Hadoop2.x 让你真正明白yarn
来源:互联网 发布:mac os x10.7.5升级包 编辑:程序博客网 时间:2024/05/21 09:05
问题导读
1.hadoop1.x中mapreduce框架与yarn有什么共同点?
2.它们有什么不同点?
3.yarn中有哪些改变?
4.yarn中有哪些术语?

原文:Hadoop2.x 让你真正明白yarn
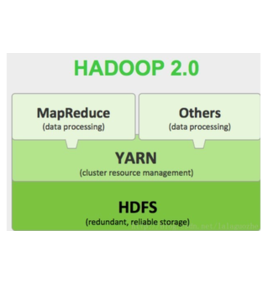
yarn是比较难懂的一个地方,也是很重要的一个组件,不止hadoop使用yarn,spark,storm也可以使用yarn。因此yarn的理解是非常重要的。如果刚开始学习,其实还是挺难懂的。因为很多的概念比较抽象。
如果一时理解不了,也是正常的,这时候就需要我们不断的接触和思考,不断的找资料,强化,通过时间,慢慢就能熟记并且理解。下面是个人总结,希望对大家有所帮助。
相同点
hadoop2.x的发展是由于hadoop1.x的问题造成的。
那么是什么问题造成的。比较流行的说法是jobtracker的问题,比如单点故障,任务过重。我们知道了除了Jobtracker,同时还有一个TaskTracker。我们看下图:

上图中,有一个JobTracker,多个TaskTracker。
Yarn比较
我们在来看yarn
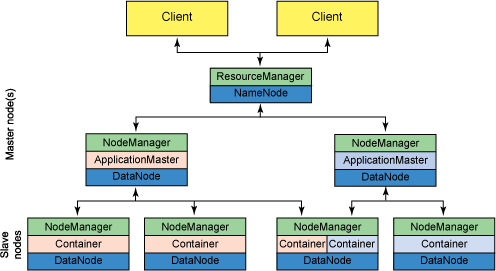
我们看到有一个ResourceManager,多个NodeManager。
也就是说hadoop1.x mapreduce框架与hadoop2.x yarn,他们的框架相同之处,都是分布式的。
再次总结相同处:
JobTracker一个,TaskTracker多个
resourceManager一个,NodeManager多个
不同点
既然他们框架结构是相同的,那么到底是什么原因,淘汰JobTracker机制。
这时候我们就需要看看JobTracker到底干了哪些事情。
再看上图:JobTacker概述
JobTacker其承担的任务有:接受任务、计算资源、分配资源、与DataNode进行交流。
在hadoop中每个应用程序被表示成一个作业,每个作业又被分成多个任务,JobTracker的作业控制模块则负责作业的分解和状态监控。
*最重要的是状态监控:主要包括TaskTracker状态监控、作业状态监控和任务状态监控。主要作用:容错和为任务调度提供决策依据。
TaskTracker概述
TaskTracker是JobTracker和Task之间的桥梁:一方面,从JobTracker接收并执行各种命令:运行任务、提交任务、杀死任务等;另一方面,将本地节点上各个任务的状态通过心跳周期性汇报给JobTracker。TaskTracker与JobTracker和Task之间采用了RPC协议进行通信
TaskTracker的功能:
1.汇报心跳:Tracker周期性将所有节点上各种信息通过心跳机制汇报给JobTracker。这些信息包括两部分:
*机器级别信息:节点健康情况、资源使用情况等。
*任务级别信息:任务执行进度、任务运行状态等。
2.执行命令:JobTracker会给TaskTracker下达各种命令,主要包括:启动任务(LaunchTaskAction)、提交任务(CommitTaskAction)、杀死任务(KillTaskAction)、杀死作业(KillJobAction)和重新初始化(TaskTrackerReinitAction)。
资源slot概述
slot不是CPU的Core,也不是memory chip,它是一个逻辑概念,一个节点的slot的数量用来表示某个节点的资源的容量或者说是能力的大小,因而slot是 Hadoop的资源单位。
hadoop中什么是slots
http://www.aboutyun.com/forum.php?mod=viewthread&tid=7562
yarn详解
Yarn的基本思想是拆分资源管理的功能,作业调度/监控到单独的守护进程
这里面出现了很多名词:
ResourceManager,NodeManager,ApplicationMaster,Container,同样下面亦是yarn结构图。
ResourceManager是全局的,负责对于系统中的所有资源有最高的支配权。
ApplicationMaster 每一个job有一个ApplicationMaster 。
NodeManager,NodeManager是基本的计算框架。
NodeManager 是客户端框架负责 containers, 监控他们的资源使用 (cpu, 内存, 磁盘, 网络) 和上报给 ResourceManager/Scheduler.
