《大数据原理与实践》第2次公开课:Concept
来源:互联网 发布:薪酬调查数据分析 编辑:程序博客网 时间:2024/04/19 18:25
本次课程主要介绍大数据的基本概念,主要包括如下几个方面的内容:
大数据全景图
从IT时代到DT时代
大数据洞见(insight)
大数据技术框架
数据科学与数据工程
半个世纪以来,随着计算机技术全面融入社会生活,信息爆炸已经积累到了一个开始引发变革的程度。它不仅使世界充斥着比以往更多的信息,而且其增长速度也在加快。互联网(社交、搜索、电商)、移动互联网(微博)、物联网(传感器,智慧地球)、车联网、GPS、医学影像、安全监控、金融(银行、股市、保险)、电信(通话、短信)都在疯狂产生着数据。
这是我们目前正在经历着的云计算、移动互联网和物联网时代。接下来就是机器智能时代,现在开始发生,对社会的影响会更加深刻。而且这个机器智能是基于大数据的机器智能,虽然目前还没有太形成规模,但一定会发生,势不可挡。我们的人类社会也即将发生翻天覆地的变化,而这种变化就是来自于大数据量的积累和对大数据的持续开发所达到的一种质变的奇点。
其实在工业革命之前(1820年),世界人均 GDP在1800年前的两三千年里基本没有变化,而从1820年到2001年的180年里,世界人均GDP从原来的667美元增长到6049美元。由此足见,工业革命带来的收入增长的确是翻天覆地的。这就技术革命带来的量变到质变的变化。
人类的进步并没有因此而停止,在发明了电力,电脑,互联网,移动互联网,全球年GDP 增长从万分之5到百分之2。在计算机时代,有个著名的摩尔定律,就是说同样成本每隔18个月晶体管数量会翻倍,反过来同样数量晶体管成本会减半,这个规律已经很好地吻合了最近30年的发展,并且可以衍生到很多类似的领域:存储、功耗、带宽、像素。
摩尔定律这种指数级增长规律使得大多数的人们理解起来相当困难。人类的感知是线性的,但技术的发展是指数型的。我们的大脑固守着线性的期望,因为这是它过去累积的经验。然而今天的技术进展日新月异,过去与今天不能同日而语,而今天也永远赶不上未来的步伐。于是,我们突然间发现,自己身处一个完全意想不到的世界里。von Neumann是20世纪最重要的数学家之一,在现代计算机、博弈论和核武器等诸多领域内有杰出建树的最伟大的科学全才之一。他提出:(技术)将会逼近人类历史上的某种本质的奇点,在那之后全部人类行为都不可能以我们熟悉的面貌继续存在。这就是著名的奇点理论。
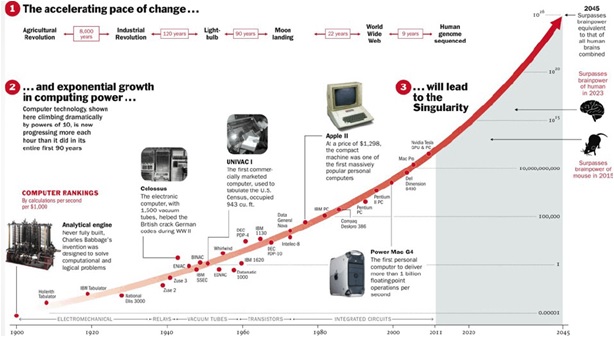
有个著名的论断很好的诠释了这一点:人们总是高估现在,而低估未来。今天,我们依然倾向于低估即将到来的一切,因为要真正发自内心地理解这个指数型技术增长的世界,是相当困难的。
这一点在大数据的时代似乎更加明显。信息也是在急剧增长,根据计算,2006年,个人用户才刚刚迈进TB时代,全球一共新产生了约180EB的数据;到2011年,这个数字就达到了1.8ZB;而预计到2020年,整个世界的数据总量将会增长44倍,达到35.2ZB(1ZB=10亿TB)。最近两年的信息量是之前30年的总和,最近10年则远超人类所有之前累计信息量之和!
