可以使用不等式,这样索引才可以完全生效。同时,where子句中的列不需要全建立了索引,但是必须保证建立索引的列之间没有间隙。举几个例子来看吧:
用如下语句创建索引:
CREATE INDEX idx_ex1 ON ex1(a,b,c,d,e,...,y,z);
这里是一个查询语句:
...WHERE a=5 AND b IN (1,2,3) AND c IS NULL AND d='hello'
这显然对于abcd四列都是有效的,因为只有等于和in操作,并且是前导列。
再看一个查询语句:
... WHERE a=5 AND b IN (1,2,3) AND c>12 AND d='hello'
那这里只有a,b和c的索引会是有效的,d列的索引会失效,因为它在c列的右边,而c列使用了不等式,根据使用不等式的限制,c列已经属于最右边。
最后再看一条:
... WHERE b IN (1,2,3) AND c NOT NULL AND d='hello'
索引将不会被使用,因为没有使用前导列,这个查询会是一个全表查询。
3)对于between,or,like,都无法使用索引。
如 ...WHERE myfield BETWEEN 10 and 20;
这时就应该将其转换成:
...WHERE myfield >= 10 AND myfield <= 20;
再如LIKE:...mytable WHERE myfield LIKE 'sql%';;
此时应该将它转换成:
...WHERE myfield >= 'sql' AND myfield < 'sqm';
再如OR:...WHERE myfield = 'abc' OR myfield = 'xyz';
此时应该将它转换成:
...WHERE myfield IN ('abc', 'xyz');
其实除了索引,对查询性能的影响因素还有很多,比如表的连接,是否排序等。影响数据库操作的整体性能就需要考虑更多因素,使用更对的技巧,不得不说这是一个很大的学问。
最后在android上使用sqlite写一个简单的例子,看下索引对数据库操作的影响。
创建如下表和索引:
db.execSQL("create table if not exists t1(a,b)");
db.execSQL("create index if not exists ia on t1(a,b)");
插入10万条数据,分别对表进行如下操作:
select * from t1 where a='90012'
插入:insert into t1(a,b) values('10008','name1.6982235534984673')
更新:update t1 set b='name1.999999' where a = '887'
删除:delete from t1 where a = '1010'
数据如下(5次不同的操作取平均值):
操作 无索引 有索引
查询 170ms 5ms
插入 65ms 75ms
更新 240ms 52ms
删除 234ms 78ms
可以看到显著提升了查询的速度,稍稍减慢了插入速度,还稍稍提升了更新数据和删除数据的速度。如果把更新和删除中的where子句中的列换成b,速度就和没有索引一样了,因为索引失效。所以索引能大幅度提升查询速度,对于删除和更新操作,如果where子句中的列使用了索引,即使需要重新build索引,有可能速度还是比不使用索引要快的。对与插入操作,索引显然是个负担。同时,索引让db的大小增加了2倍多。
还有个要吐槽的是,android中的rawQurey方法,执行完sql语句后返回一个cursor,其实并没有完成一个查询操作,我在rawquery之前和之后计算查询时间,永远是1ms...这让我无比苦闷。看了下源码,在对cursor调用moveToNext这些移动游标方法时,都会最终先调用getCount方法,而getCount方法才会调用native方法调用真正的查询操作。这种设计显然更加合理。
四 事务和锁
sqlite的事务和锁
事务
事务定义了一组SQL命令的边界,这组命令或者作为一个整体被全部执行,或者都不执行。事务的典型实例是转帐。
事务的范围
事务由3个命令控制:BEGIN、COMMIT和ROLLBACK。BEGIN开始一个事务,之后的所有操作都可以取消。COMMIT使BEGIN后的所有命令得到确认;而ROLLBACK还原BEGIN之后的所有操作。如:
