最长公共子串问题的后缀数组解法
来源:互联网 发布:录屏软件fast 编辑:程序博客网 时间:2024/04/20 00:36
[最长公共子串]
最长公共子串(Longest Common Substring ,简称LCS)问题,是指求给定的一组字符串长度最大的共有的子串的问题。例如字符串”abcb”,”bca”,”acbc”的LCS就是”bc”。
求多串的LCS,显然穷举法是极端低效的算法。改进一些的算法是用一个串的每个后缀对其他所有串进行部分匹配,用KMP算法,时间复杂度为O(N*L^2),其中N为字符串个数,L为每个串的长度。更优秀的有广义后缀树的方法,时间可以达到 O(N*L)。本文介绍一种基于后缀数组的LCS解法,利用二分查找技术,时间复杂度可以达到O(N*L*logL)。
[最长公共子串问题的后缀数组解法]
关于后缀数组的构建方法以及Height数组的性质,本文不再具体介绍,可以参阅IOI国家集训队2004年论文《后缀数组》(许智磊)和IOI国家集训队2009年论文《后缀数组——处理字符串的有力工具》(罗穗骞)。
回顾一下后缀数组,SA[i]表示排名第i的后缀的位置,Height[i]表示后缀SA[i]和SA[i-1]的最长公共前缀(Longest Common Prefix,LCP),简记为Height[i]=LCP(SA[i],SA[i-1])。连续的一段后缀SA[i..j]的最长公共前缀,就是H[i-1..j]的最小值,即LCP(SA[i..j])=Min(H[i-1..j])。
求N个串的最长公共子串,可以转化为求一些后缀的最长公共前缀的最大值,这些后缀应分属于N个串。具体方法如下:
设N个串分别为S1,S2,S3,…,SN,首先建立一个串S,把这N个串用不同的分隔符连接起来。S=S1[P1]S2[P2]S3…SN-1[PN-1]SN,P1,P2,…PN-1应为不同的N-1个不在字符集中的字符,作为分隔符(后面会解释为什么)。
接下来,求出字符串S的后缀数组和Height数组,可以用倍增算法,或DC3算法。
然后二分枚举答案A,假设N个串可以有长度为A的公共字串,并对A的可行性进行验证。如果验证A可行,A’(A’<A)也一定可行,尝试增大A,反之尝试缩小A。最终可以取得A的最大可行值,就是这N个串的最长公共子串的长度。可以证明,尝试次数是O(logL)的。
于是问题就集中到了,如何验证给定的长度A是否为可行解。方法是,找出在Height数组中找出连续的一段Height[i..j],使得i<=k<=j均满足Height[k]>=A,并且i-1<=k<=j中,SA[k]分属于原有N个串S1..SN。如果能找到这样的一段,那么A就是可行解,否则A不是可行解。
具体查找i..j时,可以先从前到后枚举i的位置,如果发现Height[i]>=A,则开始从i向后枚举j的位置,直到找到了Height[j+1]<A,判断[i..j]这个区间内SA是否分属于S1..SN。如果满足,则A为可行解,然后直接返回,否则令i=j+1继续向后枚举。S中每个字符被访问了O(1)次,S的长度为N*L+N-1,所以验证的时间复杂度为O(N*L)。
到这里,我们就可以理解为什么分隔符P1..PN-1必须是不同的N-1个不在字符集中的字符了,因为这样才能保证S的后缀的公共前缀不会跨出一个原有串的范围。
后缀数组是一种处理字符串的强大的数据结构,配合LCP函数与Height数组的性质,后缀数组更是如虎添翼。利用后缀数组,容易地求出了多个串的LCS,而且时空复杂度也相当优秀了。虽然比起后缀树的解法有所不如,但其简明的思路和容易编程的特点却在实际的应用中并不输于后缀树。
附:POI 2000 Repetitions 最长公共子串
- /*
- * Problem: POI2000 pow
- * Author: Guo Jiabao
- * Time: 2009.4.16 21:00
- * State: Solved
- * Memo: 多串最长公共子串 后缀数组 二分答案
- */
- #include <iostream>
- #include <cstdio>
- #include <cstdlib>
- #include <cmath>
- #include <cstring>
- const int MAXL=10011,MAXN=6;
- using namespace std;
- struct SuffixArray
- {
- struct RadixElement
- {
- int id,k[2];
- }RE[MAXL],RT[MAXL];
- int N,A[MAXL],SA[MAXL],Rank[MAXL],Height[MAXL],C[MAXL];
- void RadixSort()
- {
- int i,y;
- for (y=1;y>=0;y--)
- {
- memset(C,0,sizeof(C));
- for (i=1;i<=N;i++) C[RE[i].k[y]]++;
- for (i=1;i<MAXL;i++) C[i]+=C[i-1];
- for (i=N;i>=1;i--) RT[C[RE[i].k[y]]--]=RE[i];
- for (i=1;i<=N;i++) RE[i]=RT[i];
- }
- for (i=1;i<=N;i++)
- {
- Rank[ RE[i].id ]=Rank[ RE[i-1].id ];
- if (RE[i].k[0]!=RE[i-1].k[0] || RE[i].k[1]!=RE[i-1].k[1])
- Rank[ RE[i].id ]++;
- }
- }
- void CalcSA()
- {
- int i,k;
- RE[0].k[0]=-1;
- for (i=1;i<=N;i++)
- RE[i].id=i,RE[i].k[0]=A[i],RE[i].k[1]=0;
- RadixSort();
- for (k=1;k+1<=N;k*=2)
- {
- for (i=1;i<=N;i++)
- RE[i].id=i,RE[i].k[0]=Rank[i],RE[i].k[1]=i+k<=N?Rank[i+k]:0;
- RadixSort();
- }
