如何用简单易懂的例子解释隐马尔可夫模型?
来源:互联网 发布:淘宝店招图片尺寸 编辑:程序博客网 时间:2024/04/26 02:45
作者:冰炭
链接:http://www.zhihu.com/question/20962240/answer/48444087
来源:知乎
著作权归作者所有,转载请联系作者获得授权。
链接:http://www.zhihu.com/question/20962240/answer/48444087
来源:知乎
著作权归作者所有,转载请联系作者获得授权。
楼上的大神都说得很好了,我来补充一个有意思HMM的用法,是用来给定钢琴谱,自动决定指法的用法。
这个HMM的应用是来自于東京大学(東大真是所神奇的学校)的一个研究组在IJCAI 2007年的一篇文章,日文版的标题是《隠れマルコフモデルに基づくピアノ運指の自動決定》,英文版的标题是《Automatic Determination of Piano Fingering based on Hidden Markov Model》,论文的网页在这里:Sagayama & Ono Lab。从网页可以知道,这篇文中的工作其实至少从2005年就开始了。
愚以为在我目前能做到的范围内最好的学习一篇论文并让其对自己有用的方法就是重现之,所以此答案也按照现在回看当时重现过程的过程的顺序写。对于这个问题,我觉得比较重要的一点是“如何将HMM模型套用到这个问题上”,什么是HMM中的“因”,什么是HMM中的“果”,这个HMM在解决与琴键指法有关的问题是如何对应到HMM的三大任务=Scoring, Matching, Training的。然后你就很容易知道问题的输入是什么、输出是什么,然后将其转化为一个用程序员思维能解决的问题。
所以就开始俺们的钢琴运指自动决定之旅吧:
为了先有一个印象并明确问题的背景和定义,先看开门见山的介绍图:
<img data-rawheight="338" data-rawwidth="450" src="https://pic1.zhimg.com/7499958e318dbb13f88a64fb74678794_b.jpg" class="origin_image zh-lightbox-thumb" width="450" data-original="https://pic1.zhimg.com/7499958e318dbb13f88a64fb74678794_r.jpg">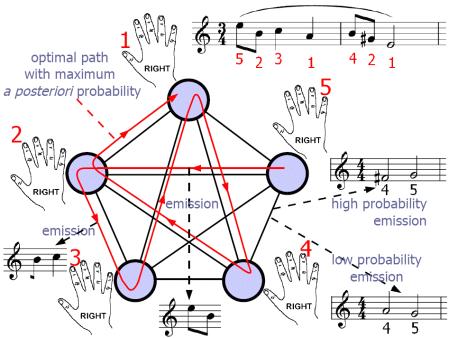
这个图的意思是说,“你有一个HMM模型,往里面丢入琴谱,它就能给你输出指法。”
这图,首先大致说明了这个HMM里面有哪些变量:
・HMM中的“Hidden State(隐藏状态)”的是右手的五个手指编号(1=大拇指,2=食指,3=中指,4=无名指,5=小指)。
・HMM的“Emission(可见输出状态链)”是“所弹奏出来的音符”。
在这篇论文的问题描述中,“弹奏的音符”是知道的,“所用的指法”是不知道的。因为不知道,所以就需要用算法去算出来。所以这里和事实上的过程其实是反过来的:在此论文中,“指法”是原因,“音符”是结果,“事情发生”就是“指法导致了弹奏出这些音符”;这个过程在英文版论文中称为“fingering-to-performance conversion”,与事情看起来发生的顺序是相反的(一个人是先看到琴谱,然后才有指法的,这种现实中的发生顺序来说的过程在英文版论文中称为“score-to-fingering conversion”)。此论文中的概率用贝叶斯术语的名字来说就是:
・P(指法)是先验概率(Prior Probability/事前確率=じぜんかくりつ)、
・P(音符|指法)是似然度(Likelihood/尤度関数=ゆうどかんすう)、
・P(音符,指法)是联合概率(Joint Probability/結合確率=けつごうかくりつ)、
・P(音符)是边缘概率(Marginal Probability/周辺確率=しゅうへんかくりつ)、
・P(指法|音符)是后验概率(Posterior Probability/事後確率=じごかくりつ)。【通过改变指法来最大化这个概率的过程,就是MAP,即Maximum A-Posteriori过程,即是Viterbi Search法做的事情。】
然后,它说明了这个HMM的性质:
・这个HMM是一个“Mealy Machine”,因为它是在转换的过程中输出的,而不是当处于某个状态时输出的(在某个状态输出,就应是Moore Machine)。“Mealy Machine”的输出概率函数是关于边的起始结点和终止结点的函数。所以,图右方的“High probability emission”意思是,“当我先用右手无名指弹奏了#F之后,再用右手小指弹奏#F右边的G的概率比较高”;图右下角的“Low probability emission”的意思是,“当我先用右手的无名指弹奏了G之后,再用右手小指弹奏G左边的#F的概率比较低”。
・也就是说,输出某个音符的概率可以写成![P(y_i | (y_{i-1}, f_i, f_{i-1}))]() ,用语言解释就是“在我现在用第f_{i-1}个手指弹奏y_{i-1}这个音时,我接下来要用第f_i个手指奏y_i这个音的概率”。[1]
,用语言解释就是“在我现在用第f_{i-1}个手指弹奏y_{i-1}这个音时,我接下来要用第f_i个手指奏y_i这个音的概率”。[1]
・至于状态转换概率则是不分Moore Machine和Mealy Machine的,都是![P(f_i | f_{i-1})]() ,也就是当前用了某个手指之后,会转而使用下一个手指的概率。这个概率表可以用来对某些现象进行建模,譬如说:“中指和无名指连续交替按键很不灵活”,就可以通过使得赋给
,也就是当前用了某个手指之后,会转而使用下一个手指的概率。这个概率表可以用来对某些现象进行建模,譬如说:“中指和无名指连续交替按键很不灵活”,就可以通过使得赋给![P(f_3|f_4)]() 与
与![P(f_4|f_3)]() 更低的值来达成。
更低的值来达成。
有了这些定义,我们就能知道如何完成HMM中的三个任务:
・Scoring:给定一个指法,通过打分看它好弹还是不好弹。输入是指法,输出是分数。
・Matching:给定一个琴谱,给出最好的指法。输入是琴谱,输出是指法。
・Training:给定琴谱和指法组成的测试用例,通过改变HMM中的参数,来使得这个HMM能“学习”到测试用例中潜藏的规则。
首先是Scoring,就是这个HMM是如何计算某个指法安排出现的概率的,以上面的图为例:
・图中的红箭头经过的结点表示状态转换,也就是“5、2、3、1、4、2、1”。在处于某个状态时,所进行的状态转换只依赖于当前的状态是什么。
・红箭头经过的边表示所输出的可见状态,也就是右上角的音符:E5, B4, C5, A4, B4, #G4, E。
・除了第一个音符以外,其它的音符都是按照上面的输出概率公式计算的。比如说用此指法弹奏第二个B4的条件概率就是![P(B4 | (E5, 2nd, 5th) )]() 。
。
这就是“给定一个指法和所弹奏的音符,计算出它被弹奏出来的概率是多少”的过程。如果只给定音符,再罗列出所有可能的指法,就能从中计算出概率最大的指法。但是直接罗列速度会慢,所以可以用Viterbi Search来更快地计算出来。
那么就来到了第二点,Matching,就是给定一个谱子后,如何知道在当前的HMM中,最好的指法是什么?这是计算最大后验概率 P(指法|音符) 的问题。如前所述这其实是一个通过动态规划来达到比枚举高效很多的编程问题,其基本的样子是从给定的谱子的第一个音符开始,一直往后走,在每一步都保存“弹到当前的音符时最好的指法是什么”的信息供下一步使用,省掉计算时间的。此算法称为Viterbi Search(Viterbi algorithm),它所搜索的空间可称为Trellis Graph (Trellis (graph))。因为维基百科上的Viterbi算法的Python代码是可以直接拷贝下来运行的,为了有所不同,以下就以图中的片段来举个例子,运行一遍论文中所述的演算法(这里强制第一个音符必须用5指,所以开始概率是设成了{0.01, 0.01, 0.01, 0.01, 1.00}):
图中t表示输出状态链的“时间”,也就是音符的下标,从0开始。
当t=0的时候弹奏的概率就是开始概率。t>0时弹奏的概率就涉及输出概率与转换概率。
以下和论文中一样,只考虑只用右手、只有单音(没有和弦)的情况。
<img data-rawheight="392" data-rawwidth="658" src="https://pic3.zhimg.com/a694b1d7f89b5b7e45c77e582552b4be_b.jpg" class="origin_image zh-lightbox-thumb" width="658" data-original="https://pic3.zhimg.com/a694b1d7f89b5b7e45c77e582552b4be_r.jpg">t=[0, 1]时的概率,就表示弹奏前两个音符所用的各种指法的概率。图中的网状图就是一个Trellis graph,每条边对应一次HMM状态转换同时也对应着(在t>0时的)弹出一个音符的动作;每个结点对应着一个手指,也就是能够用以弹奏某个音的某个手指。