sqlite> BEGIN;
sqlite> DELETE FROM foods;
sqlite> ROLLBACK;
sqlite> SELECT COUNT(*) FROM foods;
COUNT(*)
412
上面开始了一个事务,先删除了foods表的所有行,但是又用ROLLBACK进行了回卷。再执行SELECT时发现表中没发生任何改变。
SQLite默认情况下,每条SQL语句自成事务(自动提交模式)。
冲突解决
如前所述,违反约束会导致事务的非法结束。大多数数据库(管理系统)都是简单地将前面所做的修改全部取消。
SQLite有其独特的方法来处理约束违反(或说从约束违反中恢复),被称为冲突解决。
如:
sqlite> UPDATE foods SET id=800-id;
SQL error: PRIMARY KEY must be unique
SQLite提供5种冲突解决方案:REPLACE、IGNORE、FAIL、ABORT和ROLLBACK。
REPLACE: 当违反了唯一完整性,SQLite将造成这种违反的记录删除,替代以新插入或修改的新记录,SQL继续执行,不报错。
IGNORE
FAIL
ABORT
ROLLBACK
数据库锁
在SQLite中,锁和事务是紧密联系的。为了有效地使用事务,需要了解一些关于如何加锁的知识。
SQLite采用粗放型的锁。当一个连接要写数据库,所有其它的连接被锁住,直到写连接结束了它的事务。SQLite有一个加锁表,来帮助不同的写数据库都能够在最后一刻再加锁,以保证最大的并发性。
SQLite使用锁逐步上升机制,为了写数据库,连接需要逐级地获得排它锁。SQLite有5个不同的锁状态:未加锁(UNLOCKED)、共享 (SHARED)、保留(RESERVED)、未决(PENDING)和排它(EXCLUSIVE)。每个数据库连接在同一时刻只能处于其中一个状态。每 种状态(未加锁状态除外)都有一种锁与之对应。
最初的状态是未加锁状态,在此状态下,连接还没有存取数据库。当连接到了一个数据库,甚至已经用BEGIN开始了一个事务时,连接都还处于未加锁状态。
未加锁状态的下一个状态是共享状态。为了能够从数据库中读(不写)数据,连接必须首先进入共享状态,也就是说首先要获得一个共享锁。多个连接可以 同时获得并保持共享锁,也就是说多个连接可以同时从同一个数据库中读数据。但哪怕只有一个共享锁还没有释放,也不允许任何连接写数据库。
如果一个连接想要写数据库,它必须首先获得一个保留锁。一个数据库上同时只能有一个保留锁。保留锁可以与共享锁共存,保留锁是写数据库的第1阶段。保留锁即不阻止其它拥有共享锁的连接继续读数据库,也不阻止其它连接获得新的共享锁。
一旦一个连接获得了保留锁,它就可以开始处理数据库修改操作了,尽管这些修改只能在缓冲区中进行,而不是实际地写到磁盘。对读出内容所做的修改保存在内存缓冲区中。
当连接想要提交修改(或事务)时,需要将保留锁提升为排它锁。为了得到排它锁,还必须首先将保留锁提升为未决锁。获得未决锁之后,其它连接就不能 再获得新的共享锁了,但已经拥有共享锁的连接仍然可以继续正常读数据库。此时,拥有未决锁的连接等待其它拥有共享锁的连接完成工作并释放其共享锁。
一旦所有其它共享锁都被释放,拥有未决锁的连接就可以将其锁提升至排它锁,此时就可以自由地对数据库进行修改了。所有以前对缓冲区所做的修改都会被写到数据库文件。
死锁
为什么需要了解锁的机制呢?为了避免死锁。
考虑下面表4-7所假设的情况。两个连接——A和B——同时但完全独立地工作于同一个数据库。A执行第1条命令,B执行第2、3条,等等。
表4-7 一个死锁的假设情况
A连接 B连接
sqlite> BEGIN;
sqlite> BEGIN;
sqlite> INSERT INTO foo VALUES('x');
sqlite> SELECT * FROM foo;
sqlite> COMMIT;
SQL error: database is locked
sqlite> INSERT INTO foo VALUES ('x');
SQL error: database is locked
两个连接都在死锁中结束。B首先尝试写数据库,也就拥有了一个未决锁。A再试图写,但当其INSERT语句试图将共享锁提升为保留锁时失败。