- for (i=1;i<=N;i++)
- SA[ Rank[i] ]=i;
- }
- void CalcHeight()
- {
- int i,k,h=0;
- for (i=1;i<=N;i++)
- {
- if (Rank[i]==1)
- h=0;
- else
- {
- k=SA[Rank[i]-1];
- if (--h<0) h=0;
- for (;A[i+h]==A[k+h];h++);
- }
- Height[Rank[i]]=h;
- }
- }
- }SA;
- int N,Ans,Bel[MAXL];
- char S[MAXL];
- void init()
- {
- int i;
- freopen("pow.in","r",stdin);
- freopen("pow.out","w",stdout);
- scanf("%d",&N);
- SA.N=0;
- for (i=1;i<=N;i++)
- {
- scanf("%s",S);
- for (char *p=S;*p;p++)
- {
- SA.A[++SA.N]=*p-'a'+1;
- Bel[SA.N]=i;
- }
- if (i<N)
- SA.A[++SA.N]=30+i;
- }
- }
- bool check(int A)
- {
- int i,j,k;
- bool ba[MAXN];
- for (i=1;i<=SA.N;i++)
- {
- if (SA.Height[i]>=A)
- {
- for (j=i;SA.Height[j]>=A && j<=SA.N;j++);
- j--;
- memset(ba,0,sizeof(ba));
- for (k=i-1;k<=j;k++)
- ba[Bel[SA.SA[k]]]=true;
- for (k=1;ba[k] && k<=N;k++);
- if (k==N+1)
- return true;
- i=j;
- }
- }
- return false;
- }
- void solve()
- {
- int a,b,m;
- SA.CalcSA();
- SA.CalcHeight();
- a=0;b=SA.N;
- while (a+1<b)
- {
- m=(a+b)/2;
- if (check(m))
- a=m;
- else
- b=m-1;
- }
- if (check(b))
- a=b;
- Ans=a;
- }
- int main()
- {
- init();
- solve();
- printf("%dn",Ans);
- return 0;
- }
转载自http://www.byvoid.com/blog/lcs-suffix-array/
—————————————————————————————————————————————————————————————————————————————
附上两篇文中提及的论文
《后缀数组》+许智磊
(pdf的 转换成网页不太方便,要看的自己去下(这个是CSDN上的要一个金币)
后缀数组——处理字符串的有力工具.pdf
后缀数组——处理字符串的有力工具
作者:罗穗骞
2009年1月
【摘要】
后缀数组是处理字符串的有力工具。后缀数组是后缀树的一个非常精巧的替代品,它比后缀树容易编程实现,能够实现后缀树的很多功能而时间复杂度也并不逊色,而且它比后缀树所占用的内存空间小很多。可以说,在信息学竞赛中后缀数组比后缀树要更为实用。本文分两部分。第一部分介绍两种构造后缀数组的方法,重点介绍如何用简洁高效的代码实现,并对两种算法进行了比较。第二部分介绍后缀数组在各种类型题目中的具体应用。
【关键字】
字符串,后缀,后缀数组,名次数组,基数排序,
【正文】
一、后缀数组的实现
本节主要介绍后缀数组的两种实现方法:倍增算法(Doubling Algorithm)和DC3算法(Difference Cover),并对两种算法进行了比较。可能有的读者会认为这两种算法难以理解,即使理解了也难以用程序实现。本节针对这个问题,在介绍这两种算法的基础上,还给出了简洁高效的代码。其中倍增算法只有25行,DC3算法只有40行。
1.1、基本定义
子串:字符串S的子串r[i..j],i≤j,表示r串中从i到j这一段,也就是顺次排列r[i],r[i+1],...,r[j]形成的字符串。
后缀:后缀是指从某个位置i开始到整个串末尾结束的一个特殊子串。字符串r的从第i个字符开始的后缀表示为Suffix(i),也就是Suffix(i)=r[i..len(r)]。
大小比较:关于字符串的大小比较,是指通常所说的“字典顺序”比较,也就是对于两个字符串u、v,令i从1开始顺次比较u[i]和v[i],如果u[i]=v[i]则令i加1,否则若u[i]<v[i]则认为u<v,u[i]>v[i]则认为u>v(也就是v<u),比较结束。如果i>len(u)或者 i>len(v)仍比较不出结果,那么若len(u)<len(v)则认为u<v,若 len(u)=len(v)则认为u=v,若len(u)>len(v)则 u>v。
从字符串的大小比较的定义来看,S的两个开头位置不同的后缀 u和v进行比较的结果不可能是相等,因为 u=v的必要条件len(u)=len(v)在这里不可能满足。
后缀数组:后缀数组SA是一个一维数组,它保存1..n的某个排列SA[1],SA[2],……,SA[n],并且保证 Suffix(SA[i])<Suffix(SA[i+1]),1≤i<n。也就是将S的n个后缀从小到大进行排序之后把排好序的后缀的开头位置顺次放入SA中。
名次数组:名次数组Rank[i]保存的是Suffix(i)在所有后缀中从小到大排列的“名次”。
简单的说,后缀数组是“排第几的是谁?”,名次数组是“你排第几?”。容易看出,后缀数组和名次数组为互逆运算。如图1所示。
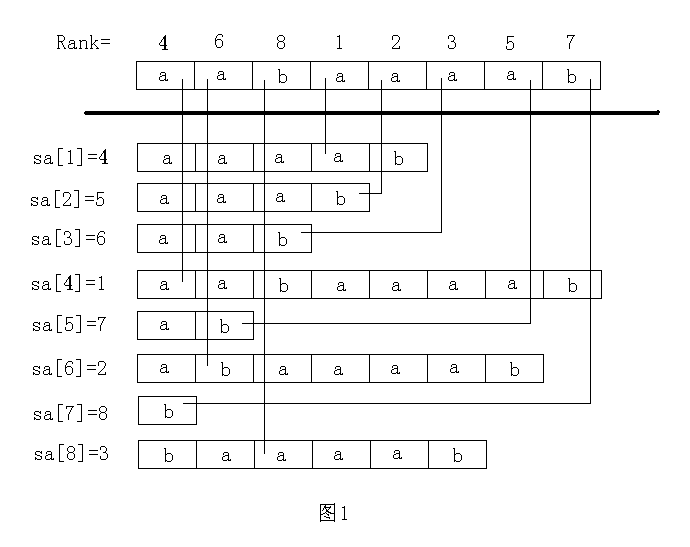
设字符串的长度为n。为了方便比较大小,可以在字符串后面添加一个字符,这个字符没有在前面的字符中出现过,而且比前面的字符都要小。在求出名次数组后,可以仅用O(1)的时间比较任意两个后缀的大小。在求出后缀数组或名次数组中的其中一个以后,便可以用O(n)的时间求出另外一个。任意两个后缀如果直接比较大小,最多需要比较字符n次,也就是说最迟在比较第n个字符时一定能分出“胜负”。