国外有个Data Never Sleeps的项目,今年发布了他们的第4个版本,告诉你这个世界上的诸多信息服务每分钟能够产生多大的数据量。

从2008年开始,Nature和Science等国际顶级学术刊物相继出版专刊来专门探讨对大数据的研究。2008年Nature出版专刊“Big Data”,从互联网技术、网络经济学、超级计算、环境科学、生物医药等多个方面介绍了海量数据带来的挑战。2011年Science推出关于数据处理的专刊“Dealing with data”,讨论了数据洪流(Data Deluge)所带来的挑战,特别指出,倘若能够更有效地组织和使用这些数据,人们将得到更多的机会发挥科学技术对社会发展的巨大推动作用。2012年4月欧洲信息学与数学研究协会会刊ERCIM News出版专刊“Big Data”,讨论了大数据时代的数据管理、数据密集型研究的创新技术等问题,并介绍了欧洲科研机构开展的研究活动和取得的创新性进展。2012年3月,美国公布了“大数据研发计划”。该计划旨在提高和改进人们从海量和复杂的数据中获取知识的能力,进而加速美国在科学与工程领域发明的步伐,增强国家安全。该计划还强调,大数据技术事关美国国家安全、科学和研究的步伐,将引发教育和学习的变革。
我国在这样的大背景下,2012年5月,香山科学会议组织了以“大数据科学与工程——一门新兴的交叉学科?”为主题的学术讨论会,来自国内外横跨IT、经济、管理、社会、生物等多个不同学科领域的专家代表参会,并就大数据的理论与工程技术研究、应用方向以及大数据研究的组织方式与资源支持形式等重要问题进行了深入讨论。随即,也是2012年,国家重点基础研究发展计划(973 计划)专家顾问组在前期项目部署的基础上,将大数据基础研究列为信息科学领域4个战略研究主题之一。2014年,科技部基础研究司在北京组织召开“大数据科学问题”研讨会,围绕973计划大数据研究布局、中国大数据发展战略、国外大数据研究框架与重点、大数据研究关键科学问题、重要研究内容和组织实施路线图等展开研讨。
2015年8月,国务院发布《促进大数据发展行动纲要》(以下简称为《纲要》),这是指导中国大数据发展的国家顶层设计和总体部署。《纲要》明确指出了大数据的重要意义,大数据成为推动经济转型发展的新动力、重塑国家竞争优势的新机遇、提升政府治理能力的新途径。《纲要》的出台,进一步凸显大数据在提升政府治理能力、推动经济转型升级中的关键作用。“数据兴国”和“数据治国”已上升为国家战略,将成为中国今后相当长时期的国策。未来,大数据将在稳增长、促改革、调结构、惠民生中发挥越来越重要的作用。
2016年,国家发改委正式印发《关于组织实施促进大数据发展重大工程的通知》(以下简称《通知》)。《通知》称,将重点支持大数据示范应用、共享开放、基础设施统筹发展,以及数据要素流通。《通知》还提到的关键词包括:大数据开放计划、大数据全民创新竞赛、公共数据共享开放平台体系、绿色数据中心、大数据交易等等。
数据量的爆炸式增长不但改变了人们的生活方式、企业的运营模式、以及国家的整体战略,也改变了科学研究的基本范式。