每条有颜色的路径就表示某个片段中的指法安排。Viterbi算法是一种动态规划,所以它在每一步时都需要把“对于每个手指,从开始到这一步时,这一步必用这个手指的最高的概率和对应的指法”存在动态规划表里,以供下一步的计算使用。 t=[0, 1]时的概率,就表示弹奏前两个音符所用的各种指法的概率。图中的网状图就是一个Trellis graph,每条边对应一次HMM状态转换同时也对应着(在t>0时的)弹出一个音符的动作;每个结点对应着一个手指,也就是能够用以弹奏某个音的某个手指。每条有颜色的路径就表示某个片段中的指法安排。Viterbi算法是一种动态规划,所以它在每一步时都需要把“对于每个手指,从开始到这一步时,这一步必用这个手指的最高的概率和对应的指法”存在动态规划表里,以供下一步的计算使用。
t=[0, 1]时的概率,就表示弹奏前两个音符所用的各种指法的概率。图中的网状图就是一个Trellis graph,每条边对应一次HMM状态转换同时也对应着(在t>0时的)弹出一个音符的动作;每个结点对应着一个手指,也就是能够用以弹奏某个音的某个手指。每条有颜色的路径就表示某个片段中的指法安排。Viterbi算法是一种动态规划,所以它在每一步时都需要把“对于每个手指,从开始到这一步时,这一步必用这个手指的最高的概率和对应的指法”存在动态规划表里,以供下一步的计算使用。
从这个图所反映的动态规划表中可以看出,用右手小拇指弹第一个音E5,然后再用右手食指弹第二个音B4的概率是所有25种可能中概率最高的,其概率高达10^(-2.31009)。这个概率并没有什么实际意义,只在对所有指法间进行比较有意义。相比起来,用右手大拇指弹奏第一个音E5再用右手小拇指弹奏第二个音B4的概率就低多了,只有10^(-13.0603),这是个穿指的动作,而穿指从大拇指穿到小拇指也比从食指、中指和无名指穿到小指要简单,所以指向t=1时的5的箭头是从1指向5的。这是Viterbi算法在构建动态规划表中的规则。
这个表的内容会用到t=[0,1,2]的情况,如下:
<img data-rawheight="285" data-rawwidth="499" src="https://pic1.zhimg.com/a114926515f1fd8ca6cb448faf904938_b.jpg" class="origin_image zh-lightbox-thumb" width="499" data-original="https://pic1.zhimg.com/a114926515f1fd8ca6cb448faf904938_r.jpg">指的就是此图在t=[0,1]中的箭头都是在上一张中出现过的箭头的意思。 指的就是此图在t=[0,1]中的箭头都是在上一张中出现过的箭头的意思。
指的就是此图在t=[0,1]中的箭头都是在上一张中出现过的箭头的意思。
再继续一步:
<img data-rawheight="285" data-rawwidth="502" src="https://pic2.zhimg.com/c6c00a9d5d305db03fa00eedc0ab6c95_b.jpg" class="origin_image zh-lightbox-thumb" width="502" data-original="https://pic2.zhimg.com/c6c00a9d5d305db03fa00eedc0ab6c95_r.jpg">
将这个过程重复到最后,就得到了这一段谱子的指法:
<img data-rawheight="283" data-rawwidth="803" src="https://pic2.zhimg.com/4f3f7f542c3b209ab07d193103048319_b.jpg" class="origin_image zh-lightbox-thumb" width="803" data-original="https://pic2.zhimg.com/4f3f7f542c3b209ab07d193103048319_r.jpg">在这张动态规划表中,概率最大的是[5231421]这个指法,也就是图中所示的。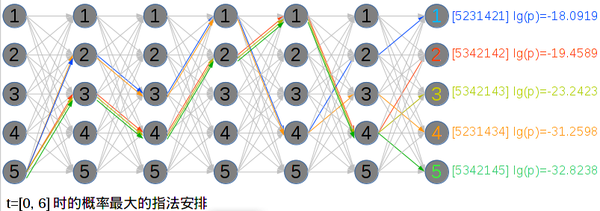 在这张动态规划表中,概率最大的是[5231421]这个指法,也就是图中所示的。
在这张动态规划表中,概率最大的是[5231421]这个指法,也就是图中所示的。
以上就是这篇论文中所描述的“用HMM来计算给定的一段乐谱的最佳指法”的方法。
最后,就是Training阶段——如何通过训练HMM参数的方法来“学到”测试用例呢?
