Spark Mllib 回归学习笔记二(java):保序回归
来源:互联网 发布:rxjava 知乎 编辑:程序博客网 时间:2024/04/25 22:02
spark2.0.0
保序回归(isotonic regression)
保序回归属于回归算法,对于一个有限的实数集合Y表示观测相应,X集合表示未知的相应值,进行拟合找到一个最小化函数:

x是排序的,w是大于0的权重,最终函数被称为保序回归,并且是唯一的。可以看作排序限制下的最小二乘问题。
观察上面的公式,发现减数已不再是y而是x,事实上,保序回归并不假定一条函数,他是将原来的x进行调整,看下面这个动画: 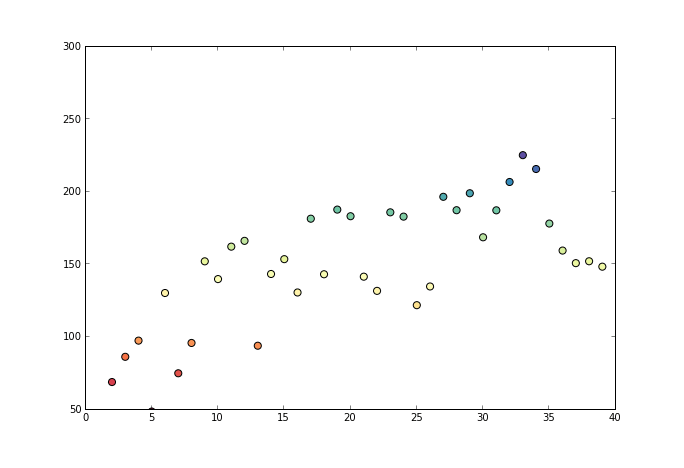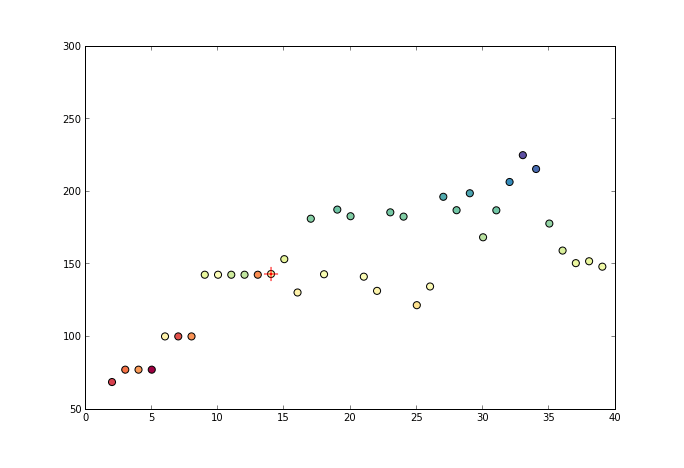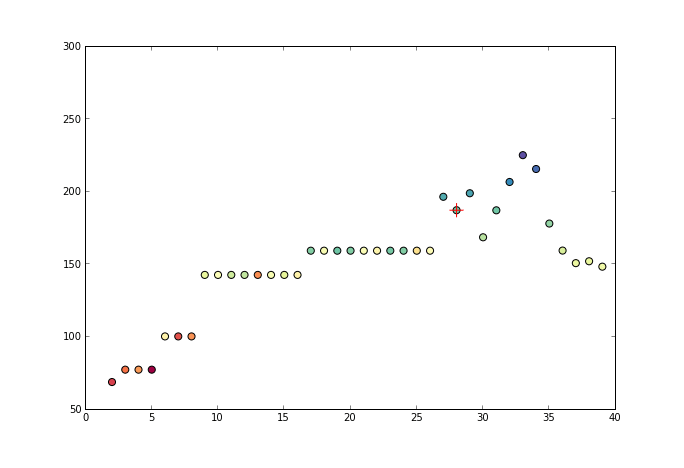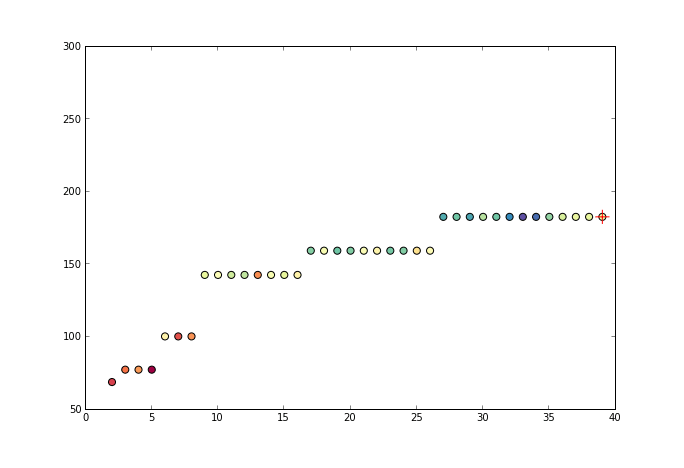
Mllib支持的算法平行化保序回归,有一个参数isotonic,默认true,意为单调递增。
保序回归的结果被视为分段线性函数 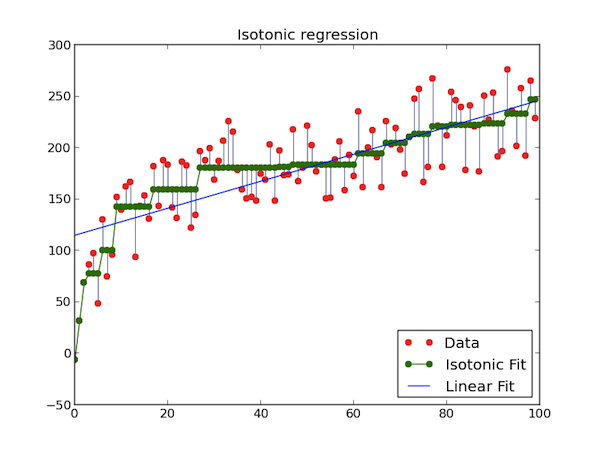
预测的规则是:
- 如果预测输入能准确匹配训练特征,那么返回相关预测,如果有多个预测匹配训练特征,那么就返回其中之一。
- 如果预测输入比所有的训练特征低或者高,那么最低和最高的训练特征各自返回。如果有多个预测比所有的训练特征低或者高,那么都会返回。
- 如果预测输入介于两个训练特征,那么预测会被视为分段线性函数和从最接近的训练特征中计算得到的插值。
实例
操作数据
package linear;import org.apache.spark.SparkConf;import org.apache.spark.api.java.JavaDoubleRDD;import org.apache.spark.api.java.JavaPairRDD;import org.apache.spark.api.java.JavaRDD;import org.apache.spark.api.java.JavaSparkContext;import org.apache.spark.api.java.function.Function;import org.apache.spark.api.java.function.PairFunction;import org.apache.spark.mllib.regression.IsotonicRegressionModel;import org.apache.spark.mllib.regression.LabeledPoint;import org.apache.spark.mllib.util.MLUtils;import scala.Tuple2;import scala.Tuple3;public class IsotonicRegression { /** * @param yinglish_ */ public static void main(String[] args) { // TODO Auto-generated method stub SparkConf sparkConf = new SparkConf().setAppName("Regresion").setMaster("local[*]"); JavaSparkContext jsc = new JavaSparkContext(sparkConf); //一、加载读取文件,转化为javaRDD JavaRDD<LabeledPoint> data = MLUtils.loadLibSVMFile(jsc.sc(), "/home/monkeys/sample_isotonic_regression_libsvm_data.txt").toJavaRDD(); //二、操作数据,使其变成标签、特征、权重(设置为1)的输入形式 JavaRDD<Tuple3<Double, Double, Double>> parsedData = data.map( new Function<LabeledPoint, Tuple3<Double, Double, Double>>(){ public Tuple3<Double, Double, Double> call(LabeledPoint point){ return new Tuple3<Double, Double, Double>(new Double(point.label()), new Double(point.features().apply(0)), 1.0); } } ); //三、把数据六四分,六成做训练集 