ConcurrentHashMap
来源:互联网 发布:淘宝怎么搜潮流的衣服 编辑:程序博客网 时间:2024/06/05 22:21
ConcurrentHashMap
ConcurrentHashMap是线程安全且高效的HashMap。
为什么要使用ConcurrentHashMap
因为在并发编程中使用HashMap可能导致程序死循环,而使用线程安全的HashTable效率又低,所以我们就要使用CurrentHashMap。
线程不安全的HashMap。
在多线程的环境下使用HashMap进行put操作会引起死循环,导致CPU利用率非常的底下,所以在并发操作情况下不能使用HashMap。 HashMap在并发执行put操作时会引起死循环是因为多线程会导致HashMap的Entry链表形成环形数据结构,一旦形成环形数据结构,Entry的next节点永远不为空,就会产生死循环获取Entry。
效率低下的HashTable
HashTable容器使用synchronized来保证线程安全,但是在线程竞争激烈的情况下,HashTable的效率非常的底下,因为当一个线程访问HashTable的同步方法,其他线程也访问HashTable的同步方法时,会进入阻塞或者轮询状态。假如线程1使用put方法进行元素的添加,线程2不但不能进行put的添加还不能进行get的获取,所以导致竞争越激烈,效率越底下。
ConcurrentHashMap的锁分段技术可以有效的提升访问率
ConcurrentHashMap所使用的锁分段技术,首先将数据分成一段一段的进行存储,然后给每一段数据陪一把锁,当一个线程占用锁访问其中某一段数据时其他段的数据也能被其他线程访问。这样就达到了线程安全和效率的双重保证。
ConcurrentHashMap的结构
ConcurrentHashMap的类图如下: 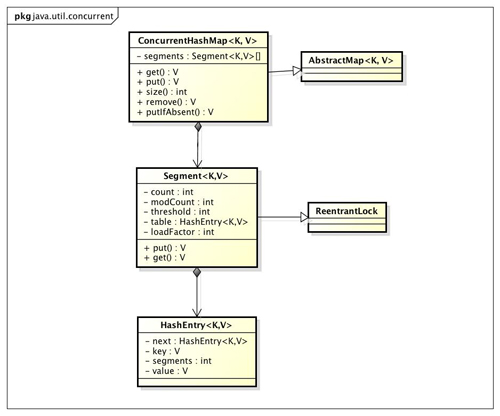
由上图可知ConcurrentHashMap是由Segment数据结构和HashEntry数组结构组成。
- Segment是一种可重入锁,在ConcurrentHashMap中扮演锁的角色,
- HashEntry则用于存储键值对数据。
一个ConcurrentHashMap里包含一个segment数组,Segment的结构和HsahMap类似,是一种数组和链表结构。Segment里包含一个HashEntry数组,每一个HashEntry是一个链表结构的元素。每个Segment守护着一个HashEntry数组里的元素,当HashEntry数组的数据进行修改时,必须首先获得与它对应的Segment锁。
ConcurrentHashMap的结构图如下: 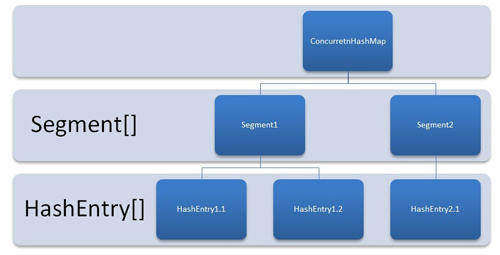
ConcurrentHashMap的初始化
ConcurrentHashMap初始化方法是通过initialCapacity、loadFactor和concurrencyLevel等几个参数来初始化Segment数组、段偏移量segmentShift、段掩码segmentMask和每一个Segment的的HashEntry数组来实现的。
初始化Segments数组
segments数组的长度ssize是通过concurrencyLevel计算出来的。为了能通过按位与的散列算法来定位segments数组的索引,必须保证segments数组的长度是2的N次方。所以必须计算出一个大于或等于concurrencyLevel的最小的2的N次方来作为segments数组的长度。concurrencyLevel的最大值是65535,也就是说segments数组的长度最大为65536对应的是二进制是16位。
初始化segmentShift和segmentMask
这两个变量需要在定位segment时散列算法里使用,
- segmentShiftsshift:等于ssize从1向左移的次数,在默认情况下concurrencyLevel等于16,1需要向左移4次,所以sshift等于4。段偏移量segmentShift用于定位参与散列运算的位数,segmentShift的等于32减去sshift,所以段偏移量segmentShift等于38,之所以使用32是因为ConcurrentHashMap里额hash()方法输出的最大数是32位。
- segmentMask是散列运算的掩码,段掩码,等于ssize减1,也就是15.掩码的二进制各个位都是1,因为ssize的最大长度为65536,所以segmentShift最大值是16,SegmentMask的最大值是65535,对应到的二进制是16全1.