在实现此论文的过程中我对于具体计算输出概率的方法是用了一些猜测的,所以与原文可能有所不符,所以将论文中所出现的7个乐谱片段输入后,有3、4个音符的指法与文中提及的结果不同。所以我想通过调整参数的方法让我的HMM的输出结果能与论文中相符。
说是Bonus阶段是,因为论文中没有明示这一阶段是如何做的,但是有提及根据常理是可以把这个训练过程做成的。
这回用于训练用的是随机梯度下降法(Stochastic gradient descent),这种方法可以用于参数都是连续变量、目标函数也是连续变量的模型。其最基本的更新规则是![w = w - \alpha \nabla p(w)]() ,其中w是参数,alpha是学习速率,p是Viterbi算法算出的最佳指法与训练用例指法的分数之差,当梯度下降完成时,训练用例中的指法就会变成所有指法中最优的并被Viterbi找到,也就是p会等于0 。
,其中w是参数,alpha是学习速率,p是Viterbi算法算出的最佳指法与训练用例指法的分数之差,当梯度下降完成时,训练用例中的指法就会变成所有指法中最优的并被Viterbi找到,也就是p会等于0 。
训练过程中给HMM模型不停地出示正确的指法就像是不停背诵英语单词强化记忆一样。以下示出用论文中出现的7个片段用作训练的样子。训练中能修正的HMM参数有以下这些:
・转换概率(25个)
・五个手指与黑/白键的接触点的Y轴坐标(10个)
一共是35个可以调整的参数。
在训练前,我们猜测出来的参数做成的HMM输出的指法能够符合这7个训练用例中的5个(以下为论文中的谱子的截图,黑色的圈是在论文中用作指法合理性的讨论的,和此回需要进行的重现算法的任务没有关系):
<img data-rawheight="574" data-rawwidth="429" src="https://pic1.zhimg.com/31a8e86dfb2286ac9f726370a1a93624_b.jpg" class="origin_image zh-lightbox-thumb" width="429" data-original="https://pic1.zhimg.com/31a8e86dfb2286ac9f726370a1a93624_r.jpg">
可以看到图中有两处红字是我们当前的HMM输出的指法与训练用例的指法不同之处。现在将这七个片段放入Stochastic Descent过程中,随着其进行,可以将参数的变化和目标函数的变化画在下图中:
<img data-rawheight="964" data-rawwidth="748" src="https://pic2.zhimg.com/6247ceec36a100c1c42519cc72615a01_b.jpg" class="origin_image zh-lightbox-thumb" width="748" data-original="https://pic2.zhimg.com/6247ceec36a100c1c42519cc72615a01_r.jpg">三栏中,最上栏是分数之差,也就是对每个训练用例,给定的训练指法与当前最好的指法的分数之差,为0表示给定的训练指法就是最佳指法。中间栏是转换概率。最下栏是10个接触点的Y轴坐标。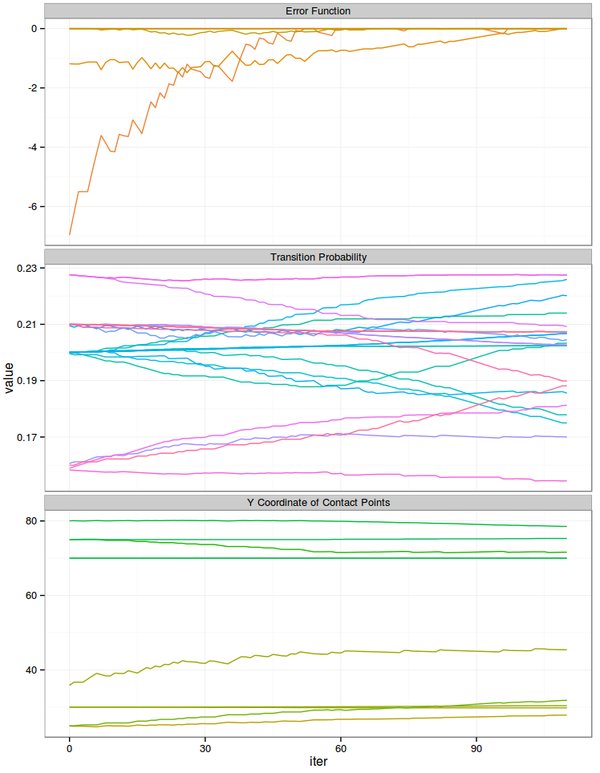 三栏中,最上栏是分数之差,也就是对每个训练用例,给定的训练指法与当前最好的指法的分数之差,为0表示给定的训练指法就是最佳指法。中间栏是转换概率。最下栏是10个接触点的Y轴坐标。
三栏中,最上栏是分数之差,也就是对每个训练用例,给定的训练指法与当前最好的指法的分数之差,为0表示给定的训练指法就是最佳指法。中间栏是转换概率。最下栏是10个接触点的Y轴坐标。
可以看到分数之差随着训练的进行总体上的趋势是在接近0。当训练完成后,这个HMM就能复制出图中所示的7个片段中的指法啦! \^O^/
