Mooc爬虫05-scrapy框架
来源:互联网 发布:再生人的骗局知乎 编辑:程序博客网 时间:2024/06/03 18:13
安装
pip install scrapy查看是否安装完成
scrapy ‐h scrapy框架是实现爬虫功能的一个软件结构和功能组件集合
scrapy爬虫框架的结构
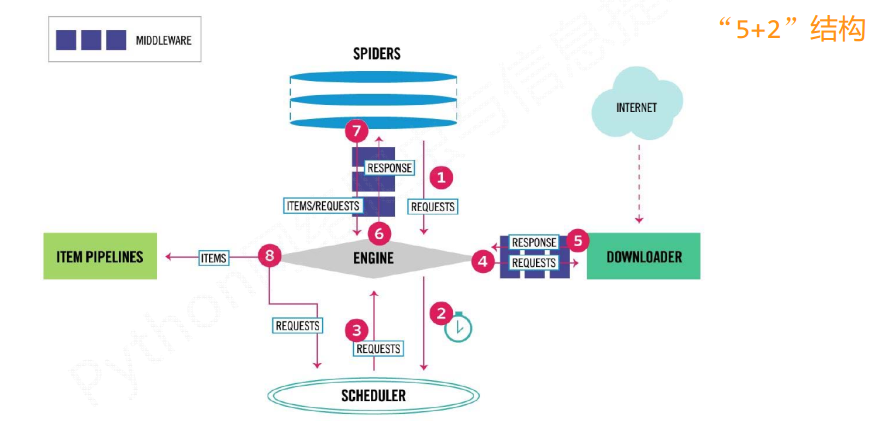
这5+2的结构, 就是scrapy框架
主要有三条主要的数据流路径
第一条路径
1) Engine通过中间件获得了Spiders发送的请求, 这个请求叫做requests, 相当于是一个url
2) Engine再转发给scheduler, scheduler主要负责对爬取请求进行调度
第二条路径
3) 从Scheduler获得下一个需要爬取的请求, 这是一个真实的请求
4) Engine获得这个请求之后, 通过中间件, 将请求给 Downloader模块
5) Downloader爬取请求中相关的网页, 并将爬取的内容封装成一个对象, 这个对象叫response(响应)
6) Engine再通过中间件将response返回给Spiders
第三条路径
7) Spiders处理从Downloader获得的响应, 处理之后会产生两个数据类型, 一个是items(爬取项), 另一个是新的requests
8) Engine接受到这两数据之后, 将items发送给Item Pipelines, 将requests发送给Scheduler进行调度
整个框架的入口是Spiders, 出口是Item Pipelines
其中Engine, Scheduler, 和Downloader是已经写好的, 不需要实现
Spiders和Item Pipelines是需要编写的, 但是里面有既定的代码框架, 所以情况是要对某东西进行修改, 这种情况一般叫配置
2 框架解析
Engine
是整个框架的核心
不需要修改
控制所有模块之间的数据流
根据条件触发事件
Downloader
根据请求下载网页
不需要修改
Scheduler
对所有请求进行调度管理
Downloader Middleware
在Engine和Downloader之间的中间件
实现用户可配置的控制, 一般是对requests或者responses进行处理和修改的时候使用
实现 修改, 丢弃, 新增请求或相应
用户可以编写配置代码
Spiders
解析Downloader返回的相应
产生爬取项
产生额外的爬取请求
需要用户编写, 是用户最主要编写的部分
Item Pipelines
是以流水线的形式进行处理生成的爬起项
由一组操作顺序组成, 类似流水线, 每个操作是一个Item Pipelines
可能包含的操作有: 清理, 检验, 和查重爬取项中的HTML数据, 将数据存储到数据库中
完全由用户编写
Spider Middleware
在Spiders和Engine之间的中间件
对象求和爬取项的再处理
修改, 丢弃, 新增请求或者爬取项
中间件主要是对中间的数据流进行一些操作
3 scrapy和requests的区别
相同点:
都可以进行页面的爬取
可用性都比较好
两者都没有处理js, 提交表单, 应对验证码的功能(但是可以扩展)
不同点
scrapy是网站级别的爬虫, 是一个框架, 并发性好, 性能较高, 重点在于爬虫结构
requests是页面级别的爬虫, 是一个库, 并发性不足, 性能不好, 重点在于页面下载, 定制灵活
4 常用命令
命令格式
scrapy 命令 命令项 命令参数startproject 创建一个新工程
genspider 创建一个爬虫
settings 获取爬虫配置信息
crawl 运行一个爬虫
list 列出工程中所有爬虫
shell 启动URL调试命令行
scrapy主要是一个后台的爬虫框架
之所以提供命令行的方式是因为 命令行的方式更加荣益自动化, 适合脚本控制
本质上, scrapy是给程序员使用的, 使用命令行的方式更加合适
5 简单实例
- Mooc爬虫05-scrapy框架
- scrapy爬虫框架
- Scrapy爬虫框架入门
- Python 爬虫框架 scrapy
- 网络爬虫框架-Scrapy
- Scrapy爬虫框架笔记
- Scrapy - 爬虫框架
- 爬虫框架Scrapy
- 关于scrapy爬虫框架
- scrapy爬虫框架
- scrapy 爬虫框架
- Scrapy爬虫框架
- 爬虫框架scrapy安装
- Scrapy爬虫框架
- Python爬虫框架--Scrapy
- Python Scrapy爬虫框架
- Scrapy爬虫框架介绍
- python爬虫 -- scrapy框架
- Mooc爬虫02-Robots协议
- Mooc爬虫03-BeautifulSoup
- Day25-匿名函数和内置函数
- Mooc爬虫04-正则表达式
- Day26-递归和对面对象编程初步
- Mooc爬虫05-scrapy框架
- 使用new和delete创建二维数组
- 第八章-错误调试
- 001-将Python源码转换为不需要环境的可执行文件
- rxJava学习笔记
- 第九章-IO编程
- Day27~30-类
- Day31-面向对象高级(上)
- 第十章-进程和线程


