Hash综述
来源:互联网 发布:淘宝商家入口 编辑:程序博客网 时间:2024/06/01 09:28
MinHash算法
Jaccard index是用来计算相似性,也就是距离的一种度量标准。假如有集合A、B,那么,
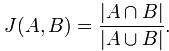
那么对集合A、B,hmin(A) = hmin(B)成立的条件是A ∪ B 中具有最小哈希值的元素也在 ∩ B中。这里
有一个假设,h(x)是一个良好的哈希函数,它具有很好的均匀性,能够把不同元素映射成不同的整数。
所以有,Pr[hmin(A) = hmin(B)] = J(A,B),即集合A和B的相似度为集合A、B经过hash后最小哈希值相
等的概率。

3 基于hash方法的相似计算
基于hash的相似度计算方法,是一种基于概率的高维度数据的维度削减的方法,主要用于大规模数据的压缩与实时或者快速的计算场景下,基于hash方法的相似度计算经常用于高维度大数据量的情况下,将利用原始信息不可存储与计算的问题转化为映射空间的可存储计算问题,在海量文本重复性判断方面,近似文本查询方面有比较多的应用,google的网页去重[1],google news的协同过滤[2,3]等都是采用hash方法进行近似相似度的计算,比较常见的应用场景Near-duplicate detection、Image similarity identification、nearest neighbor search,常用的一些方法包括I-match,Shingling、Locality-Sensitive Hashing族等方法,下面针对几种常见的hash方法进行介绍。
3.1 minhash方法介绍
Minhash方法是Locality-sensitive hashing[4,5]算法族里的一个常用方法,基本的思想是,对于每一个对象的itemlist,将输入的item进行hash,这样相似的item具有很高的相似度被映射到相同的buckets里面,这样尽量保证了hash之后两个对象之间的相似程度和原来是高相似的,而buckets的数量是远远小于输入的item的,因此又达到降低复杂度的目的。
minhash方法用Jaccard进行相似度的计算方法,则对于两个集合和 , 和 的相似性的计算方法为:
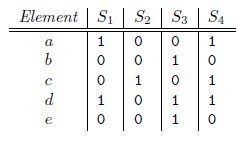
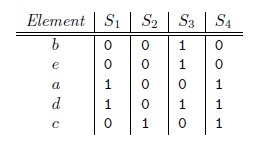
当两个集合越相似,则该值越接近1,否则越接近0。用minhash方法,将一个集合映射到[0-R-1]之间的值,以相同的概率随机的抽取一个[0-R-1[的一个排列,依次排列查找第一次出现1的行。
设随机排列为43201(edcab),对于C1列,第一次出现1的行是R4,所以h(C1) = 3,同理有h(C2)=2, h(C3)=4, h(C4)=3。
通过多次抽取随机排列得到n个minhash函数h1,h2,…,hn,依此对每一列都计算n个minhash值。对于两个集合,看看n个值里面对应相等的比例,即可估计出两集合的Jaccard相似度。可以把每个集合的n个minhash值列为一列,得到一个n行C列的签名矩阵。因为n可远小于R,这样在压缩了数据规模的同时,并且仍能近似计算出相似度。
3.2 simhash方法介绍
simhash方法是在大文本重复识别常用的一个方法,该方法主要是通过将对象的原始特征集合映射为一个固定长度的签名,将对象之间的相似度的度量转化为签名的汉明距离,通过这样的方式,极大限度地进行了降低了计算和存储的消耗。
3.2.1 签名计算过程
该方法通过对输入特征集合的计算步骤可以描述如下:
- 将一个f维的向量V初始化为0;f位的二进制数S初始化为0;
- 对每一个特征:用传统的hash算法对该特征产生一个f位的签名b。对i=1到f:
如果b的第i位为1,则V的第i个元素加上该特征的权重;
否则,V的第i个元素减去该特征的权重。
- 如果V的第i个元素大于0,则S的第i位为1,否则为0;
- 输出S作为签名。
通过上述步骤将输入的表示对象的特征集合转化为该对象的一个签名,在完成签名之后,度量两个对象的相似度的差异即变成了对量二者的指纹的K位的差异情况。
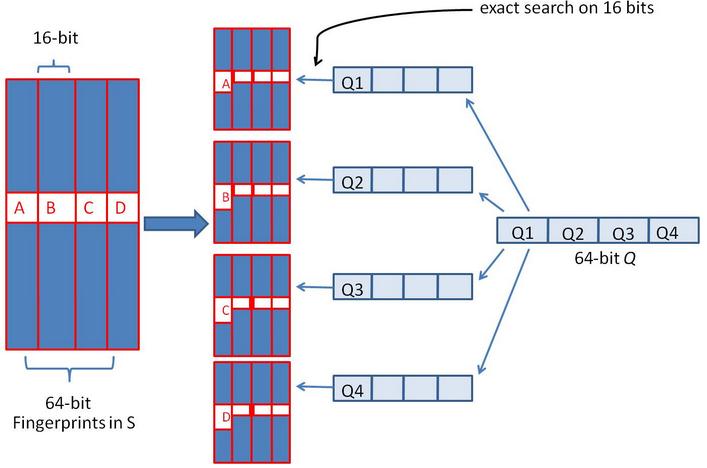
3.2.2 汉明距离查找优化
对于如何快速查找出某一个签名是否与其存在最大差异不超过K个bit的指纹,Detecting Near-Duplicates for Web Crawling这篇论文中进行了介绍。该查找方法的基本思想是利用空间换时间的方法,该方法的依据是需要查找的两个指纹的差异很小,这样可以通过将原始指纹进行分块索引,如果两个指纹的差异很小,则合理的分块后,根据鸽笼原理,其中存在一定数量的块是一致的,通过利用相同的块进行相似的指纹的召回,只需要比对召回的块中有差异的块的bit差异,这样减少了需要比对的数量,节省了比对的时间开销。
3.3 小结
hash方法的相似度计算的主要应用场景,一般是针对大规模数据进行压缩,在保证效果损失可接受的情况下,节省存储空间,加快运算速度,针对该方法的应用,在目前的大规模的互联网处理中,很多相似度的计算都是基于这种近似性的计算,并取得了比较好的效果。
设随机排列为43201(edcab),对于C1列,第一次出现1的行是R4,所以h(C1) = 3,同理有h(C2)=2, h(C3)=4, h(C4)=3。
通过多次抽取随机排列得到n个minhash函数h1,h2,…,hn,依此对每一列都计算n个minhash值。对于两个集合,看看n个值里面对应相等的比例,即可估计出两集合的Jaccard相似度。可以把每个集合的n个minhash值列为一列,得到一个n行C列的签名矩阵。因为n可远小于R,这样在压缩了数据规模的同时,并且仍能近似计算出相似度。
转自:http://huangbo929.blog.edu.cn/2012/758781.html
- Hash综述
- 综述
- hash
- Hash
- hash
- hash
- Hash
- hash
- Hash
- HASH
- hash
- hash
- HASH
- hash
- hash
- Hash
- hash
- hash
- 【适配整理】Android 7.0 调取系统相机崩溃解决android.os.FileUriExposedException
- 第24节:关于继承和trait进阶
- 【死磕Java并发】-----J.U.C之并发工具类:CountDownLatch
- 《C语言程序设计》读书笔记(四)——函数与程序结构
- 在SQL Server中 新建登录用户 并指定该用户登录的数据库及权限
- Hash综述
- 455. Assign Cookies
- 【转】使用缓存的9大误区
- String内存申请图解
- ffmpeg源码简析(八)解码 av_read_frame(),avcodec_decode_video2(),avformat_close_input()
- 《剑指offer》004-替换空格(java实现)
- Ensure that you have installed a JDK (not just a JRE) and configured your JAVA_HOME system variable
- Android 广播大全 Intent Action 事件
- bzoj1088 枚举ss


