【算法-排序】杂记
来源:互联网 发布:游戏优化差是什么意思 编辑:程序博客网 时间:2024/05/23 14:01
1.快速排序最坏情况就是每次选的基准数都和其他数做过比较,共需比较( n -1) + ( n -2) + … + 1 = n( n -1) /2
2.
时间/空间复杂度 
冒泡排序,简单选择排序,堆排序,直接插入排序,希尔排序的空间复杂度为O(1),因为需要一个临时变量来交换元素位置,(另外遍历序列时自然少不了用一个变量来做索引)
快速排序空间复杂度为logn(因为递归调用了) ,
归并排序空间复杂是O(n),需要一个大小为n的临时数组.
基数排序的空间复杂是O(n),桶排序的空间复杂度不确定
3.任何一个基于”比较”的内部排序的算法,若对6个元素进行排序,则在最坏情况下所需的比较次数至少为?
因为6个数字的排列组合是6!,
按照决策树每次可以判断一半的情况,2^k
要求2^k > 6!
取log后得到 k > log(6!) = log(720)
log(2^9) = log(512) = 9 < log(720) < log(2^10) = log(1024) = 10,
所以应该至少选10次。
4.希尔排序_2
实质就是分组插入排序,该方法又称缩小增量排序,因DL.Shell于1959年提出而得名。
该方法的基本思想是:先将整个待排元素序列分割成若干个子序列(由相隔某个“增量”的元素组成的)分别进行直接插入排序,然后依次缩减增量再进行排序,待整个序列中的元素基本有序(增量足够小)时,再对全体元素进行一次直接插入排序。因为直接插入排序在元素基本有序的情况下(接近最好情况),效率是很高的,因此希尔排序在时间效率上比前两种方法有较大提高。
5.假设你只有100Mb的内存,需要对1Gb的数据进行排序,最合适的算法是?
首先肯定不能使用内存排序算法,内存根本装不下,所以需要使用外存来排序。这时候使用多路归并排序,把数据分为n段,每段小于100Mb,再使用用内存来排序,将排序结果用外存记录,然后每次从外存中来取记录,在内存中进行比较,从而获取最后的排序结果。
6.直接插入排序
基本思想
当插入第i(i≥1)个对象时,前面的V[0],V[1],…,V[i−1]已经排好序。这时,用V[i]的排序码与V[i−1],V[i−2],…,V[0]的排序码顺序进行比较,找到插入位置即将V[i]插入,原来位置上的对象向后顺移。
7.设数组中初始状态是递增的,分别用堆排序,快速排序,冒泡排序和归并排序方法对其进行排序(按递增顺序), 那个 最省时间, 那个 最费时间。
这道题更为严谨应该是改良后冒泡排序最省时间(有标志位f,遍历一趟,没有改变则跳出循环)O(n),而快排在数列基本有序的情况下时间复杂度最差为O(n2 );
8.线性排序算法
计数排序
假设:有n个数的集合,而且n个数的范围都在0~k(k = O(n))之间。
运行时间:Θ(n+k) 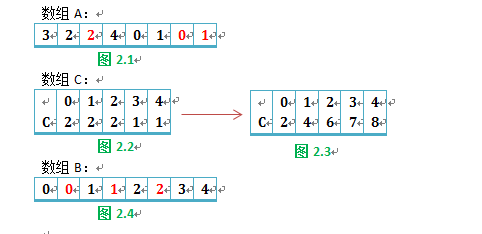
桶排序
桶排序:将数组分到有限个桶子内,然后再对桶子里面的序列进行排序,运行时间Θ(n)。桶排序基于一个假设:输入的数据由随机过程构成,否则在最坏情况下都分配到一个桶子里面,如果又不满足计数排序的假设要求,那么只能使用基于比较的排序算法进行排序,运行时间就退化到Ω(nlogn)。
基数排序
基数排序:将所有待比较数值(正整数)统一为同样的数位长度,数位较短的数前面补零。然后,从最低位开始,依次进行一次排序。这样从最低位排序一直到最高位排序完成以后, 数列就变成一个有序序列。
基数排序分为两种LSD和MSD。
LSD(Least significant digital):最低有效位优先,即从右向左开始排序。
MSD(Most significant digital):最高有效位优先,即从左往右开始排序。
9.分配排序(又叫基数排序)
一. 算法描述
基数排序(以整形为例),将整形10进制按每位拆分,然后从低位到高位依次比较各个位。主要分为两个过程:
(1)分配,先从个位开始,根据位值(0-9)分别放到0~9号桶中(比如53,个位为3,则放入3号桶中)
(2)收集,再将放置在0~9号桶中的数据按顺序放到数组中
重复(1)(2)过程,从个位到最高位(比如32位无符号整形最大数4294967296,最高位10位)
以【521 310 72 373 15 546 385 856 187 147】序列为例,具体细节如下图所示: 


二. 算法分析
平均时间复杂度:O(dn)(d即表示整形的最高位数)
空间复杂度:O(10n) (10表示0~9,用于存储临时的序列)
稳定性:稳定
10.排序时,若不采用计数排序等科技换时间的方法,合并m个长度为n的已排序数组的时间复杂度最优为()
O(nm)是这个算法的下限了,不用空间换时间做不到。可以用败者树来解,复杂度为O(nmlogm)
合并m个长度为n的已排序数组的时间复杂度为O(nmlogm)。思路是:首先将m个已排序数组的第一个数,建立大小为m的小根堆,时间复杂度O(m)。然后每次输出堆顶的数,再将其所属已排序数组的后一个数放入堆顶,调节小根堆。因为我们有m*n个数,小根堆调整时间为O(logm),所以时间复杂度O(nmlogm)。
11.
选择树:能够记载上一次比较所获得的知识的数据结构。完全二叉树,分为胜者树和败者树两种。
胜者树:每个父结点表示它的两个子女中比赛胜利的结点,胜利的结点继续向上比赛。根结点记录了最后的胜者。
重构:从缓冲区中再取出一个结点,将其与自己的兄弟结点比较,如果胜,则继续向上比较,否则,其兄弟代替它继续向上比较。败者树:每个父结点表示它的两个子女中比赛失败的结点,胜利的结点继续向上比赛。根结点记录的是与最后的胜者比较后失败者,所以需要添加 一个结点来表示最后的胜者。
重构:从缓冲区中再取出一个结点,将其与自己的父亲结点进行比较,如果胜,则继续向上比较,否则,其父亲代替它继续向上比较。 注:叶子结点记录的是真实的值,而非叶结点记录了相应的结点标号,不是实际的数据胜者树和败者树的复杂度相同,只是败者树的重构过程比较简单
外部排序——归并
有一个很大的记录,将其平均分为几小部分,假设分为了A、B、C、D、E、F、G七个文件,每个文件有足够的内存可以容纳
将这七个文件分别放入内存,进行内排序,形成七个归并段
假设采用三路归并:将3个归并段归并为一个,通过反复输出关键字最小的记录完成
每次归并的时候,不需要将所有的记录都放入内存,只要取每个文件的第一个记录即可。
完成第一次归并后,七个归并段将减少为三个归并段
进行第二次归并,三个归并段就可以归并为一个归并段,完成排序
在此期间,文件可用于作为缓冲区
败者树与归并
假设有m个初始归并段,进行k路归并排序,则磁盘读写的次数为|logkm|(k是log的底数)
(这个过程与二叉树的高度是相同的,总共有m个元素,每次k个不断归为1,到顶时m个归为1)
可见,当k越大的时候,读写的次数越小。
一次归并的算法复杂度:O((n-1)log2k)(n表示参与一次归并时的所有归并段中的元素个数)
12.外部排序与归并
一、定义问题
外部排序指的是大文件的排序,即待排序的记录存储在外存储器上,待排序的文件无法一次装入内存,需要在内存和外部存储器之间进行多次数据交换,以达到排序整个文件的目的。外部排序最常用的算法是多路归并排序,即将原文件分解成多个能够一次性装入内存的部分,分别把每一部分调入内存完成排序。然后,对已经排序的子文件进行多路归并排序。二、处理过程
(1)按可用内存的大小,把外存上含有n个记录的文件分成若干个长度为L的子文件,把这些子文件依次读入内存,并利用有效的内部排序方法对它们进行排序,再将排序后得到的有序子文件重新写入外存;
(2)对这些有序子文件逐趟归并,使其逐渐由小到大,直至得到整个有序文件为止。
先从一个例子来看外排序中的归并是如何进行的?
假设有一个含10000 个记录的文件,首先通过10 次内部排序得到10 个初始归并段R1~R10 ,其中每一段都含1000 个记录。然后对它们作如图10.11 所示的两两归并,直至得到一个有序文件为止 如下图

13.