图灵奖得主,关系型数据库的鼻祖JimGray在2007年加州山景城召开的NRC-CSTB大会上,发表了留给世人的最后一次演讲“The Fourth Paradigm: Data-Intensive Scientific Discovery”,提出将科学研究的第四类范式。其中的“数据密集型”就是现在我们所称之为的“大数据”。Jim总结出科学研究的范式共有四个:
几千年前,是经验科学,主要用来描述自然现象;
几百年前,是理论科学,使用模型或归纳法进行科学研究;
几十年前,是计算科学,主要模拟复杂的现象;
今天,是数据科学,统一于理论、实验和模拟。它的主要特征是:数据依靠信息设备收集或模拟产生,依靠软件处理,用计算机进行存储,使用专用的数据管理和统计软件进行分析。
随着数据的爆炸性增长,计算机将不仅仅能做模拟仿真,还能进行分析总结,得到理论。数据密集范式理应从第三范式中分离出来,成为一个独特的科学研究范式。也就是说,过去由牛顿、爱因斯坦等科学家从事的工作,未来完全可以由计算机来做。这种科学研究的方式,被称为第四范式:数据密集型科学。数据密集型科学由传统的假设驱动向基于科学数据进行探索的科学方法的转变。传统的科学研究先提出可能的理论,再搜集数据,然后通过计算来验证。而基于大数据的第四范式,则是先有了大量的已知数据,然后通过计算得出之前未知的理论。
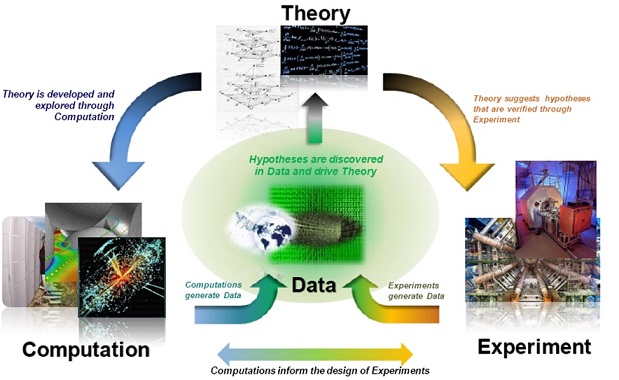
大数据时代最大的转变,就是放弃对因果关系的渴求,取而代之关注相关关系。也就是说,只要知道“是什么”,而不需要知道“为什么”。这就颠覆了千百年来人类的思维惯例,据称是对人类的认知和与世界交流的方式提出了全新的挑战。因为人类总是会思考事物之间的因果联系,而对基于数据的相关性并不是那么敏感;相反,电脑则几乎无法自己理解因果,而对相关性分析极为擅长。这样我们就能理解了,第三范式是“人脑 + 电脑”,人脑是主角;而第四范式是“电脑 + 人脑”,电脑是主角。进而由此引发的新一代人工智能技术。
有了上面的介绍,我们来看看大数据的相关定义。和很多新鲜事物一样,目前对大数据还没有一个公认的完整定义。可以先来看看几个典型的代表:
麦肯锡研究院对大数据定义为:所涉及的数据集规模已经超过了传统数据库软件获取、存储、管理和分析的能力。
维基百科给出的大数据定义为:数据量规模巨大到无法通过人工,在合理时间内达到截取、管理、处理并整理成为人类所能解读的信息。
IBM则用4个特征相结合来定义大数据:数量(Volume)、种类多样(Variety)、速度(Velocity)和真实(Veracity)。
互动百科和国家数据公司IDC也提出4个特征来定义大数据,但与IBM定义不同的地方,将第4个特征由真实(Veracity)替换为价值(Value)。
上述定义都有一定的道理,特别是4V定义,非常方便记忆,目前已经被越来越多地接受。但很多时候也会带来一些误解。例如,大数据最明显的特征是体量大,但仅仅是大量的数据并不一定是大数据。
那我们就从这个“大”字入手,大数据中的“大”究竟指什么?