JavaRDD<Tuple3<Double, Double, Double>>[] splits = parsedData.randomSplit(new double[]{0.6, 0.4}, 11L); JavaRDD<Tuple3<Double, Double, Double>> training = splits[0]; JavaRDD<Tuple3<Double, Double, Double>> test = splits[1]; //四、训练模型 final IsotonicRegressionModel model = new IsotonicRegression().fit(training); //五、计算误差 JavaPairRDD<Double, Double> predictionAndLabel = test.mapToPair( new PairFunction<Tuple3<Double, Double, Double>, Double, Double>(){ //@Override public Tuple2<Double, Double> call (Tuple3<Double, Double, Double> point){ Double predictedLabel = model.predict(point._2()); return new Tuple2<Double, Double>(predictedLabel, point._1());//predictedLabel是模型预测出来的标签, point._1是原始真实标签 } } ); Double meanSquaredError = new JavaDoubleRDD(predictionAndLabel.map( new Function<Tuple2<Double, Double>, Object>(){ //@Override public Object call(Tuple2<Double, Double> pl){ return Math.pow(pl._1() - pl._2(), 2); } } ).rdd()).mean(); System.out.println("Mean Squared Error = " + meanSquaredError); } private IsotonicRegressionModel fit( JavaRDD<Tuple3<Double, Double, Double>> training) { // TODO Auto-generated method stub return null; }}参考资料
官方文档
原献作者博客
1 0
- Spark Mllib 回归学习笔记二(java):保序回归
- Spark Mllib 回归学习笔记一(java):线性回归(线性,lasso,岭),广义回归
- Spark Mllib 回归学习笔记三(java):决策树
- Spark中组件Mllib的学习41之保序回归(Isotonic regression)
- Spark MLlib学习(二)——分类和回归
- 保序回归算法原理及Spark MLlib调用实例(Scala/Java/python)
- spark之MLlib机器学习-线性回归
- MLlib回归算法(线性回归、决策树)实战演练--Spark学习(机器学习)
- spark mllib实现线性回归
- Spark MLlib logistic回归案例
- spark&pthon MLlib逻辑回归
- Spark MLlib之线性回归
- 保序回归(isotonic_regression)
- spark mllib源码分析之二分类逻辑回归evaluation
- Scala语言 + Spark MLLib进行机器学习---线性回归
- spark MLlib、ML机器学习之Logistic回归
- spark mllib源码分析之逻辑回归弹性网络ElasticNet(二)
- 回归算法学习笔记(二)局部加权线性回归
- java中利用JOptionPane类弹出消息框的部分例子
- 【HDU 5908 || #bestcoder88 1002】【map的应用 暴力】Abelian Period
- mvc的制作简单的配置加载类和日志类
- bestcoder#round88
- 编辑器ueditor
- Spark Mllib 回归学习笔记二(java):保序回归
- STM32通用定时器配置
- 用JAVA求两个数的最大公约数
- 面向对象_方法重写的注意事项
- 深入浅出MySQL(5)-基本数据类型
- POJ 3026 Borg Maze(bfs+最小生成树)
- Spark Mllib 回归学习笔记三(java):决策树
- js二分法排序代码分享
- 框架入门 中级篇 (上)配置类和日志类