ApplicationMaster首先它是一个框架库,它的功能官网说的不够系统,大意,由于NodeManager 执行和监控任务需要资源,所以通过ApplicationMaster与ResourceManager沟通,获取资源。换句话说,ApplicationMaster起着中间人的作用。
转换为更专业的术语:AM负责向ResourceManager索要NodeManager执行任务所需要的资源容器,更具体来讲是ApplicationMaster负责从Scheduler申请资源,以及跟踪这些资源的使用情况以及任务进度的监控。
ResourceManager有两个组件:调度器和应用程序管理器。
调度器(Scheduler)是可插拔的,比如有Fair Scheduler、Capacity Scheduler等,当然调度器也可以自定义。
更多相关内容:
Hadoop YARN配置参数剖析(4)—Fair Scheduler、Capacity Scheduler相关参数
http://www.aboutyun.com/forum.php?mod=viewthread&tid=5864
应用程序管理器
负责接收提交的任务,指定ApplicationMaster申请资源(container) ,协调并提供在ApplicationMaster容器失败时的重启功能。
而下图也是官网提供内容,大家可以参考下。

总结
为了更好的理解,我们就需要跟hadoop1.x比较:
为何要使用yarn。
我们看到JobTracker的功能被分散到各个进程中包括ResourceManager和NodeManager:
比如监控功能,分给了NodeManager,和Application Master。
ResourceManager里面又分为了两个组件:调度器及应用程序管理器。
也就是说Yarn重构后,JobTracker的功能,被分散到了各个进程中。同时由于这些进程可以被单独部署所以这样就大大减轻了单点故障,及压力。
同时我们还看到Yarn使用了Container,而hadoop1.x中使用了slot。slot存在的缺点比如只能map或则reduce用。Container则不存在这个问题。这也是Yarn的进步。
参考资源:
hadoop入门:第六章YARN文档概述
http://www.aboutyun.com/forum.php?mod=viewthread&tid=17338
http://hadoop.apache.org/docs/r2.7.2/hadoop-yarn/hadoop-yarn-site/YARN.html
http://www.2cto.com/kf/201311/260826.html
1.hadoop1.x中mapreduce框架与yarn有什么共同点?
2.它们有什么不同点?
3.yarn中有哪些改变?
4.yarn中有哪些术语?
原文:Hadoop2.x 让你真正明白yarn
yarn是比较难懂的一个地方,也是很重要的一个组件,不止hadoop使用yarn,spark,storm也可以使用yarn。因此yarn的理解是非常重要的。如果刚开始学习,其实还是挺难懂的。因为很多的概念比较抽象。
如果一时理解不了,也是正常的,这时候就需要我们不断的接触和思考,不断的找资料,强化,通过时间,慢慢就能熟记并且理解。下面是个人总结,希望对大家有所帮助。
相同点
hadoop2.x的发展是由于hadoop1.x的问题造成的。
那么是什么问题造成的。比较流行的说法是jobtracker的问题,比如单点故障,任务过重。我们知道了除了Jobtracker,同时还有一个TaskTracker。我们看下图:
上图中,有一个JobTracker,多个TaskTracker。
Yarn比较
我们在来看yarn
我们看到有一个ResourceManager,多个NodeManager。
也就是说hadoop1.x mapreduce框架与hadoop2.x yarn,他们的框架相同之处,都是分布式的。
再次总结相同处:
JobTracker一个,TaskTracker多个
resourceManager一个,NodeManager多个
不同点
既然他们框架结构是相同的,那么到底是什么原因,淘汰JobTracker机制。
这时候我们就需要看看JobTracker到底干了哪些事情。
再看上图:JobTacker概述
JobTacker其承担的任务有:接受任务、计算资源、分配资源、与DataNode进行交流。
在hadoop中每个应用程序被表示成一个作业,每个作业又被分成多个任务,JobTracker的作业控制模块则负责作业的分解和状态监控。
*最重要的是状态监控:主要包括TaskTracker状态监控、作业状态监控和任务状态监控。主要作用:容错和为任务调度提供决策依据。
TaskTracker概述
TaskTracker是JobTracker和Task之间的桥梁:一方面,从JobTracker接收并执行各种命令:运行任务、提交任务、杀死任务等;另一方面,将本地节点上各个任务的状态通过心跳周期性汇报给JobTracker。TaskTracker与JobTracker和Task之间采用了RPC协议进行通信
TaskTracker的功能:
1.汇报心跳:Tracker周期性将所有节点上各种信息通过心跳机制汇报给JobTracker。这些信息包括两部分:
*机器级别信息:节点健康情况、资源使用情况等。
*任务级别信息:任务执行进度、任务运行状态等。
2.执行命令:JobTracker会给TaskTracker下达各种命令,主要包括:启动任务(LaunchTaskAction)、提交任务(CommitTaskAction)、杀死任务(KillTaskAction)、杀死作业(KillJobAction)和重新初始化(TaskTrackerReinitAction)。
资源slot概述
slot不是CPU的Core,也不是memory chip,它是一个逻辑概念,一个节点的slot的数量用来表示某个节点的资源的容量或者说是能力的大小,因而slot是 Hadoop的资源单位。
hadoop中什么是slots
http://www.aboutyun.com/forum.php?mod=viewthread&tid=7562
yarn详解
Yarn的基本思想是拆分资源管理的功能,作业调度/监控到单独的守护进程
这里面出现了很多名词:
ResourceManager,NodeManager,ApplicationMaster,Container,同样下面亦是yarn结构图。
ResourceManager是全局的,负责对于系统中的所有资源有最高的支配权。
ApplicationMaster 每一个job有一个ApplicationMaster 。
NodeManager,NodeManager是基本的计算框架。
NodeManager 是客户端框架负责 containers, 监控他们的资源使用 (cpu, 内存, 磁盘, 网络) 和上报给 ResourceManager/Scheduler.
