矩阵论基础知识1(LU分解 条件数 最小二乘问题)
来源:互联网 发布:散热仿真软件 编辑:程序博客网 时间:2024/06/06 00:24
1. LU Decomposition
假设现在要解一个线性系统:
Ax = b,
其中 A 是 n×n 非奇异方阵,对于任意的向量 b 来说,都存在一个唯一的解。
回顾我们手工求解这个线性方程组的做法,首先将矩阵 A 行之间进行加减,将 A 矩阵转化为一个上三角矩阵,然后从下往上将未知数一个一个求解出来, 这就是高斯消元法。
实际上,矩阵等价于左乘一个单位矩阵,(因为行变换操作可以直接体现在左乘的单位矩阵上),我们将左乘的单位矩阵最终等价变换后得到的矩阵命名为 M ,显然, M 是一个下三角矩阵,U是一个上三角矩阵。
MA = U.
A = LU. 其中 M, L 互为逆矩阵
图片表示如下:

由于要确保 A 转化后的第一行的第一项不为 0, 第二行的第二项不为 0, 第三行…… 因此, A 前面应该再加上一个行与行之间进行交换的矩阵 P。因此,LU 分解的公式又可以写成:
PA = LU
P 是 permutation matrix, L 是 lower triangular matrix, U 是 upper triangular matrix. 有些书将置换矩阵 P 放置在等号右边。比如这个矩阵在线计算器默认的就是将 P 放置在矩阵 L 的前面。不妨利用这个工具测试一下 LU 分解的正确性。
如果 A 是对称正定矩阵,L 和 U 正好是互为转置,差别在于对应的行存在倍数关系,这种那个倍数关系可以用对角线矩阵来实现,所以, LU 分解就可以写成:
将对角线矩阵均摊到两边,公式可以转化为:
其中,矩阵 U 是上三角矩阵,这个就是 Cholesky decomposition,这个分解方法有点像求实数的平方根。同时,该分解方法的计算量只有 LU 分解的一半。
2. 条件数
条件数是线性方程组Ax=b的解对b中的误差或不确定度的敏感性的度量。数学定义为矩阵A的条件数等于A的范数与A的逆的范数的乘积,即cond(A)=‖A‖·‖A-1‖,对应矩阵的3种范数,相应地可以定义3种条件数。
matlab 里面运算函数:cond(A,2)或cond(A):2范数
一个极端的例子,当A奇异时,条件数为无穷,这时即使不改变b,x也可以改变。奇异的本质原因在于矩阵有0特征值,x在对应特征向量的方向上运动不改变Ax的值。如果一个特征值比其它特征值在数量级上小很多,x在对应特征向量方向上很大的移动(条件数很大)才能产生b微小的变化,这就解释了为什么这个矩阵为什么会有大的条件数,事实上,正规阵在二范数下的条件数就可以表示成 abs(最大特征值/最小特征值)。
在计算机编程环境中,数据都是有浮点类型表示,精度有限,存在干扰,因此在解线性方程的时候都会存在误差。
3. 最小二乘的问题
在机器学习里面,使用线性分类器或者线性回归方法时经常会遇到最小二乘的问题(分类也可以看做一种特殊的回归,目标值是 1 和 -1 或者 0 和 1)。现有下面这个问题,左边是样本点的两个属性,右边是回归值,如何确定 e 和 k?

这个线性系统可以表示为:
Ax = b
其中,A 的行数大于列数,这种情况又叫做 overdetermined(超定)。假设 A 矩阵是 3×2 的矩阵,令 A = (a1, a2),Ax 表示这两个基向量的所有线性组合(span),在几何上是三维空间里的一个平面。而 b 向量则是三维空间里面的一个点,这个点如果不在 span{a1, a2} 构成的平面上,则该方程不存在正确的解。现在我们的任务是令残差向量 r = b - Ax 最小:

LMS 算法中利用梯度下降法可以达到目标函数的最优值,但是这个目标函数的真正意义是什么?
几何上的直观感受就是,如果残差向量正好垂直于 a1, a2 组成的平面,此时达到最优(此时b-Ax为b点到平面的距离,显然残差r垂直于平面,取得最小值):

残差向量 r = b - Ax 与 a1, a2 组成的平面垂直,则与向量 a1, a2 也是相互垂直的:

将r=Ax-b代入上式,并展开写成如下公式:

如果 A 矩阵的列向量是线性无关的,那么上式有唯一的解:

用这个方法解决 least squares problems 存在两个缺陷:
- A^T A 会导致信息的丢失。假设 A 中某一项是一个计算机刚好能表示的浮点数,A 乘以 A 的转置后浮点数的平方可能超出精度而被丢失,从而导致 A^T A 是奇异矩阵无法求解,应对的方法是后面要学的奇异值分解(者从数学计算方面说明了SVD分解的强大,在另一篇专门写SVD的博文中也有提到)。
- A^T A 的条件数是 A 的平方。系统不稳定性变大了。应对的方法是对数据进行中心化预处理,这样做的目的是要增加基向量的正交性。
4. 投影矩阵
先说说投影吧,这个想必大家都知道,高中的知识了。一个向量(b)在另一个向量(a)上的投影:
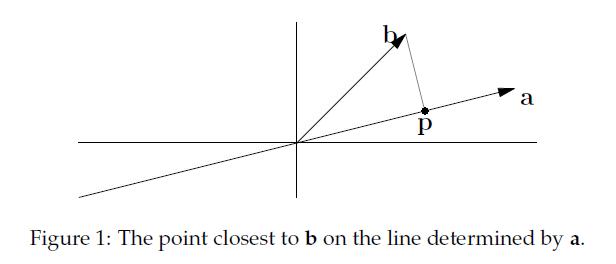
实际上就是寻找在a上离b最近的点。如果我们把p看作是a的估计值,那么我们定义e = b - p,称e为误差(error)。
现在,我们的任务是找到这样的p,我们可以规定p = xa(x是某个数),那么e = b - xa,因为e与p也就是a垂直,所以有aT(b - xa) = 0,展开化简得到:
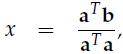
将x代入到p中,得到:

我们发现,如果改变b,那么p相对应改变,然而改变a,p无变化。
有了上面的背景知识,我们可以正式进入主题了,投影矩阵(projection matrix):
p = Pb,P便是投影矩阵了
显然这里有:
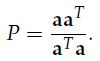
这里我们最需要关注的是投影矩阵的两个性质:
1)P' = P;
2)P ^ 2 = P;
对于第一个,很容易理解,因为P本身就是个对称阵。第二个,直观的理解就是投影到a上后再投影一次,显然投影并没有改变,也就是二次投影还是其本身。
这个投影到底有什么用呢,从线性代数的角度来说,Ax = b并不一定总有解,这在实际情况中会经常遇到(超定即行数大于列数)。所以我们就把b投影到向量p上,求解Ax = p。
接下来,我们可以考虑更高维度的投影,三维空间的投影是怎么样的呢,我们可以想象一个三维空间内的向量在该空间内的一个平面上的投影:
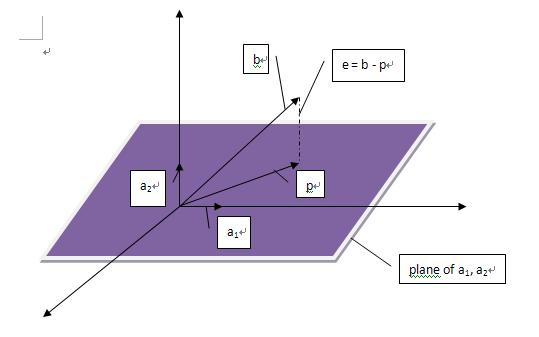
我们假设这个平面的基(basis)是a1, a2.那么矩阵A = [a1 a2]的列空间就是该平面。假设一个不在该平面上的向量b在该平面上的投影是p,那么我们就有下面这个表达式 p = x1a1 + x2a2 = Ax, 我们的任务就是找到这样的x。这里有一个关键的地方:e = b - Ax与该平面垂直,所以a1'(b - Ax) = 0且a2' (b- Ax) = 0.用矩阵的形式表达就是:
A'(b - Ax) = 0.
从上面这个式子我们可以得到e(e = b - Ax)等于N(A')。回忆之前的四个空间的关系:假设矩阵(m * n)的秩为r,行空间(维度r)与零空间(维度n - r)互相垂直,列空间(维度r)与左零空间(维度为m - r)互相垂直。所以,我们可以得到e垂直于C(A)。
我们把上边式子展开,得到A'Ax = A'b => x = (A'A)-1A'b, p = Ax = A(A'A)-1A'。类似在二维情况下,在三维情况下我们依然有:
1)p' = p;
2)p ^ 2 = p。
好了,在此我们先暂别“投影”。下面,开始说一下最小二乘的故事吧:
在实际应用中,线性回归是经常用到的,我们可以在一张散列点图中作一条直线(暂时用直线)来近似表述这些散列点的关系。比如:
给定二维平面的三个点:(1, 1), (2, 2), (3, 2)。我们想寻求一条直线(y = C + Dt)来逼近这些点。假设这些点都在该直线上,我们有:
C + D = 1
C + 2D = 2
C + 3D = 2.写成矩阵的形式如下:

实际上,这条直线是不存在的。从线性代数的角度来看,就是A的列向量的线性组合无法充满整个列空间,而b恰恰就是一个例外。所以,我们就借助了投影矩阵,我们这么干 :
:
A'Ax = A'b。
- 矩阵论基础知识1(LU分解 条件数 最小二乘问题)
- 矩阵论基础知识1(LU分解 条件数 最小二乘问题)
- 基于最小二乘的矩阵分解问题
- 矩阵分解(1) LU分解
- 矩阵求导解最小二乘问题
- 矩阵求导解最小二乘问题
- SVD(奇异值分解)及求解最小二乘问题
- SVD(奇异值分解)及求解最小二乘问题
- 奇异值分解与最小二乘问题
- 矩阵论基础知识5(病态矩阵与条件数 )
- 矩阵的LU分解(Matlab程序)
- 矩阵之LU分解
- 矩阵LU的分解
- 矩阵最小二乘求导
- 最小二乘问题
- 算法学习之一(二):矩阵计算——LU分解
- 投影矩阵与最小二乘(二)
- 投影矩阵与最小二乘(二)
- python项目练习八:使用XML-RPC进行远程文件共享
- 浅谈SVM(六)
- FastReport.net 系列-----FastReport基本操作介绍(数据绑定,页面布局)
- Leetcode 16. 3Sum Closest
- [Leetcode] 129. Sum Root to Leaf Numbers 解题报告
- 矩阵论基础知识1(LU分解 条件数 最小二乘问题)
- Android开发中Handler的经典总结
- Android页面切换动画(包括不同任务栈之间页面切换动画)通过Theme去设置
- 未登录词处理优秀论文——Pointing the Unknown Words
- could not find or load the Qt platform plugin windows的解决方法
- 查找进程并杀死进程
- JavaWeb前端开发知识总结(jQuery)
- virtualbox 最小化安装centos7 配置双网卡(nat和桥接)记录----已经过期
- poj 1651 DP 从一个序列中任意选一个数,进行某种计算,然后移除这个数,直到最后