1.2、倍增算法
倍增算法的主要思路是:用倍增的方法对每个字符开始的长度为2k的子字符串进行排序,求出排名,即rank值。k从0开始,每次加1,当2k大于n以后,每个字符开始的长度为2k的子字符串便相当于所有的后缀。并且这些子字符串都一定已经比较出大小,即rank值中没有相同的值,那么此时的rank值就是最后的结果。每一次排序都利用上次长度为2k-1的字符串的rank值,那么长度为2k的字符串就可以用两个长度为2k-1的字符串的排名作为关键字表示,然后进行基数排序,便得出了长度为2k的字符串的rank值。以字符串“aabaaaab”为例,整个过程如图2所示。其中x、y是表示长度为2k的字符串的两个关键字。

具体实现:
int wa[maxn],wb[maxn],wv[maxn],ws[maxn];
int cmp(int *r,int a,int b,int l)
{return r[a]==r[b]&&r[a+l]==r[b+l];}
void da(int *r,int *sa,int n,int m)
{
int i,j,p,*x=wa,*y=wb,*t;
for(i=0;i<m;i++) ws[i]=0;
for(i=0;i<n;i++) ws[x[i]=r[i]]++;
for(i=1;i<m;i++) ws[i]+=ws[i-1];
for(i=n-1;i>=0;i--) sa[--ws[x[i]]]=i;
for(j=1,p=1;p<n;j*=2,m=p)
{
for(p=0,i=n-j;i<n;i++) y[p++]=i;
for(i=0;i<n;i++) if(sa[i]>=j) y[p++]=sa[i]-j;
for(i=0;i<n;i++) wv[i]=x[y[i]];
for(i=0;i<m;i++) ws[i]=0;
for(i=0;i<n;i++) ws[wv[i]]++;
for(i=1;i<m;i++) ws[i]+=ws[i-1];
for(i=n-1;i>=0;i--) sa[--ws[wv[i]]]=y[i];
for(t=x,x=y,y=t,p=1,x[sa[0]]=0,i=1;i<n;i++)
x[sa[i]]=cmp(y,sa[i-1],sa[i],j)?p-1:p++;
}
return;
}
待排序的字符串放在r数组中,从r[0]到r[n-1],长度为n,且最大值小于m。为了函数操作的方便,约定除r[n-1]外所有的r[i]都大于0,r[n-1]=0。函数结束后,结果放在sa数组中,从sa[0]到sa[n-1]。
函数的第一步,要对长度为1的字符串进行排序。一般来说,在字符串的题目中,r的最大值不会很大,所以这里使用了基数排序。如果r的最大值很大,那么把这段代码改成快速排序。代码:
for(i=0;i<m;i++) ws[i]=0;
for(i=0;i<n;i++) ws[x[i]=r[i]]++;
for(i=1;i<m;i++) ws[i]+=ws[i-1];
for(i=n-1;i>=0;i--) sa[--ws[x[i]]]=i;
这里x数组保存的值相当于是rank值。下面的操作只是用x数组来比较字符的大小,所以没有必要求出当前真实的rank值。
接下来进行若干次基数排序,在实现的时候,这里有一个小优化。基数排序要分两次,第一次是对第二关键字排序,第二次是对第一关键字排序。对第二关键字排序的结果实际上可以利用上一次求得的sa直接算出,没有必要再算一次。代码:
for(p=0,i=n-j;i<n;i++) y[p++]=i;
for(i=0;i<n;i++) if(sa[i]>=j) y[p++]=sa[i]-j;
其中变量j是当前字符串的长度,数组y保存的是对第二关键字排序的结果。然后要对第一关键字进行排序,代码:
for(i=0;i<n;i++) wv[i]=x[y[i]];
for(i=0;i<m;i++) ws[i]=0;
for(i=0;i<n;i++) ws[wv[i]]++;
for(i=1;i<m;i++) ws[i]+=ws[i-1];
for(i=n-1;i>=0;i--) sa[--ws[wv[i]]]=y[i];
这样便求出了新的sa值。在求出sa后,下一步是计算rank值。这里要注意的是,可能有多个字符串的rank值是相同的,所以必须比较两个字符串是否完全相同,y数组的值已经没有必要保存,为了节省空间,这里用y数组保存rank值。这里又有一个小优化,将x和y定义为指针类型,复制整个数组的操作可以用交换指针的值代替,不必将数组中值一个一个的复制。代码:
for(t=x,x=y,y=t,p=1,x[sa[0]]=0,i=1;i<n;i++)
x[sa[i]]=cmp(y,sa[i-1],sa[i],j)?p-1:p++;
其中cmp函数的代码是:
int cmp(int *r,int a,int b,int l)
{return r[a]==r[b]&&r[a+l]==r[b+l];}
这里可以看到规定r[n-1]=0的好处,如果r[a]=r[b],说明以r[a]或r[b]开头的长度为l的字符串肯定不包括字符r[n-1],所以调用变量r[a+l]和r[b+l]不会导致数组下标越界,这样就不需要做特殊判断。执行完上面的代码后,rank值保存在x数组中,而变量p的结果实际上就是不同的字符串的个数。这里可以加一个小优化,如果p等于n,那么函数可以结束。因为在当前长度的字符串中,已经没有相同的字符串,接下来的排序不会改变rank值。例如图1中的第四次排序,实际上是没有必要的。对上面的两段代码,循环的初始赋值和终止条件可以这样写:
for(j=1,p=1;p<n;j*=2,m=p) {…………}
在第一次排序以后,rank数组中的最大值小于p,所以让m=p。
整个倍增算法基本写好,代码大约25行。
算法分析:
倍增算法的时间复杂度比较容易分析。每次基数排序的时间复杂度为O(n),排序的次数决定于最长公共子串的长度,最坏情况下,排序次数为logn次,所以总的时间复杂度为O(nlogn)。
1.3、DC3算法