ApplicationMaster首先它是一个框架库,它的功能官网说的不够系统,大意,由于NodeManager 执行和监控任务需要资源,所以通过ApplicationMaster与ResourceManager沟通,获取资源。换句话说,ApplicationMaster起着中间人的作用。
转换为更专业的术语:AM负责向ResourceManager索要NodeManager执行任务所需要的资源容器,更具体来讲是ApplicationMaster负责从Scheduler申请资源,以及跟踪这些资源的使用情况以及任务进度的监控。
ResourceManager有两个组件:调度器和应用程序管理器。
调度器(Scheduler)是可插拔的,比如有Fair Scheduler、Capacity Scheduler等,当然调度器也可以自定义。
更多相关内容:
Hadoop YARN配置参数剖析(4)—Fair Scheduler、Capacity Scheduler相关参数
http://www.aboutyun.com/forum.php?mod=viewthread&tid=5864
应用程序管理器
负责接收提交的任务,指定ApplicationMaster申请资源(container) ,协调并提供在ApplicationMaster容器失败时的重启功能。
而下图也是官网提供内容,大家可以参考下。
总结
为了更好的理解,我们就需要跟hadoop1.x比较:
为何要使用yarn。
我们看到JobTracker的功能被分散到各个进程中包括ResourceManager和NodeManager:
比如监控功能,分给了NodeManager,和Application Master。
ResourceManager里面又分为了两个组件:调度器及应用程序管理器。
也就是说Yarn重构后,JobTracker的功能,被分散到了各个进程中。同时由于这些进程可以被单独部署所以这样就大大减轻了单点故障,及压力。
同时我们还看到Yarn使用了Container,而hadoop1.x中使用了slot。slot存在的缺点比如只能map或则reduce用。Container则不存在这个问题。这也是Yarn的进步。
参考资源:
hadoop入门:第六章YARN文档概述
http://www.aboutyun.com/forum.php?mod=viewthread&tid=17338
http://hadoop.apache.org/docs/r2.7.2/hadoop-yarn/hadoop-yarn-site/YARN.html
http://www.2cto.com/kf/201311/260826.html
0 0
- Hadoop2.x 让你真正明白yarn
- Hadoop2.x 让你真正明白yarn
- 让你真正明白什么是hive
- 让你真正明白什么是hive
- 让你真正明白什么是hive
- 让你真正明白什么是hive
- Hadoop2.x YARN架构
- Hadoop2.x的yarn
- 一步一图一代码,一定要让你真正彻底明白红黑树
- 一步一图一代码,一定要让你真正彻底明白红黑树
- 一步一图一代码,一定要让你真正彻底明白红黑树
- 一步一图一代码,一定要让你真正彻底明白红黑树
- 让你真正明白什么是MapReduce组合式,迭代式,链式
- 让你真正明白什么是MapReduce组合式,迭代式,链式
- 一步一图一代码,一定要让你真正彻底明白红黑树
- 一步一图一代码,一定要让你真正彻底明白红黑树
- 让你真正明白cinder与swift、glance的区别
- 一步一图一代码,一定要让你真正彻底明白红黑树
- opencv 2D直方图
- ListView+ SQLite实现商品展示
- Android:AS与Unity3D之间打包的各种坑及解决方案
- POJ
- IF脚本实现虚拟机的开启,关闭,重置,快照
- Hadoop2.x 让你真正明白yarn
- Android Arm Inline Hook
- Android出现“Read-only file system”解决办法
- Adaboost原理简析
- mac install kafka
- 数据库基础
- poj 3164 Command Network(有定根的最小树形图)
- 在myeclipse中开发webapp的一般步骤
- ASP.Net学习笔记014--ViewState初探3