如果再展开还有许多问题:对于Stochastic Descent还可以通过自动调整学习速率的方法来加快计算;训练过程不一定是Consistent的,意即总会到某个时候不可能完全复制出训练用例中的指法;和弦和双手两个声部的处理,但是这些就是不同于此问题的另一问题了,而且我也不是非常理解,所以就不在这里写啦。
[1]:在重现这篇论文的结果时我们认为尽管原论文并没有说,但是y_{i-1}还是有必要出现在竖线的右边的。按我们的理解,原文并非是完全没有说,而是隐含地用了y_{i-1}来得到计算输出概率时高斯分布的中心点的位置。
这个HMM的应用是来自于東京大学(東大真是所神奇的学校)的一个研究组在IJCAI 2007年的一篇文章,日文版的标题是《隠れマルコフモデルに基づくピアノ運指の自動決定》,英文版的标题是《Automatic Determination of Piano Fingering based on Hidden Markov Model》,论文的网页在这里:Sagayama & Ono Lab。从网页可以知道,这篇文中的工作其实至少从2005年就开始了。
愚以为在我目前能做到的范围内最好的学习一篇论文并让其对自己有用的方法就是重现之,所以此答案也按照现在回看当时重现过程的过程的顺序写。对于这个问题,我觉得比较重要的一点是“如何将HMM模型套用到这个问题上”,什么是HMM中的“因”,什么是HMM中的“果”,这个HMM在解决与琴键指法有关的问题是如何对应到HMM的三大任务=Scoring, Matching, Training的。然后你就很容易知道问题的输入是什么、输出是什么,然后将其转化为一个用程序员思维能解决的问题。
所以就开始俺们的钢琴运指自动决定之旅吧:
为了先有一个印象并明确问题的背景和定义,先看开门见山的介绍图:
<img data-rawheight="338" data-rawwidth="450" src="https://pic1.zhimg.com/7499958e318dbb13f88a64fb74678794_b.jpg" class="origin_image zh-lightbox-thumb" width="450" data-original="https://pic1.zhimg.com/7499958e318dbb13f88a64fb74678794_r.jpg">
这个图的意思是说,“你有一个HMM模型,往里面丢入琴谱,它就能给你输出指法。”
这图,首先大致说明了这个HMM里面有哪些变量:
・HMM中的“Hidden State(隐藏状态)”的是右手的五个手指编号(1=大拇指,2=食指,3=中指,4=无名指,5=小指)。
・HMM的“Emission(可见输出状态链)”是“所弹奏出来的音符”。
在这篇论文的问题描述中,“弹奏的音符”是知道的,“所用的指法”是不知道的。因为不知道,所以就需要用算法去算出来。所以这里和事实上的过程其实是反过来的:在此论文中,“指法”是原因,“音符”是结果,“事情发生”就是“指法导致了弹奏出这些音符”;这个过程在英文版论文中称为“fingering-to-performance conversion”,与事情看起来发生的顺序是相反的(一个人是先看到琴谱,然后才有指法的,这种现实中的发生顺序来说的过程在英文版论文中称为“score-to-fingering conversion”)。此论文中的概率用贝叶斯术语的名字来说就是:
・P(指法)是先验概率(Prior Probability/事前確率=じぜんかくりつ)、
・P(音符|指法)是似然度(Likelihood/尤度関数=ゆうどかんすう)、
・P(音符,指法)是联合概率(Joint Probability/結合確率=けつごうかくりつ)、
・P(音符)是边缘概率(Marginal Probability/周辺確率=しゅうへんかくりつ)、
・P(指法|音符)是后验概率(Posterior Probability/事後確率=じごかくりつ)。【通过改变指法来最大化这个概率的过程,就是MAP,即Maximum A-Posteriori过程,即是Viterbi Search法做的事情。】