其实,是可以通过分析它的英文名称来理解的。英语课里常见的表示大的单词有两个:large和big,它们都是大的意思。那为什么大数据使用“big data”而不是“large data”呢?而且,在大数据的概念被提出之前,有很多关于大量数据方面的研究,如果你去看,会发现这些研究领域里面的很多文献中,往往采用 large或者vast(海量)这样的英文单词,而不是big。例如,数据库领域著名国际会议VLDB(即Very Large Data Bases),里面就是用的large。
那么,big,large和vast到底有些什么差别呢?large和vast比较好说,程度上的差别,后者可以看成是very large的意思。而big和它们的区别在于,big更强调的是相对大小的大,是抽象意义上的大;而large和vast常常用于形容体量的大小。比如,large table常常表示的是一张尺寸非常大的桌子;而如果用big table,则表示这不是一张小的桌子,至于尺寸是否真的很大倒不一定,这种说法是要强调相对很大了,是一种抽象的说法。
因此,如果你仔细推敲这种big data的说法,就会发现这种提法还是非常准确的,它传递出来最重要的信息就是大数据是一种抽象的大,是一种思维方式上的转变。现在的数据量比过去大了很多,量变带来质变,思维方式,方法论都应该和以往不同。这个可以看成是帮助我们理解大数据的一把钥匙。
所以,前面关于大数据的一个常见定义就显得很有道理了:Big Data is data that is too large, complex and dynamic for anyconventional data tools to capture, store, manage and analyze. 可以较容易看出,这里的“大”就是一个相对概念,相对于传统数据工具无法捕获、存储、管理和分析的数据。再例如,在有大数据之前,计算机并不能很好解决人工智能中的诸多问题,但如果我们换个思路,利用大数据,这样在某些领域(例如围棋)就可以突破性解决了,其核心问题变成了数据问题。
接下来就要看看大数据到底有哪些关键与本质的特征,我们总结了如下四个特征:
多维度:特征维度多
完备性:全面性,全局数据
关联性:数据间的关联性
不确定性:数据的真实性难以确定,噪音
1、多维度
数据的多维度往往代表了一个事物的多种属性,很多时候也代表了人们看待一个事物的不同角度,是大数据的一个本质特征之一。
例如,百度曾经发布过一个比较有意思的统计结果:《中国十大“吃货”省市排行榜》。百度在没有做任何问卷调查和深入研究的情况下,只是从“百度知道”的7700万条与吃有关的问题中,挖掘出一些结论,反而比很多的学术研究更能反映问题。百度知道的数据维度很多,它们不仅涉及食物的做法、吃法、成分、营养价值、价格、问题来源地、时间等显性维度,而且还蕴藏着很多别人不太注意的隐含信息,例如提问或回答者的终端设备、浏览器类型等。虽然这些信息看上去“杂乱无章”,但实际上正是这些杂乱无章的数据将原来看似无关的维度联系起来了。经过对这些信息的挖掘、加工和整理,就能得到很有意义的规律统计。而且,这些信息中能够挖掘出的大家感兴趣的信息,远比大家想象的要多。
2、完备性
大数据的完备性,或者说全面性,代表了大数据的另外一个本质特征,而且在很多问题场景下是非常有效的。例如,Google的机器翻译系统就是利用了大数据的完备性。它通过数据学到了不同语言之间很长的句子成分的对应,然后直接把一种语言翻译成另一类,前提条件就是使用的数据必须是比较全面地覆盖中文、英文,以及其他的各种语言的所有句子,然后通过机器学习,获得两种语言之间各种说法de翻译方法,也就是说具备两种语言之间翻译的完备性。我们知道Google是目前互联网数据的最大拥有者,随着人类活动与互联网的密不可分,Google所能积累的大数据将会越来越晚辈,它的机器翻译系统也就自然越来越准确了。
当然,传统上,数据的完备性往往难以获得,但是在大数据时代,至少在局部数据的完备性上,还是越来越有可能的。利用局部完备性,也可以有效解决不少问题。
3、关联性
