Kafka-[1]-Documentation-概述
来源:互联网 发布:海康威视 无网络视频 编辑:程序博客网 时间:2024/06/02 06:54
官方文档
http://kafka.apache.org/documentation.html#consumerapi
1.1 Introduction
First a few concepts
- Kafka is run as a cluster on one or more servers.
- The Kafka cluster stores streams of records in categories called topics.
- Each record consists of a key, a value, and a timestamp.
Kafka has four core APIs:
- The Producer API allows an application to publish a stream of records to one or more Kafka topics.
- The Consumer API allows an application to subscribe to one or more topics and process the stream of records produced to them.
- The Streams API allows an application to act as a stream processor, consuming an input stream from one or more topics and producing an output stream to one or more output topics, effectively transforming the input streams to output streams.
- The Connector API allows building and running reusable producers or consumers that connect Kafka topics to existing applications or data systems. For example, a connector to a relational database might capture every change to a table.
Producer API
The Producer API allows applications to send streams of data to topics in the Kafka cluster.
Examples showing how to use the producer are given in the javadocs.
To use the producer, you can use the following maven dependency:
<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>0.10.2.0</version></dependency>
Consumer API
The Consumer API allows applications to read streams of data from topics in the Kafka cluster.
Examples showing how to use the consumer are given in the javadocs.
To use the consumer, you can use the following maven dependency:
<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>0.10.2.0</version></dependency>
Streams API
The Streams API allows transforming streams of data from input topics to output topics.
Examples showing how to use this library are given in the javadocs
Additional documentation on using the Streams API is available here.
To use Kafka Streams you can use the following maven dependency
<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-streams</artifactId><version>0.10.2.0</version></dependency>
Connect API
The Connect API allows implementing connectors that continually pull from some source data system into Kafka or push from Kafka into some sink data system.
