机器学习算法之SVM(1)结构风险最小化
来源:互联网 发布:大学生体育锻炼数据 编辑:程序博客网 时间:2024/06/08 10:08
一、SVM的策略是结构风险最小化
1、几何间隔
线性分类器比如感知机,目的是为了在空间中找出一个超平面,这个超平面使得分类错误率最小。在进行分类的时候,数据集中所有的点都对分界面有影响。

而SVM中使用几何间隔,就是点到分界面的距离
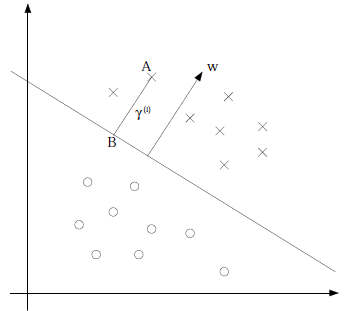
假设分界面为
由向量的计算得到B点的坐标
带入分界面中得:
现在定义当
那么我们将距离超平面最近的那个点距离定义为
于是有最优化目标为:
现在问题变成了不等式约束的最优化问题。
于是问题最终变成了二次规划问题:
2、结构风险最小化–拉格朗日对偶
假设一个不等式约束问题:
由朗格朗日算子得:
要求
即:
转换成对偶问题求解更方便,在满足KKT条件的情况下: 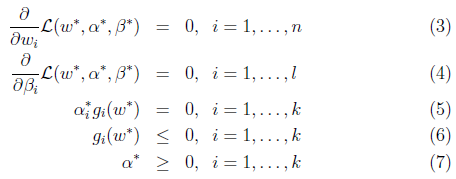
对偶等价:
将SVM的最优化目标和约束条件带入:
式中的第一项,如果
这不就是L-2正则项吗?
第二项则是经验风险啊。
于是我们可以看出,SVM的策略就是结构风险最小化,自带正则项。
二、核函数
1、内积
回到SVM的KKT条件中:
KKT条件:
目标函数:
其中
由于只计算原始特征
所以可以使用核函数,将在低维的数据映射到高维,从而可以解决非线性分类问题。同时,由于在低维中的计算等价于映射后的结果,又避免了计算量的问题。
2、求解参数
之后的首先求出
然后根据公式
最后,根据正负间隔之间的距离相同,可以求得b:
三、SVM与过拟合
1、虽然SVM的目标函数采用结构风险最小化策略,但是由于SVM在解决非线性分类的时候,引入了核函数,将低维的数据转换到了高维的空间中。显然维数越多,过拟合的风险越大。所以SVM也会过拟合。
2、核函数中的高斯核函数可以将低维数据映射到无穷维中,为什么映射到了无穷维中。
指数函数的泰勒展开式本身就是可以扩展到n维,高斯核只是参数换成了
3、离群点对于SVM同样会造成过拟合的现象,现在单开一章…..
- 机器学习算法之SVM(1)结构风险最小化
- 【机器学习】统计知识之经验风险最小化与结构风险最小化
- 机器学习 之 SVM VC维度、样本数目与经验风险最小化的关系
- 吴恩达机器学习之经验风险最小化
- 机器学习中的经验风险,期望风险和结构风险最小化
- 【斯坦福---机器学习】复习笔记之经验风险最小化
- (斯坦福机器学习笔记)之经验风险最小化
- 机器学习知识总结:代价函数与经验风险、结构风险最小化
- 【机器学习算法】之SVM
- 从结构化风险最小化角度理解SVM
- 从结构化风险最小化角度理解SVM
- 机器学习第九课,经验风险最小化
- 机器学习—经验风险最小化
- 系统学习机器学习之SVM(四)--SVM算法总结
- 机器学习算法入门之(四) SVM
- 机器学习十大算法之SVM
- 机器学习-SVM算法
- 机器学习算法-SVM
- vue引入 jquery 插件
- linux下关于mysql安装的一些问题
- Android studio 2.2 logcat 不打印log的问题
- -----------------------python&Tensorflow分割线------------------
- qt 之绘制 圆弧(抽奖圆盘)
- 机器学习算法之SVM(1)结构风险最小化
- Listview的基础使用
- 在react-native的项目中跳转到原生iOS页面
- docker挂载
- Qt5.7+Opencv2.4.9人脸识别(四)模型训练
- XML解析
- bzoj 1996: [Hnoi2010]chorus 合唱队 dp
- cocos2d-x 3.x窗口大小
- 8 种 NoSQL 数据库系统对比