为了讨论的方便,假设连接A和B都一直等待数据库可写。那么此时,其它的连接甚至都不能够再读数据库了,因为B拥有未决锁(它能阻止其它连接获得共享锁)。那么时此,不仅A和B不能工作,其它所有进程都不能再操作此数据库了。
如果避免此情况呢?当然不能让A和B通过谈判解决,因为它们甚至不知道彼此的存在。答案是采用正确的事务类型来完成工作。
事务的种类
SQLite有三种不同的事务,使用不同的锁状态。事务可以开始于:DEFERRED、MMEDIATE或EXCLUSIVE。事务类型在BEGIN命令中指定:
BEGIN [ DEFERRED | IMMEDIATE | EXCLUSIVE ] TRANSACTION;
一个DEFERRED事务不获取任何锁(直到它需要锁的时候),BEGIN语句本身也不会做什么事情——它开始于UNLOCK状态。默认情况下就 是这样的,如果仅仅用BEGIN开始一个事务,那么事务就是DEFERRED的,同时它不会获取任何锁;当对数据库进行第一次读操作时,它会获取 SHARED锁;同样,当进行第一次写操作时,它会获取RESERVED锁。
由BEGIN开始的IMMEDIATE事务会尝试获取RESERVED锁。如果成功,BEGIN IMMEDIATE保证没有别的连接可以写数据库。但是,别的连接可以对数据库进行读操作;但是,RESERVED锁会阻止其它连接的BEGIN IMMEDIATE或者BEGIN EXCLUSIVE命令,当其它连接执行上述命令时,会返回SQLITE_BUSY错误。这时你就可以对数据库进行修改操作了,但是你还不能提交,当你 COMMIT时,会返回SQLITE_BUSY错误,这意味着还有其它的读事务没有完成,得等它们执行完后才能提交事务。
EXCLUSIVE事务会试着获取对数据库的EXCLUSIVE锁。这与IMMEDIATE类似,但是一旦成功,EXCLUSIVE事务保证没有其它的连接,所以就可对数据库进行读写操作了。
上节那个例子的问题在于两个连接最终都想写数据库,但是它们都没有放弃各自原来的锁,最终,SHARED锁导致了问题的出现。如果两个连接都以 BEGIN IMMEDIATE开始事务,那么死锁就不会发生。在这种情况下,在同一时刻只能有一个连接进入BEGIN IMMEDIATE,其它的连接就得等待。BEGIN IMMEDIATE和BEGIN EXCLUSIVE通常被写事务使用。就像同步机制一样,它防止了死锁的产生。
基本的准则是:如果你正在使用的数据库没有其它的连接,用BEGIN就足够了。但是,如果你使用的数据库有其它的连接也会对数据库进行写操作,就得使用BEGIN IMMEDIATE或BEGIN EXCLUSIVE开始你的事务。
- sqlite 视图、触发器、索引和事务总结
- sqlite 视图、触发器、索引和事务总结
- 事务、触发器、视图、索引
- 事务、视图和索引
- 事务、视图和索引
- 事务,游标,索引,视图,存储过程,触发器
- 索引、视图、游标、存储过程和触发器理解总结
- 数据库知识点总结(发展,约束,索引,触发器,连接池,视图,事务)
- 06事务、视图和索引
- sql事务、视图和索引
- 事务、视图、索引和备份
- Oracle数据库之视图、索引、存储过程、触发器、事务、函数
- 视图、索引、存储过程 、触发器、游标及事务
- 视图、索引、存储过程 、触发器、游标及事务
- 视图、索引、存储过程 、触发器、游标及事务
- 开窗函数,视图,事务,存储过程,索引,触发器,游标
- 视图、索引、存储过程 、触发器、游标及事务详解
- mysql事务视图触发器
- 1325 hdu
- 蜂鸟算法在谷歌15岁生日发布引起搜索引擎的哪些变化
- Problem A.Ant on a Chessboard
- ZOJ-2201
- 北魏正光五年铭金铜成铺弥勒佛大祭坛——美国纽约大都会艺术博物馆神秘荣光
- sqlite 视图、触发器、索引和事务总结
- GNURadio中的错误及解决方发
- 海外藏中国古代佛教造像名品粹赏0001
- phpStudy 2013.12.20 下载
- 海外藏中国古代佛教造像名品粹赏0002
- Linux下DIR,dirent,stat等结构体详解
- Cube painting
- mfs信息杂记
- 河北易县八佛洼辽三彩罗汉造像