DC3算法分3步:
(1)、先将后缀分成两部分,然后对第一部分的后缀排序。
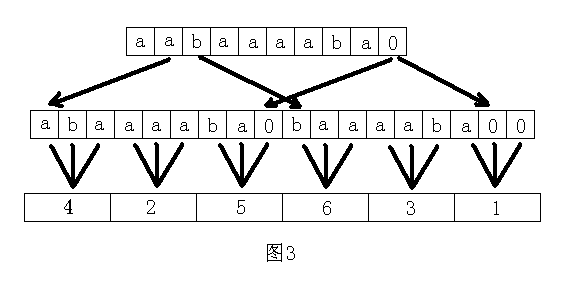
将后缀分成两部分,第一部分是后缀k(k模3不等于0),第二部分是后缀k(k模3等于0)。先对所有起始位置模3不等于0的后缀进行排序,即对suffix(1),suffix(2),suffix(4),suffix(5),suffix(7)……进行排序。做法是将suffix(1)和suffix(2)连接,如果这两个后缀的长度不是3的倍数,那先各自在末尾添0使得长度都变成3的倍数。然后每3个字符为一组,进行基数排序,将每组字符“合并”成一个新的字符。然后用递归的方法求这个新的字符串的后缀数组。如图3所示。在得到新的字符串的sa后,便可以计算出原字符串所有起始位置模3不等于0的后缀的sa。要注意的是,原字符串必须以一个最小的且前面没有出现过的字符结尾,这样才能保证结果正确(请读者思考为什么)。
(2)、利用(1)的结果,对第二部分的后缀排序。
剩下的后缀是起始位置模3等于0的后缀,而这些后缀都可以看成是一个字符加上一个在(1)中已经求出 rank的后缀,所以只要一次基数排序便可以求出剩下的后缀的sa。
(3)、将(1)和(2)的结果合并,即完成对所有后缀排序。
这个合并操作跟合并排序中的合并操作一样。每次需要比较两个后缀的大小。分两种情况考虑,第一种情况是suffix(3*i)和suffix(3*j+1)的比较,可以把suffix(3*i)和suffix(3*j+1)表示成:
suffix(3*i) = r[3*i] + suffix(3*i+1)
suffix(3*j+1) = r[3*j+1] + suffix(3*j+2)
其中 suffix(3*i+1)和 suffix(3*j+2)的比较可以利用(2)的结果快速得到。第二种情况是 suffix(3*i)和 suffix(3*j+2)的比较,可以把 suffix(3*i)和suffix(3*j+2)表示成:
suffix(3*i) = r[3*i] + r[3*i+1] + suffix(3*i+2)
suffix(3*j+2) = r[3*j+2] + r[3*j+3] + suffix(3*(j+1)+1)
同样的道理,suffix(3*i+2)和 suffix(3*(j+1)+1)的比较可以利用(2)的结果快速得到。所以每次的比较都可以高效的完成,这也是之前要每 3个字符合并,而不是每 2个字符合并的原因。
具体实现:
#define F(x) ((x)/3+((x)%3==1?0:tb))
#define G(x) ((x)<tb?(x)*3+1:((x)-tb)*3+2)
int wa[maxn],wb[maxn],wv[maxn],ws[maxn];
int c0(int *r,int a,int b)
{return r[a]==r[b]&&r[a+1]==r[b+1]&&r[a+2]==r[b+2];}
int c12(int k,int *r,int a,int b)
{if(k==2) return r[a]<r[b]||r[a]==r[b]&&c12(1,r,a+1,b+1);
else return r[a]<r[b]||r[a]==r[b]&&wv[a+1]<wv[b+1];}
void sort(int *r,int *a,int *b,int n,int m)
{
int i;
for(i=0;i<n;i++) wv[i]=r[a[i]];
for(i=0;i<m;i++) ws[i]=0;
for(i=0;i<n;i++) ws[wv[i]]++;
for(i=1;i<m;i++) ws[i]+=ws[i-1];
for(i=n-1;i>=0;i--) b[--ws[wv[i]]]=a[i];
return;
}
void dc3(int *r,int *sa,int n,int m)
{
int i,j,*rn=r+n,*san=sa+n,ta=0,tb=(n+1)/3,tbc=0,p;
r[n]=r[n+1]=0;
for(i=0;i<n;i++) if(i%3!=0) wa[tbc++]=i;
sort(r+2,wa,wb,tbc,m);
sort(r+1,wb,wa,tbc,m);
sort(r,wa,wb,tbc,m);
for(p=1,rn[F(wb[0])]=0,i=1;i<tbc;i++)
rn[F(wb[i])]=c0(r,wb[i-1],wb[i])?p-1:p++;
if(p<tbc) dc3(rn,san,tbc,p);
else for(i=0;i<tbc;i++) san[rn[i]]=i;
for(i=0;i<tbc;i++) if(san[i]<tb) wb[ta++]=san[i]*3;
if(n%3==1) wb[ta++]=n-1;
sort(r,wb,wa,ta,m);
for(i=0;i<tbc;i++) wv[wb[i]=G(san[i])]=i;
for(i=0,j=0,p=0;i<ta && j<tbc;p++)
sa[p]=c12(wb[j]%3,r,wa[i],wb[j])?wa[i++]:wb[j++];
for(;i<ta;p++) sa[p]=wa[i++];
for(;j<tbc;p++) sa[p]=wb[j++];
return;
}
各个参数的作用和前面的倍增算法一样,不同的地方是r数组和sa数组的大小都要是3*n,这为了方便下面的递归处理,不用每次都申请新的内存空间。函数中用到的变量:
int i,j,*rn=r+n,*san=sa+n,ta=0,tb=(n+1)/3,tbc=0,p;
rn数组保存的是(1)中要递归处理的新字符串,san数组是新字符串的sa。变量ta表示起始位置模3为0的后缀个数,变量tb表示起始位置模3为1的后缀个数,已经直接算出。变量tbc表示起始位置模3为1或2的后缀个数。先按(1)中所说的用基数排序把3个字符“合并 ”成一个新的字符。为了方便操作,先将r[n]和r[n+1]赋值为0。
代码:
r[n]=r[n+1]=0;
for(i=0;i<n;i++) if(i%3!=0) wa[tbc++]=i;