然后,它说明了这个HMM的性质:
・这个HMM是一个“Mealy Machine”,因为它是在转换的过程中输出的,而不是当处于某个状态时输出的(在某个状态输出,就应是Moore Machine)。“Mealy Machine”的输出概率函数是关于边的起始结点和终止结点的函数。所以,图右方的“High probability emission”意思是,“当我先用右手无名指弹奏了#F之后,再用右手小指弹奏#F右边的G的概率比较高”;图右下角的“Low probability emission”的意思是,“当我先用右手的无名指弹奏了G之后,再用右手小指弹奏G左边的#F的概率比较低”。
・也就是说,输出某个音符的概率可以写成
・至于状态转换概率则是不分Moore Machine和Mealy Machine的,都是
有了这些定义,我们就能知道如何完成HMM中的三个任务:
・Scoring:给定一个指法,通过打分看它好弹还是不好弹。输入是指法,输出是分数。
・Matching:给定一个琴谱,给出最好的指法。输入是琴谱,输出是指法。
・Training:给定琴谱和指法组成的测试用例,通过改变HMM中的参数,来使得这个HMM能“学习”到测试用例中潜藏的规则。
首先是Scoring,就是这个HMM是如何计算某个指法安排出现的概率的,以上面的图为例:
・图中的红箭头经过的结点表示状态转换,也就是“5、2、3、1、4、2、1”。在处于某个状态时,所进行的状态转换只依赖于当前的状态是什么。
・红箭头经过的边表示所输出的可见状态,也就是右上角的音符:E5, B4, C5, A4, B4, #G4, E。
・除了第一个音符以外,其它的音符都是按照上面的输出概率公式计算的。比如说用此指法弹奏第二个B4的条件概率就是
这就是“给定一个指法和所弹奏的音符,计算出它被弹奏出来的概率是多少”的过程。如果只给定音符,再罗列出所有可能的指法,就能从中计算出概率最大的指法。但是直接罗列速度会慢,所以可以用Viterbi Search来更快地计算出来。
那么就来到了第二点,Matching,就是给定一个谱子后,如何知道在当前的HMM中,最好的指法是什么?这是计算最大后验概率 P(指法|音符) 的问题。如前所述这其实是一个通过动态规划来达到比枚举高效很多的编程问题,其基本的样子是从给定的谱子的第一个音符开始,一直往后走,在每一步都保存“弹到当前的音符时最好的指法是什么”的信息供下一步使用,省掉计算时间的。此算法称为Viterbi Search(Viterbi algorithm),它所搜索的空间可称为Trellis Graph (Trellis (graph))。因为维基百科上的Viterbi算法的Python代码是可以直接拷贝下来运行的,为了有所不同,以下就以图中的片段来举个例子,运行一遍论文中所述的演算法(这里强制第一个音符必须用5指,所以开始概率是设成了{0.01, 0.01, 0.01, 0.01, 1.00}):
图中t表示输出状态链的“时间”,也就是音符的下标,从0开始。
当t=0的时候弹奏的概率就是开始概率。t>0时弹奏的概率就涉及输出概率与转换概率。
以下和论文中一样,只考虑只用右手、只有单音(没有和弦)的情况。
<img data-rawheight="392" data-rawwidth="658" src="https://pic3.zhimg.com/a694b1d7f89b5b7e45c77e582552b4be_b.jpg" class="origin_image zh-lightbox-thumb" width="658" data-original="https://pic3.zhimg.com/a694b1d7f89b5b7e45c77e582552b4be_r.jpg">t=[0, 1]时的概率,就表示弹奏前两个音符所用的各种指法的概率。图中的网状图就是一个Trellis graph,每条边对应一次HMM状态转换同时也对应着(在t>0时的)弹出一个音符的动作;每个结点对应着一个手指,也就是能够用以弹奏某个音的某个手指。每条有颜色的路径就表示某个片段中的指法安排。Viterbi算法是一种动态规划,所以它在每一步时都需要把“对于每个手指,从开始到这一步时,这一步必用这个手指的最高的概率和对应的指法”存在动态规划表里,以供下一步的计算使用。