大数据研究不同于传统的逻辑推理研究,而是对数量巨大的数据做统计性的搜索、比较、聚类、分类等分析归纳,因此继承了统计科学的一些特点。统计学关注数据的关联性或相关性称,所谓“关联性”是指两个或两个以上变量的取值之间存在某种规律性。“相关分析”的目的是找出数据集里隐藏的相互关系网,一般用支持度、可信度、兴趣度等参数反映相关性。两个数据A和B有相关性,只有反映A和B在取值时相互有影响,并不能告诉我们有A就一定有B,或者反过来有B就一定有A。严格来讲,统计学无法检验逻辑上的因果关系。例如,根据统计结果:可以说“吸烟的人群肺癌发病率会比不吸烟的人群高几倍”,但统计结果无法得出“吸烟致癌”的逻辑结论。统计学的相关性有时可能会产生把结果当成原因的错觉。如,统计结果表明:下雨之前常见到燕子低飞,从时间先后看两者的关系可能得出燕子低飞是下雨的原因,而事实上,将要下雨才是燕子低飞的原因。
大数据时代,数据之间的相关性在某种程度上取代原来的因果关系,让我们从大量的数据中直接找到答案,即使不知道原因,是大数据的本质特征之一。
4、不确定性
最后是大数据的不确定性。大数据的不确定性最根本的原因是我们的这个世界是不确定的,当然也有技术的不成熟、人为的失误等因素。总的来说,大数据往往是不准确,并充满噪音的。虽然是这样,由于大数据的体量大、维度多、关联性强等特征,使得大数据相对于传统数据有着很大的优势,使得我们能够用不确定的眼光看待世界,再用信息来消除这种不确定性。当然,提高大数据的质量,消除大数据的噪音是开发和利用大数据的一个永恒话题。
大数据的其他一些特征,很多文献都说得比较多了,这里就不一一详细阐述了,主要包括:
体量大:4V中的Volume
类型多:结构化、半结构化和非结构化
来源广:数据来源广泛
及时性:4V中的Velocity
积累久:长期积累与存储
在线性:随时能调用和计算
价值密度低:大量数据中真正有价值的少
最终价值大:最终带来的价值大
马云在一次演讲中说道:“人类正从IT时代走向DT时代”。IT时代是以自我控制、自我管理为主的时代,而DT时代是以服务大众、激发生产力为主的时代。DT的核心,是关于数据驱动的创新,也就是基于海量数据的巨大价值挖掘为核心的创新体系及模式。IT时代以信息流为中心,DT时代以数据流为中心;IT时代以占有、掌握、传输和控制为特点,DT时代则以开放、透明、体验和分享为特征。DT不仅是技术的提升,还是思想观念的提升。
知识就是力量,信息就是能量,数据就是变量。数据的变量体现为“数据×”的乘数效应,乘数改变一切。DT时代的到来,让新的知识和信息作为一种连接的基础设施和资源,被“大数据×”转换为一种无限的数据变量,因此,大数据带来的改变和影响是多维的。以控制为出发点的IT时代正在向以激发生产力为目的的DT时代。这种新的思想,重新定义了由数据驱动的世界观:大数据重新定义世界制造业创新升级路径、大数据重新定义企业的研发创新模式、以及大数据重新定义世界创新公司。
另外,大数据是需要洞见(insight)的。
洞见就是发现数据背后的运行规律,从而让数据产生它应该产生的价值。Nicolas Copernicus提出了“日心说”,用各种各样的逻辑推理认为这就是事实,但是没有大数据支持。一百多年以后,有一位丹麦的天文学家叫Tycho Brahe,辛辛苦苦搜集了二十多年的非常精确的天文学数据(包括各种各样的行星运转数据),但是他对这些没有“洞见”,没能发现这些数据背后的本质规律。然后其助手Johannes Kepler却对这些数据尤其上心,加入了自己的“洞见”,进而最终发现了行星运行规律,让“日心说”被世人认可。
在大数据这件事上,要从问题需求出发,而不是从大数据本身出发。有人会问,有了一些数据,给我讲讲怎么能发挥更大的价值。坦率来说,许多时候不了解业务场景,很难提出建设性的意见的。
因此,在应该关注“大”还是关注“数据”这个问题上,我们可以简单总结一下:
要关注大数据的本质特征
要关注实际的问题需求
要关注大数据的洞见
如果说工业化把人从体力劳动当中解放出来,那么大数据和机器智能则很可能会把人从简单的脑力劳动中解放出来。
本次课最后再来看一下最近几个比较流行的提法:数据科学、数据技术和数据工程。它们之间到底有些什么区别和联系呢?