sort(r+2,wa,wb,tbc,m);
sort(r+1,wb,wa,tbc,m);
sort(r,wa,wb,tbc,m);
其中sort函数的作用是进行基数排序。代码:
void sort(int *r,int *a,int *b,int n,int m)
{
int i;
for(i=0;i<n;i++) wv[i]=r[a[i]];
for(i=0;i<m;i++) ws[i]=0;
for(i=0;i<n;i++) ws[wv[i]]++;
for(i=1;i<m;i++) ws[i]+=ws[i-1];
for(i=n-1;i>=0;i--) b[--ws[wv[i]]]=a[i];
return;
}
基数排序结束后,新的字符的排名保存在 wb数组中。
跟倍增算法一样,在基数排序以后,求新的字符串时要判断两个字符组是否完全相同。代码:
for(p=1,rn[F(wb[0])]=0,i=1; i<tbc;i++)
rn[F(wb[i])]=c0(r,wb[i-1],wb[i])?p-1:p++;
其中 F(x)是计算出原字符串的 suffix(x)在新的字符串中的起始位置,c0函数是比较是否完全相同,在开头加一段代码:
#define F(x) ((x)/3+((x)%3==1?0:tb))
inline int c0(int *r,int a,int b)
{return r[a]==r[b]&&r[a+1]==r[b+1]&&r[a+2]==r[b+2];}
接下来是递归处理新的字符串,这里和倍增算法一样,可以加一个小优化,如果p等于tbc,那么说明在新的字符串中没有相同的字符,这样可以直接求出san数组,并不用递归处理。代码:
if(p<tbc) dc3(rn,san,tbc,p);
else for(i=0;i<tbc;i++) san[rn[i]]=i;
然后是第(2)步,将所有起始位置模3等于0的后缀进行排序。其中对第二关键字的排序结果可以由新字符串的sa直接计算得到,没有必要再排一次。代码:
for(i=0;i<tbc;i++) if(san[i]<tb) wb[ta++]=san[i]*3;
if(n%3==1) wb[ta++]=n-1;
sort(r,wb,wa,ta,m);
for(i=0;i<tbc;i++) wv[wb[i]=G(san[i])]=i;
要注意的是,如果n%3==1,要特殊处理suffix(n-1),因为在san数组里并没有suffix(n)。G(x)是计算新字符串的suffix(x)在原字符串中的位置,和F(x)为互逆运算。在开头加一段:
#define G(x) ((x)<tb?(x)*3+1:((x)-tb)*3+2)。
最后是第(3)步,合并所有后缀的排序结果,保存在sa数组中。代码:
for(i=0,j=0,p=0;i<ta && j<tbc;p++)
sa[p]=c12(wb[j]%3,r,wa[i],wb[j])?wa[i++]:wb[j++];
for(;i<ta;p++) sa[p]=wa[i++];
for(;j<tbc;p++) sa[p]=wb[j++];
其中c12函数是按(3)中所说的比较后缀大小的函数,k=1是第一种情况,k=2是第二种情况。代码:
int c12(int k,int *r,int a,int b)
{if(k==2) return r[a]<r[b]||r[a]==r[b]&&c12(1,r,a+1,b+1);
else return r[a]<r[b]||r[a]==r[b]&&wv[a+1]<wv[b+1];}
整个DC3算法基本写好,代码大约40行。
算法分析:
假设这个算法的时间复杂度为f(n)。容易看出第(1)步排序的时间为O(n)(一般来说,m比较小,这里忽略不计),新的字符串的长度不超过2n/3,求新字符串的 sa的时间为f(2n/3),第(2)和第(3)步的时间都是 O(n)。所以
f(n) = O(n) + f(2n/3)
f(n) ≤ c×n + f(2n/3)
f(n) ≤ c×n + c×(2n/3) + c×(4n/9) + c×(8n/27) + …… ≤ 3c×n
所以 f(n) = O(n)
由此看出,DC3算法是一个优秀的线性算法。
1.4、倍增算法与DC3算法的比较
从时间复杂度、空间复杂度、编程复杂度和实际效率等方面对倍增算法与DC3算法进行比较。
时间复杂度:
倍增算法的时间复杂度为O(nlogn),DC3算法的时间复杂度为O(n)。从常数上看,DC3算法的常数要比倍增算法大。
空间复杂度:
倍增算法和DC3算法的空间复杂度都是O(n)。按前面所讲的实现方法,倍增算法所需数组总大小为6n,DC3算法所需数组总大小为10n。
编程复杂度:
倍增算法的源程序长度为 25行,DC3算法的源程序长度为 40行。
实际效率:
测试环境:NOI-linux Pentium(R) 4 CPU 2.80GHz
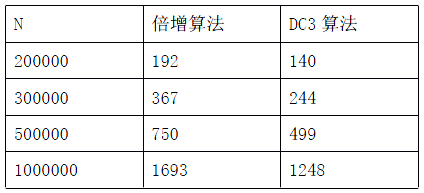
(不包括读入和输出的时间,单位:ms)
从表中可以看出,DC3算法在实际效率上还是有一定优势的。倍增算法容易实现,DC3算法效率比较高,但是实现起来比倍增算法复杂一些。对于不同的题目,应当根据数据规模的大小决定使用哪个算法。
二、后缀数组的应用
本节主要介绍后缀数组在各种类型的字符串问题中的应用。各题的原题请见附件二,参考代码请见附件三。
2.1、最长公共前缀
这里先介绍后缀数组的一些性质。
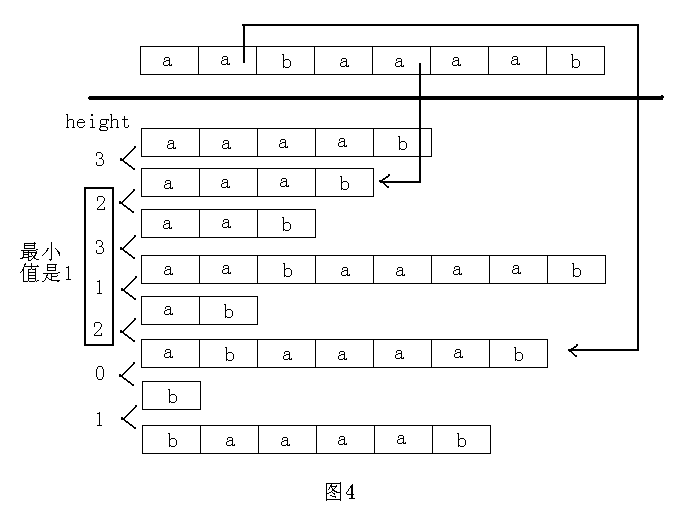
height数组:定义height[i]=suffix(sa[i-1])和suffix(sa[i])的最长公共前缀,也就是排名相邻的两个后缀的最长公共前缀。那么对于j和k,不妨设rank[j]<rank[k],则有以下性质:
suffix(j)和suffix(k)的最长公共前缀为height[rank[j]+1],height[rank[j]+2],height[rank[j]+3],……,height[rank[k]]中的最小值。
例如,字符串为“aabaaaab”,求后缀“abaaaab”和后缀“aaab”的最长公共前缀,如图4所示:
那么应该如何高效的求出height值呢?