初始化每一个segment数组
输入参数initialCapacity是ConcurrentHashMap的初始化容量,loadfactor是每个segment的负载因子,在构造方法里需要用这两个参数来初始化数组中的每个segment。下文中提到的cap变量为segment里的HashEntry数组的长度等于initialCapacity除以ssize的倍数c,如果c大于1,就会取大于等于c的2的N次方的值,segment的容量threshold=(int)cap*loadFactor,默认情况下initialCapacity等于16,loadfactor等于0.75,通过运算cap=1,threshold=0。
定位Segment
ConcurrentHashMap使用分段锁Segment来保护不同段的数据,在插入和获取元素的时候,必须通过散列算法定位Segment。ConcurrentHashMap首先会使用hash的变种算法对hashCode进行一次再散列。进行再散列的目的就是为了减少散列冲突,使得元素能够均匀的分布在不同的Segment上,从而提高容器的存取效率。
ConcurrentHashMap的操作
ConcurrentHashMap的操作有三种,get、put、size。
get操作
Segment的get操作先经过一次散列,然后再使用这个散列值通过散列运算定位到Segment再通过散列算法定位到元素。
get操作的高效在于整个get过程不需要加锁,除非读到的值是空才会加锁重读。我们知道在HashTable容器的get方法是需要加锁的,在ConcurrentHashMap的get操作不需要枷锁的原因是,它的get方法里将共享变量都定义为volatile类型,如用于统计当前Segment大小的count字段和用于存储值的HashEntry的value。定义成Volatile的变量能够在线程之间保持可见性,能够被多线程同时读,并且保证不会读到过期的值,但是只能被单线程写,在get操作里只需要读不需要写共享变量count和value,所以可以不用加锁。之所以不会读到过期的数据是因为根据Java内存模型的先行原则,对volatile字段的写入操作先于读操作。
定位Segment使用的是元素的hashCode通过再散列后得到的值的高位,而定位HashEntry直接使用的是再散列后的值,其目的是避免两次散列后的值一样。
put操作
由于put操作需要对共享变量进行写入操作,所以为了线程安全,在操作共享变量时必须加锁,put方法首先定位到Segment,然后Segment里进行插入操作。插入操作需要经过两个步骤,1.判断是否需要对Segment里的HashEntry数组进行扩容,2.定位添加元素的位置,然后将其放在HashEntry数组里。
- 是否需要扩容
- 在插入元素前,首先会判断Segment力的HashEntry数组是否超出容量,如果超过阀值则对数组进行扩容,于HashMap扩容相比,Segment的扩容更加的恰当,因为HashMap是在插入新元素之后判断是否已经达到容量,如果达到了就进行扩容。很有可能造成扩容后没有元素插入,导致这次扩容就是一次无效的扩容
- 如何扩容
- 首先创建一个容量是原来容量的两倍,然后将原数组里面的元素进行再散列后插入到新的数组。为了高效,ConcurrentHashMap不会对整个容器进行扩容,而只是对某个Segment进行扩容。
size操作
统计整个ConcurrentHashMap里元素的大小,就必须统计所有Segment里元素的大小,最后求和。Segment里的全局变量count是一个volatile变量。最安全的办法就是在统计size的时候把所有Segment的put、remove、clean方法都锁住,但是这种方法的效率是非常低下的。在累加过程中count方法发生变化的几率非常的小,所有ConcurrentHashMap的做法先尝试2次通过不锁住的方式来统计各个Segment的大小。如果在统计过程中count发生了变化则再加锁的方式统计所有Segment的大小。
- ConcurrentHashMap
- ConcurrentHashMap
- ConcurrentHashMap
- ConcurrentHashMap
- ConcurrentHashMap
- ConcurrentHashMap
- ConcurrentHashMap
- ConcurrentHashMap
- ConcurrentHashMap
- ConcurrentHashMap
- ConcurrentHashMap
- ConcurrentHashMap
- ConcurrentHashMap
- ConcurrentHashMap
- ConcurrentHashMap
- concurrenthashmap
- ConcurrentHashMap
- ConcurrentHashMap
- Hexo+GitHub搭建个人站点(新!)
- 比特币的小额支付通道
- Ubuntu16.04 中 phpmyadmin安装 mysql卸载 mysql外部访问
- 基于Windows 7环境的WAPI无线网络应用层控制实现
- js对象
- ConcurrentHashMap
- d3.js 参考笔记
- Python之Matplotlib库常用函数大全(含注释)
- C++实验5-数组分离
- 【IOS】旋转图片和截取图片
- Tomcat启动后,Unable to compile class for JSP解决方法
- Python装饰器
- drawable各种属性
- js登录验证