实际上,科学、技术与工程是现代“科学技术”中的三个不同领域或不同层次。科学是对客观世界本质规律的探索与认识。其发展的主要形态是发现(Discovery),主要手段是研究(Research),其成果主要是学术论文与专著。技术是科学与工程之间的桥梁。其发展的主要形态是发明(Innovation),主要手段是研发(Research & Development),其成果主要是专利,也包括论文和专著。工程则是科学与技术的应用和归宿,是以创新思想(New idea)对现实世界发展的新问题进行求解(Solution)。其主要的发展形态是综合集成(Integration),主要手段是设计(Design)、制造(Manufacture)、应用(Application)与服务(Service),其成果是产品、作品、工程实现与产业。科学家的工作是发现,工程师的工作是创造。
有了这些概念后,回过头再来看看大数据就比较明白了。
数据科学是对大数据世界的本质规律进行探索与认识,是基于计算机科学、统计学、信息系统等学科的理论,甚至发展出新的理论,研究数据从产生与感知到分析与利用整个生命周期的本质规律,是一门新兴的学科。
数据技术是数据科学与数据工程之间的桥梁。包括数据的采集与感知技术、数据的存储技术、数据的计算与分析技术、数据的可视化技术等。
数据工程则是数据科学与数据技术的应用和归宿,是以创新思想对现实世界的数据问题进行求解,是利用工程的观点进行数据管理和分析以及开展系统的研发和应用。包括数据系统的设计、数据的应用、数据的服务等。
大数据不仅仅是信息技术领域的事情,它的典型特点就是与应用密切结合。在当前阶段,大数据概念的提出和被广泛接受才不过几年的时间,属于发展初期。大数据的概念已经被社会各个层面广泛认可,开始从线上走到线下,越来越多的人从企业管理、社会治理、科学研究等领域探讨大数据的应用。这种来源于应用的关于大数据技术的爆发式需求,为一门新型的独立学科的形成和发展带来了挑战和机遇。
在国家大数据人才的需求中,国家既需要优秀的数据科学家,也需要数据工程师这样的工程系型人才,更需要大量高素质的能够创造性解决国民经济与社会发展实际问题的卓越应用型人才。
注:如需该课件,可以在微信公众号中回复“大数据02”进行获取,欢迎订阅本公众号!

- 《大数据原理与实践》第2次公开课:Concept
- 《大数据原理与实践》第2次公开课:Concept
- 《大数据原理与实践》第1次公开课:Overview
- 《大数据原理与实践》第3次公开课:Technology
- 《大数据原理与实践》第4次公开课:Application
- [2017最新]汇总《大数据原理与实践》微信公开课程
- 技术文章 | 《大数据分析原理与实践》
- 《大数据分析原理与实践》——第3章 关联分析模型
- 写在《大数据原理与实践》专栏开始前
- 书籍-Druid实时大数据分析原理与实践
- 《加州理工学院公开课:机器学习与数据挖掘》第2讲学习笔记
- 第14周实践 数据大折腾(2)
- 公开大数据集
- 公开大数据集
- 明德扬FPGA-培训班公开课-第03期-《算法的verilog实现》第2次课
- 信息安全原理与实践(第2版)
- 信息安全原理与实践(第2版)
- IT 治理与数据治理-大华南季度公开课培训成功举行
- IplImage简介
- avro反序列化
- 教育技术(学)研究什么?
- (第八周项目4)字符串加密
- Eclipse 的安装
- 《大数据原理与实践》第2次公开课:Concept
- OpenCV Mat 简介
- SQL SERVER自定义函数
- ajax与HTML
- 属性动画(Property Animation)学习心得
- php两域名实现单点登录
- Visual Studio 各版本下载
- java中float与byte[]互转
- redHat6.4-x86_64下Hadoop 2.7.2 伪分布式安装