如果按height[2],height[3],……,height[n]的顺序计算,最坏情况下时间复杂度为O(n2)。这样做并没有利用字符串的性质。定义h[i]=height[rank[i]],也就是suffix(i)和在它前一名的后缀的最长公共前缀。
h数组有以下性质:
h[i]≥h[i-1]-1
证明:
设suffix(k)是排在suffix(i-1)前一名的后缀,则它们的最长公共前缀是h[i-1]。那么suffix(k+1)将排在suffix(i)的前面(这里要求h[i-1]>1,如果h[i-1]≤1,原式显然成立)并且suffix(k+1)和suffix(i)的最长公共前缀是h[i-1]-1,所以suffix(i)和在它前一名的后缀的最长公共前缀至少是h[i-1]-1。按照h[1],h[2],……,h[n]的顺序计算,并利用h数组的性质,时间复杂度可以降为O(n)。
具体实现:
实现的时候其实没有必要保存h数组,只须按照h[1],h[2],……,h[n]的顺序计算即可。代码:
int rank[maxn],height[maxn];
void calheight(int *r,int *sa,int n)
{
int i,j,k=0;
for(i=1;i<=n;i++) rank[sa[i]]=i;
for(i=0;i<n;height[rank[i++]]=k)
for(k?k--:0,j=sa[rank[i]-1];r[i+k]==r[j+k];k++);
return;
}
例1:最长公共前缀
给定一个字符串,询问某两个后缀的最长公共前缀。
算法分析:
按照上面所说的做法,求两个后缀的最长公共前缀可以转化为求某个区间上的最小值。对于这个RMQ问题(如果对RMQ(Range Minimum Query)问题不熟悉,请阅读其他相关资料),可以用O(nlogn)的时间先预处理,以后每次回答询问的时间为O(1)。所以对于本问题,预处理时间为O(nlogn),每次回答询问的时间为O(1)。如果RMQ问题用O(n)的时间预处理,那么本问题预处理的时间可以做到O(n)。
2.2、单个字符串的相关问题
这类问题的一个常用做法是先求后缀数组和 height数组,然后利用 height数组进行求解。
2.2.1、重复子串
重复子串:字符串R在字符串L中至少出现两次,则称R是L的重复子串。
例2:可重叠最长重复子串
给定一个字符串,求最长重复子串,这两个子串可以重叠。
算法分析:
这道题是后缀数组的一个简单应用。做法比较简单,只需要求height数组里的最大值即可。首先求最长重复子串,等价于求两个后缀的最长公共前缀的最大值。因为任意两个后缀的最长公共前缀都是height数组里某一段的最小值,那么这个值一定不大于height数组里的最大值。所以最长重复子串的长度就是height数组里的最大值。这个做法的时间复杂度为O(n)。
例3:不可重叠最长重复子串(pku1743)
给定一个字符串,求最长重复子串,这两个子串不能重叠。
算法分析:
这题比上一题稍复杂一点。先二分答案,把题目变成判定性问题:判断是否存在两个长度为k的子串是相同的,且不重叠。解决这个问题的关键还是利用height数组。把排序后的后缀分成若干组,其中每组的后缀之间的height值都不小于k。例如,字符串为“aabaaaab”,当 k=2时,后缀分成了 4组,如图5所示。
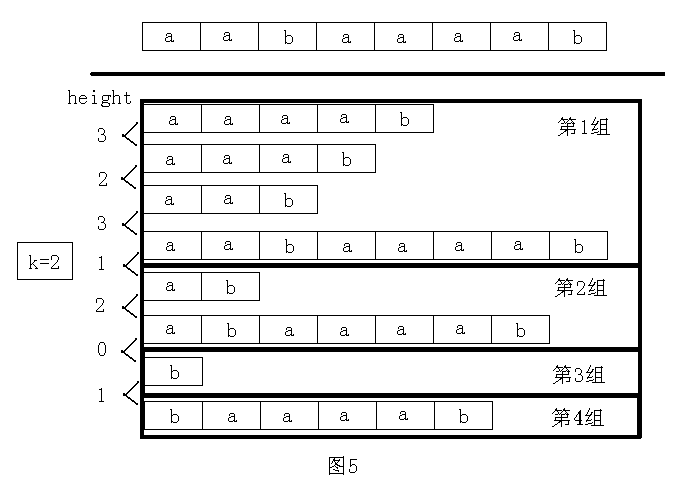
容易看出,有希望成为最长公共前缀不小于k的两个后缀一定在同一组。然后对于每组后缀,只须判断每个后缀的sa值的最大值和最小值之差是否不小于k。如果有一组满足,则说明存在,否则不存在。整个做法的时间复杂度为O(nlogn)。本题中利用 height值对后缀进行分组的方法很常用,请读者认真体会。
例4:可重叠的 k次最长重复子串(pku3261)
给定一个字符串,求至少出现k次的最长重复子串,这k个子串可以重叠。
算法分析:
这题的做法和上一题差不多,也是先二分答案,然后将后缀分成若干组。不同的是,这里要判断的是有没有一个组的后缀个数不小于k。如果有,那么存在k个相同的子串满足条件,否则不存在。这个做法的时间复杂度为 O(nlogn)。
2.2.2、子串的个数
例5:不相同的子串的个数(spoj694,spoj705)
给定一个字符串,求不相同的子串的个数。
算法分析:
每个子串一定是某个后缀的前缀,那么原问题等价于求所有后缀之间的不相同的前缀的个数。如果所有的后缀按照suffix(sa[1]),suffix(sa[2]),suffix(sa[3]),……,suffix(sa[n])的顺序计算,不难发现,对于每一次新加进来的后缀suffix(sa[k]),它将产生n-sa[k]+1个新的前缀。但是其中有height[k]个是和前面的字符串的前缀是相同的。所以suffix(sa[k])将“贡献”出n-sa[k]+1-height[k]个不同的子串。累加后便是原问题的答案。这个做法的时间复杂度为O(n)。