t=[0, 1]时的概率,就表示弹奏前两个音符所用的各种指法的概率。图中的网状图就是一个Trellis graph,每条边对应一次HMM状态转换同时也对应着(在t>0时的)弹出一个音符的动作;每个结点对应着一个手指,也就是能够用以弹奏某个音的某个手指。每条有颜色的路径就表示某个片段中的指法安排。Viterbi算法是一种动态规划,所以它在每一步时都需要把“对于每个手指,从开始到这一步时,这一步必用这个手指的最高的概率和对应的指法”存在动态规划表里,以供下一步的计算使用。从这个图所反映的动态规划表中可以看出,用右手小拇指弹第一个音E5,然后再用右手食指弹第二个音B4的概率是所有25种可能中概率最高的,其概率高达10^(-2.31009)。这个概率并没有什么实际意义,只在对所有指法间进行比较有意义。相比起来,用右手大拇指弹奏第一个音E5再用右手小拇指弹奏第二个音B4的概率就低多了,只有10^(-13.0603),这是个穿指的动作,而穿指从大拇指穿到小拇指也比从食指、中指和无名指穿到小指要简单,所以指向t=1时的5的箭头是从1指向5的。这是Viterbi算法在构建动态规划表中的规则。
这个表的内容会用到t=[0,1,2]的情况,如下:
<img data-rawheight="285" data-rawwidth="499" src="https://pic1.zhimg.com/a114926515f1fd8ca6cb448faf904938_b.jpg" class="origin_image zh-lightbox-thumb" width="499" data-original="https://pic1.zhimg.com/a114926515f1fd8ca6cb448faf904938_r.jpg">指的就是此图在t=[0,1]中的箭头都是在上一张中出现过的箭头的意思。
指的就是此图在t=[0,1]中的箭头都是在上一张中出现过的箭头的意思。再继续一步:
<img data-rawheight="285" data-rawwidth="502" src="https://pic2.zhimg.com/c6c00a9d5d305db03fa00eedc0ab6c95_b.jpg" class="origin_image zh-lightbox-thumb" width="502" data-original="https://pic2.zhimg.com/c6c00a9d5d305db03fa00eedc0ab6c95_r.jpg">
将这个过程重复到最后,就得到了这一段谱子的指法:
<img data-rawheight="283" data-rawwidth="803" src="https://pic2.zhimg.com/4f3f7f542c3b209ab07d193103048319_b.jpg" class="origin_image zh-lightbox-thumb" width="803" data-original="https://pic2.zhimg.com/4f3f7f542c3b209ab07d193103048319_r.jpg">在这张动态规划表中,概率最大的是[5231421]这个指法,也就是图中所示的。
在这张动态规划表中,概率最大的是[5231421]这个指法,也就是图中所示的。以上就是这篇论文中所描述的“用HMM来计算给定的一段乐谱的最佳指法”的方法。
最后,就是Training阶段——如何通过训练HMM参数的方法来“学到”测试用例呢?