拓扑排序 :
由AOV网构造拓扑序列的拓扑排序算法主要是循环执行以下两步,直到不存在入度为0的顶点为止。
(1) 选择一个入度为0的顶点并输出之;
(2) 从网中删除此顶点及所有出边。
循环结束后,若输出的顶点数小于网中的顶点数,则输出“有回路”信息,否则输出的顶点序列就是一种拓扑序列。
典型实现算法:
Kahn算法:
不难看出该算法的实现十分直观,关键在于需要维护一个入度为0的顶点的集合:
每次从该集合中取出(没有特殊的取出规则,随机取出也行,使用队列/栈也行,下同)一个顶点,将该顶点放入保存结果的List中。
紧接着循环遍历由该顶点引出的所有边,从图中移除这条边,同时获取该边的另外一个顶点,如果该顶点的入度在减去本条边之后为0,那么也将这个顶点放到入度为0的集合中。然后继续从集合中取出一个顶点…………
当集合为空之后,检查图中是否还存在任何边,如果存在的话,说明图中至少存在一条环路。不存在的话则返回结果List,此List中的顺序就是对图进行拓扑排序的结果。
基于DFS的拓扑排序:
除了使用上面直观的Kahn算法之外,还能够借助深度优先遍历来实现拓扑排序。这个时候需要使用到栈结构来记录拓扑排序的结果。
14.
在数据元素的序列中,对于某个元素,如果其后存在一个元素小于它,则称之为存在一个逆序。冒泡排序只交换相邻元素,但不是每次移动都产生新的逆序。简单插入排序每一次比较后最多移掉一个逆序。快速排序每一次交换移动都会产生新的逆序,因为当不会有新的逆序产生时,本轮比较结束。简单选择排序的基本思想是先从所有 n 个待排序的数据元素中选择最小的元素,将该元素与第一个元素交换,再从剩下的 n-1 个元素中选出最小的元素与第 2 个元素交换,这样做不会产生逆序。故本题答案为 A 选项。
15.计数排序
以往的排序算法中,各个元素的位置基于元素直接的比较,这类排序称为比较排序。任意一个比较排序算法在最坏情况下,都需要做Ω(nlgn)次的比较。
而计数排序是基于非排序的思想的,计数排序假设n个输入元素中的每一个都是介于0到k之间的整数。
计数排序的思想是对每一个输入元素x,确定出小于x的元素个数,有了这一信息,就可以把x直接放在它在最终输出数组的位置上,例如,如果有17个元素小于x,则x就是属于第18个输出位置。当几个元素相同是,方案要略作修改。
计数排序是稳定的。
时间复杂度O(n+k),空间复杂度O(k)
16.
一趟快速排序意思是:寻找一个支点,将该序列位置整个调整一边,可以看到M是支撑点,左边都是比M小的,右边都是比M大的,
注意:支点不一定是左边第一个数,可以任意选的。
17.外部排序过程中,为了减少外存读写次数需要减小归并趟数(外部排序的过程中用到归并),归并趟数为:logk n(其中k为归并路数,n为归并段的个数)。增加k和减小n都可以达到减小归并趟数的目的。置换-选择排序就是一种减小n的、在外部排序中创建初始归并段时用到的算法。它可以让初始归并段的长度增减,从而减小初始归并段的段数(因为总的记录数是一定的)
- 排序算法杂记
- 【算法-排序】杂记
- 算法杂记
- 算法杂记
- 杂记之算法分析
- 算法导论杂记
- 【算法-查找】杂记
- 算法与数据结构杂记
- 数据结构-杂记--选择排序
- spark:学习杂记+快速排序--26
- 杂记
- 杂记
- 杂记
- 杂记
- 杂记
- 杂记
- 杂记
- 杂记
- part-18 压摆率SR
- 利用栈实现软中断
- 如何分析java进程中哪个线程最耗资源
- 【滤波】卡尔曼matlab仿真代码
- js面向对象编程指南学习笔记--闭包封装HTTP请求
- 【算法-排序】杂记
- java开发遇到的问题小计
- 解决Vuser停在Gradual Exiting状态不动的问题
- 商品展示案例(ListView的用法)
- 新增投资人数
- linux上JDK的安装和环境变量的配置
- 打印数字
- NYOJ-迷宫寻宝(一)【搜索|广搜】
- python scatter