2.2.3、回文子串
回文子串:如果将字符串L的某个子字符串R反过来写后和原来的字符串R一样,则称字符串R是字符串L的回文子串。
例6:最长回文子串(ural1297)
给定一个字符串,求最长回文子串。
算法分析:
穷举每一位,然后计算以这个字符为中心的最长回文子串。注意这里要分两种情况,一是回文子串的长度为奇数,二是长度为偶数。两种情况都可以转化为求一个后缀和一个反过来写的后缀的最长公共前缀。具体的做法是:将整个字符串反过来写在原字符串后面,中间用一个特殊的字符隔开。这样就把问题变为了求这个新的字符串的某两个后缀的最长公共前缀。如图6所示。
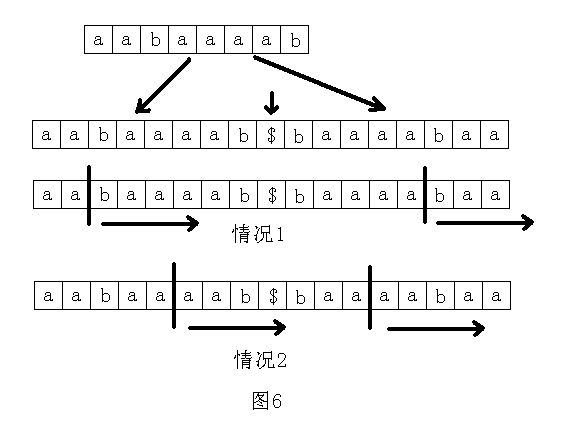
这个做法的时间复杂度为O(nlogn)。如果RMQ问题用时间为O(n)的方法预处理,那么本题的时间复杂度可以降为O(n)。
2.2.4、连续重复子串
连续重复串:如果一个字符串L是由某个字符串S重复R次而得到的,则称L是一个连续重复串。R是这个字符串的重复次数。
例7:连续重复子串(pku2406)
给定一个字符串L,已知这个字符串是由某个字符串S重复R次而得到的,求R的最大值。
算法分析:
做法比较简单,穷举字符串S的长 k,然后判断是否满足。判断的时候,先看字符串L的长度能否被k整除,再看suffix(1)和suffix(k+1)的最长公共前缀是否等于n-k。在询问最长公共前缀的时候,suffix(1)是固定的,所以RMQ问题没有必要做所有的预处理,只需求出height数组中的每一个数到height[rank[1]]之间的最小值即可。整个做法的时间复杂度为O(n)。
例8:重复次数最多的连续重复子串(spoj687,pku3693)
给定一个字符串,求重复次数最多的连续重复子串。
算法分析:
先穷举长度L,然后求长度为L的子串最多能连续出现几次。首先连续出现1次是肯定可以的,所以这里只考虑至少2次的情况。假设在原字符串中连续出现2次,记这个子字符串为S,那么S肯定包括了字符r[0],r[L],r[L*2],r[L*3],……中的某相邻的两个。所以只须看字符r[L*i]和r[L*(i+1)]往前和往后各能匹配到多远,记这个总长度为K,那么这里连续出现了K/L+1次。最后看最大值是多少。如图7所示。
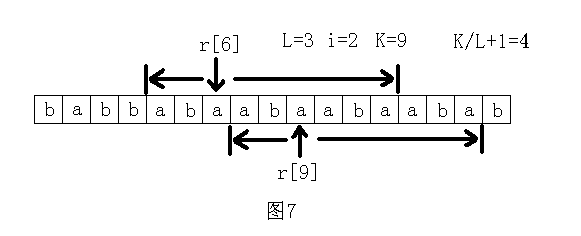
穷举长度L的时间是n,每次计算的时间是n/L。所以整个做法的时间复杂度是O(n/1+n/2+n/3+……+n/n)=O(nlogn)。
2.3、两个字符串的相关问题
这类问题的一个常用做法是,先连接这两个字符串,然后求后缀数组和height数组,再利用height数组进行求解。
2.3.1、公共子串
公共子串:如果字符串L同时出现在字符串A和字符串B中,则称字符串L是字符串A和字符串B的公共子串。
例9:最长公共子串(pku2774,ural1517)
给定两个字符串A和B,求最长公共子串。
算法分析:
字符串的任何一个子串都是这个字符串的某个后缀的前缀。求A和B的最长公共子串等价于求A的后缀和B的后缀的最长公共前缀的最大值。如果枚举A和B的所有的后缀,那么这样做显然效率低下。由于要计算A的后缀和B的后缀的最长公共前缀,所以先将第二个字符串写在第一个字符串后面,中间用一个没有出现过的字符隔开,再求这个新的字符串的后缀数组。观察一下,看看能不能从这个新的字符串的后缀数组中找到一些规律。以A=“aaaba”,B=“abaa”为例,如图8所示。

那么是不是所有的height值中的最大值就是答案呢?不一定!有可能这两个后缀是在同一个字符串中的,所以实际上只有当suffix(sa[i-1])和suffix(sa[i])不是同一个字符串中的两个后缀时,height[i]才是满足条件的。而这其中的最大值就是答案。记字符串A和字符串B的长度分别为|A|和|B|。求新的字符串的后缀数组和height数组的时间是O(|A|+|B|),然后求排名相邻但原来不在同一个字符串中的两个后缀的height值的最大值,时间也是O(|A|+|B|),所以整个做法的时间复杂度为O(|A|+|B|)。时间复杂度已经取到下限,由此看出,这是一个非常优秀的算法。
2.3.2、子串的个数
例10:长度不小于k的公共子串的个数(pku3415)
给定两个字符串A和B,求长度不小于k的公共子串的个数(可以相同)。
样例1:
A=“xx”,B=“xx”,k=1,长度不小于k的公共子串的个数是5。
样例2:
A =“aababaa”,B =“abaabaa”,k=2,长度不小于k的公共子串的个数是22。
算法分析:
基本思路是计算A的所有后缀和B的所有后缀之间的最长公共前缀的长度,把最长公共前缀长度不小于k的部分全部加起来。先将两个字符串连起来,中间用一个没有出现过的字符隔开。按height值分组后,接下来的工作便是快速的统计每组中后缀之间的最长公共前缀之和。扫描一遍,每遇到一个B的后缀就统计与前面的A的后缀能产生多少个长度不小于k的公共子串,这里A的后缀需要用一个单调的栈来高效的维护。然后对A也这样做一次。具体的细节留给读者思考。
2.4、多个字符串的相关问题
这类问题的一个常用做法是,先将所有的字符串连接起来,然后求后缀数组和height数组,再利用height数组进行求解。这中间可能需要二分答案。
例11:不小于k个字符串中的最长子串(pku3294)
给定n个字符串,求出现在不小于k个字符串中的最长子串。
算法分析:
将n个字符串连起来,中间用不相同的且没有出现在字符串中的字符隔开,求后缀数组。然后二分答案,用和例3同样的方法将后缀分成若干组,判断每组的后缀是否出现在不小于k个的原串中。这个做法的时间复杂度为O(nlogn)。
例12:每个字符串至少出现两次且不重叠的最长子串(spoj220)
给定n个字符串,求在每个字符串中至少出现两次且不重叠的最长子串。
算法分析:
做法和上题大同小异,也是先将n个字符串连起来,中间用不相同的且没有出现在字符串中的字符隔开,求后缀数组。然后二分答案,再将后缀分组。判断的时候,要看是否有一组后缀在每个原来的字符串中至少出现两次,并且在每个原来的字符串中,后缀的起始位置的最大值与最小值之差是否不小于当前答案(判断能否做到不重叠,如果题目中没有不重叠的要求,那么不用做此判断)。这个做法的时间复杂度为 O(nlogn)。
例13:出现或反转后出现在每个字符串中的最长子串(PKU3294)
给定n个字符串,求出现或反转后出现在每个字符串中的最长子串。
算法分析:
这题不同的地方在于要判断是否在反转后的字符串中出现。其实这并没有加大题目的难度。只需要先将每个字符串都反过来写一遍,中间用一个互不相同的且没有出现在字符串中的字符隔开,再将n个字符串全部连起来,中间也是用一个互不相同的且没有出现在字符串中的字符隔开,求后缀数组。然后二分答案,再将后缀分组。判断的时候,要看是否有一组后缀在每个原来的字符串或反转后的字符串中出现。这个做法的时间复杂度为O(nlogn)。
三、结束语
后缀数组是字符串处理中非常优秀的数据结构,是一种处理字符串的有力工 具,在不同类型的字符串问题中有广泛的应用。我们应该掌握好后缀数组这种数据结构,并且能在不同类型的题目中灵活、高效的运用。本文希望能为各位读者提供一点关于后缀数组的参考资料。对于前面所写的实现方法和各题的解答,如果读者有更好的做法,也欢迎读者与作者联系。
参考文献
[1] 刘汝佳,《算法艺术与信息学竞赛》,北京:清华大学出版社,2004
[2] 许智磊,IOI2004国家集训队论文《后缀数组》
[3] 周源,2005年信息学国家集训队作业《线性后缀排序算法》
致谢
感谢CCF给我提供一个与大家交流的平台
感谢清华大学的唐文斌教练对我的指导
感谢张学东老师在我写这篇论文时对我的帮助
感谢广州市第二中学的林盛华老师对我的指导和启发
感谢中山市第一中学的方展鹏、中山纪念中学的姜碧野同学提供关于后缀数组的资料
- 最长公共子串问题的后缀数组解法
- 最长公共子串问题的后缀数组解法
- 最长公共子串问题的后缀数组解法
- 最长公共子串问题的后缀数组解法
- 最长公共子串问题的后缀数组解法
- 最长公共子串问题的后缀数组解法
- 最长重复子序列问题的后缀数组解法
- 最长公共子串--后缀数组实现
- HDU1403(后缀数组--最长公共子串)
- 最长公共子串(后缀数组)
- 最长公共子串(后缀数组)
- 【poj2774】 后缀数组最长公共子串
- 后缀数组 最长公共子串
- 两个字符串的最长公共子串-后缀数组
- 史上最全最丰富的“最长公共子序列”、“最长公共子串”问题的解法与思路
- [CODEVS3160]最长公共子串|后缀数组|后缀自动机
- 后缀树和后缀数组 [3 两个字符串的最长公共子串]
- 求最长子串(后缀数组解法)
- Java遍历文件夹的两种方法(非递归和递归) .
- Matrix Swapping II
- java.lang.IllegalArgumentException: 'sessionFactory' or 'hibernateTemplate' is required
- 蓝桥杯——前缀表达式
- Quartz2D详解
- 最长公共子串问题的后缀数组解法
- Ubuntu 14.04 64bit上安装Scrapy
- TDD的iOS开发初步以及Kiwi使用入门
- Android 实现形态各异的双向侧滑菜单 自定义控件来袭
- 平衡状态数量+01背包
- Android使用ListView应该注意的地方
- google的zxing二维码生成
- AutoCompleteTextView最基础用法
- 必须掌握的知识点