在实现此论文的过程中我对于具体计算输出概率的方法是用了一些猜测的,所以与原文可能有所不符,所以将论文中所出现的7个乐谱片段输入后,有3、4个音符的指法与文中提及的结果不同。所以我想通过调整参数的方法让我的HMM的输出结果能与论文中相符。
说是Bonus阶段是,因为论文中没有明示这一阶段是如何做的,但是有提及根据常理是可以把这个训练过程做成的。
这回用于训练用的是随机梯度下降法(Stochastic gradient descent),这种方法可以用于参数都是连续变量、目标函数也是连续变量的模型。其最基本的更新规则是
训练过程中给HMM模型不停地出示正确的指法就像是不停背诵英语单词强化记忆一样。以下示出用论文中出现的7个片段用作训练的样子。训练中能修正的HMM参数有以下这些:
・转换概率(25个)
・五个手指与黑/白键的接触点的Y轴坐标(10个)
一共是35个可以调整的参数。
在训练前,我们猜测出来的参数做成的HMM输出的指法能够符合这7个训练用例中的5个(以下为论文中的谱子的截图,黑色的圈是在论文中用作指法合理性的讨论的,和此回需要进行的重现算法的任务没有关系):
<img data-rawheight="574" data-rawwidth="429" src="https://pic1.zhimg.com/31a8e86dfb2286ac9f726370a1a93624_b.jpg" class="origin_image zh-lightbox-thumb" width="429" data-original="https://pic1.zhimg.com/31a8e86dfb2286ac9f726370a1a93624_r.jpg">
可以看到图中有两处红字是我们当前的HMM输出的指法与训练用例的指法不同之处。现在将这七个片段放入Stochastic Descent过程中,随着其进行,可以将参数的变化和目标函数的变化画在下图中:
<img data-rawheight="964" data-rawwidth="748" src="https://pic2.zhimg.com/6247ceec36a100c1c42519cc72615a01_b.jpg" class="origin_image zh-lightbox-thumb" width="748" data-original="https://pic2.zhimg.com/6247ceec36a100c1c42519cc72615a01_r.jpg">三栏中,最上栏是分数之差,也就是对每个训练用例,给定的训练指法与当前最好的指法的分数之差,为0表示给定的训练指法就是最佳指法。中间栏是转换概率。最下栏是10个接触点的Y轴坐标。
三栏中,最上栏是分数之差,也就是对每个训练用例,给定的训练指法与当前最好的指法的分数之差,为0表示给定的训练指法就是最佳指法。中间栏是转换概率。最下栏是10个接触点的Y轴坐标。可以看到分数之差随着训练的进行总体上的趋势是在接近0。当训练完成后,这个HMM就能复制出图中所示的7个片段中的指法啦! \^O^/
如果再展开还有许多问题:对于Stochastic Descent还可以通过自动调整学习速率的方法来加快计算;训练过程不一定是Consistent的,意即总会到某个时候不可能完全复制出训练用例中的指法;和弦和双手两个声部的处理,但是这些就是不同于此问题的另一问题了,而且我也不是非常理解,所以就不在这里写啦。
[1]:在重现这篇论文的结果时我们认为尽管原论文并没有说,但是y_{i-1}还是有必要出现在竖线的右边的。按我们的理解,原文并非是完全没有说,而是隐含地用了y_{i-1}来得到计算输出概率时高斯分布的中心点的位置。
0 0
- 如何用简单易懂的例子解释隐马尔可夫模型?
- 如何用简单易懂的例子解释隐马尔可夫模型?
- 如何用简单易懂的例子解释隐马尔可夫模型?
- 如何用简单易懂的例子解释隐马尔可夫模型?
- 如何用简单易懂的例子解释隐马尔可夫模型?
- 如何用简单易懂的例子解释隐马尔可夫模型?
- 如何用简单易懂的例子解释隐马尔可夫模型?
- 如何用简单易懂的例子解释隐马尔可夫模型?
- 简单易懂的例子解释隐马尔可夫模型
- 用简单易懂的例子解释隐马尔可夫模型
- 如何用R发送简单易懂的邮件
- 简单易懂的行转列例子
- 一个简单易懂的例子
- 简单易懂的hibernate例子
- 简单易懂的spring例子
- 简单易懂的hibernate例子
- https最简单易懂的解释
- c#接口简单易懂的一个例子
- 如何用简单易懂的例子解释隐马尔可夫模型?
- 手机抓包方法
- eclipse 中间的编辑代码区域显示与取消空格等特殊符号
- UIWebView 无缝切换到 WKWebView
- OpenGL笔记
- 如何用简单易懂的例子解释隐马尔可夫模型?
- 欢迎使用CSDN-markdown编辑器
- document 获得元素节点,属性节点,文本节点
- 软件自动化测试框架
- SOJ4513: 先锋看烟花 单调队列优化DP
- js闭包剖析
- 关闭Cadence Orcad Capture CIS原理图弹出startpage页面的方法
- 用Java语言求证 辗转相除法
- 新人千万不要在 Windows 上使用 Ruby on Rails