Many users of Connect won't need to use this API directly, though, they can use pre-built connectors without needing to write any code. Additional information on using Connect is available here.
Those who want to implement custom connectors can see the javadoc.
topic 、offset
For each topic, the Kafka cluster maintains a partitioned log that looks like this:
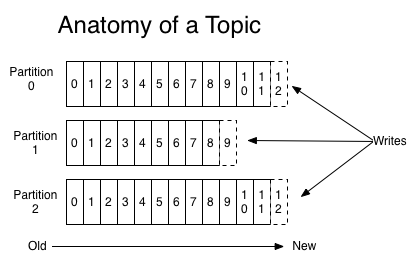
Each partition is an ordered, immutable sequence of records that is continually appended to—a structured commit log.
The records in the partitions are each assigned a sequential id number called the offset that uniquely identifies each record within the partition.
the partitions in the log serve several purposes:
First, they allow the log to scale beyond a size that will fit on a single server. each individual partition must fit on the servers that host it, but a topic may have many partitions so it can handle an arbitrary amount of data.
Second they act as the unit of parallelism—more on that in a bit
The Kafka cluster retains all published records using a configurable retention period(过期会discard). In fact, the only metadata retained on a per-consumer basis is the offset or position of that consumer in the log.This offset is controlled by the consumer
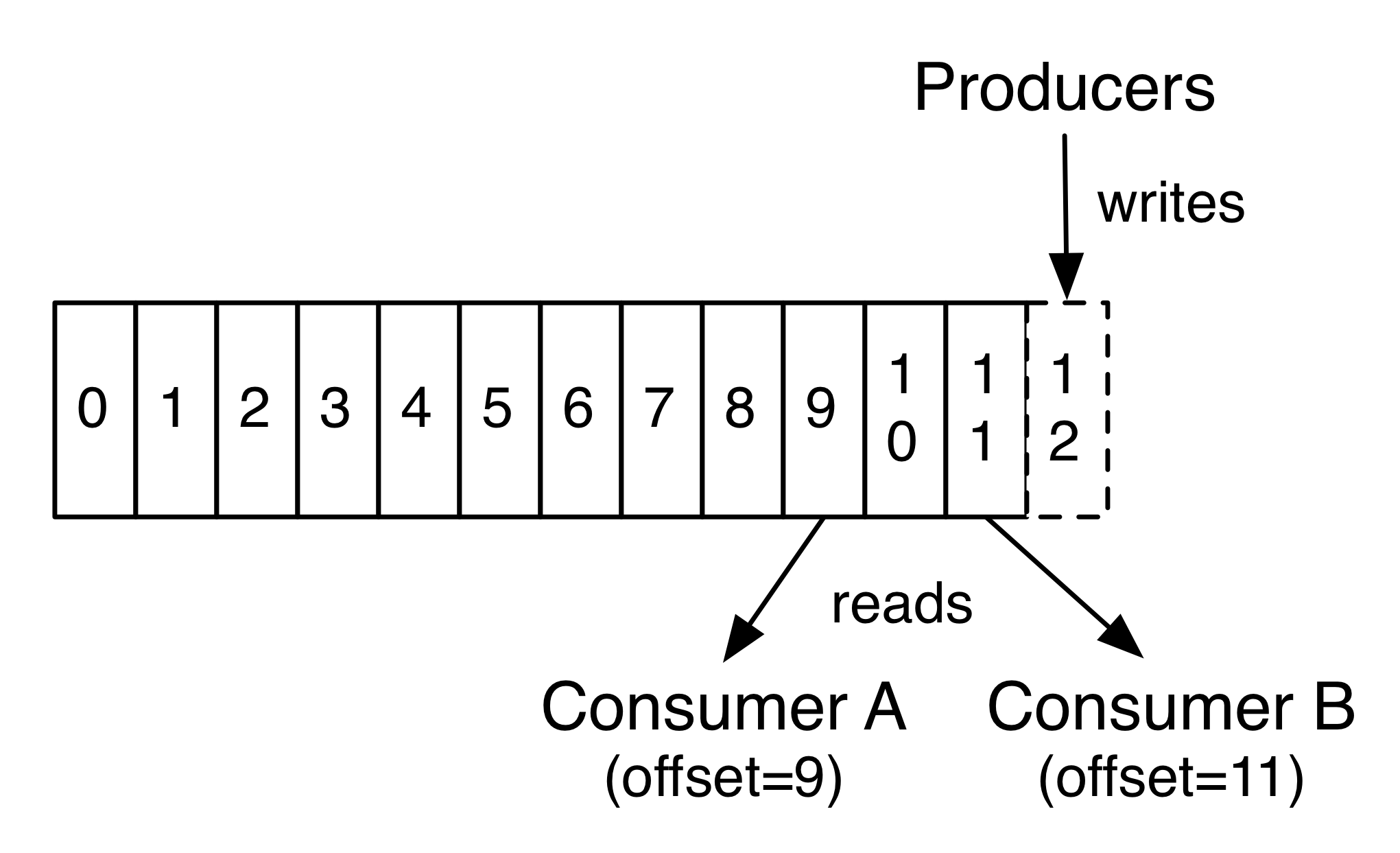
Producers
Producers publish data to the topics of their choice.
Consumers
Consumers label themselves with a consumer group name,
If all the consumer instances have the same consumer group, then the records will effectively be load balanced over the consumer instances.
If all the consumer instances have different consumer groups, then each record will be broadcast to all the consumer processes.
example: A two server Kafka cluster hosting four partitions (P0-P3) with two consumer groups. Consumer group A has two consumer instances and group B has four.
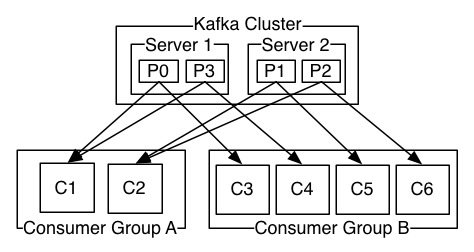
note: Kafka only provides a total order over records within a partition, not between different partitions in a topic. Per-partition ordering combined with the ability to partition data by key is sufficient for most applications. However, if you require a total order over records this can be achieved with a topic that has only one partition, though this will mean only one consumer process per consumer group.
Guarantees
At a high-level Kafka gives the following guarantees:
- Messages sent by a producer to a particular topic partition will be appended in the order they are sent. 按生产者发送的的顺序append
- A consumer instance sees records in the order they are stored in the log.消费者只能按appended的顺序看到records
- For a topic with replication factor N, 用于容灾
Kafka as a Messaging System
Kafka's 流概念与传统消息流的对比
传统消息有两种模型:队列和订阅发布,两者各有优劣。队列可衡量处理量,将处理data切分分配给多个消费者实例,但不是多订阅模式,一旦一则消息被消费,其他消费者无法再获取。订阅发布相反。
Kafka的消费组的概念汇总了两者的优点。作为一个queue允许消费组成员间divide up processing ;作为订阅发布,允许并行广播消息到多消费组。
传统队列在server端排序,在server端按顺发给consumers,但是是异步发送。所以可能到达不同consumer时乱序。为此有"exclusive consumer"的概念,同一时间只能有一个"exclusive consumer"消费一个队列,因此这不是并行的。
由于分区的存在,Kafka统一分区链接一个消费者解决保证data in order。不同分区间实现并行。注意:这意味消费者实例<=分区数,保证同一分区不被多个消费者同时消费
Messaging traditionally has two models: queuing and publish-subscribe. In a queue, a pool of consumers may read from a server and each record goes to one of them; in publish-subscribe the record is broadcast to all consumers. Each of these two models has a strength and a weakness. The strength of queuing is that it allows you to divide up the processing of data over multiple consumer instances, which lets you scale your processing. Unfortunately, queues aren't multi-subscriber—once one process reads the data it's gone. Publish-subscribe allows you broadcast data to multiple processes, but has no way of scaling processing since every message goes to every subscriber.
The consumer group concept in Kafka generalizes these two concepts. As with a queue the consumer group allows you to divide up processing over a collection of processes (the members of the consumer group). As with publish-subscribe, Kafka allows you to broadcast messages to multiple consumer groups.
"exclusive consumer" that allows only one process to consume from a queue, but of course this means that there is no parallelism in processing.
Kafka does it better. Kafka is able to provide both ordering guarantees and load balancing over a pool of consumer processes. This is achieved by assigning the partitions in the topic to the consumers in the consumer group so that each partition is consumed by exactly one consumer in the group. By doing this we ensure that the consumer is the only reader of that partition and consumes the data in order. Since there are many partitions this still balances the load over many consumer instances.
Note however that there cannot be more consumer instances in a consumer group than partitions.
Kafka as a Storage System
任何发布与消费消息分离的队列实际也可看做是一个用于存储动态消息的强有力存储系统。Kafka尤其如此,在要求存储严密准确,允许客户端自身控制读取分区的场景中,Kafka不失为一个良好的存储系统:
1:可靠的存储机制(只有消息及备份被有效存储后,才会与生产者确认写成功操作)
2:不依赖磁盘容量的良好计量存储性能
Any message queue that allows publishing messages decoupled from consuming them is effectively acting as a storage system for the in-flight messages. What is different about Kafka is that it is a very good storage system.
Data written to Kafka is written to disk and replicated for fault-tolerance. Kafka allows producers to wait on acknowledgement so that a write isn't considered complete until it is fully replicated and guaranteed to persist even if the server written to fails.
The disk structures Kafka uses scale well—Kafka will perform the same whether you have 50 KB or 50 TB of persistent data on the server.
As a result of taking storage seriously and allowing the clients to control their read position, you can think of Kafka as a kind of special purpose distributed filesystem dedicated to high-performance, low-latency commit log storage, replication, and propagation.
Kafka for Stream Processing
stream processor:从输入topics拿到continual streams做处理后,产生continual streams 到输出topics。其中简单的处理可直接使用 producer and consumer APIs。对于一些复杂转换,提供有Streams API:允许做一些特殊处理如流间的聚合和流间的join
Putting the Pieces Together
消息数据可通过订阅功能,使得系统可以当被订阅的数据莅临时及时得知并予以处理,这部分数据暂称为即到数据
借助存储功能和低延迟的订阅功能,流应用可以同样的方式处理过往数据和即到数据
Messaging system allows processing future messages that will arrive after you subscribe. Applications built in this way process future data as it arrives
By combining storage and low-latency subscriptions, streaming applications can treat both past and future data the same way.
1.2 Use Cases
Messaging
与 traditional messaging systems such as ActiveMQ or RabbitMQ.相比拟
Message brokers are used for a variety of reasons (to decouple processing from data producers, to buffer unprocessed messages, etc).
In comparison to most messaging systems:
- better throughput, built-in partitioning, replication, and fault-tolerance
Website Activity Tracking
The original use case for Kafka was to be able to rebuild a user activity tracking pipeline as a set of real-time publish-subscribe feeds. This means site activity (page views, searches, or other actions users may take) is published to central topics with one topic per activity type. These feeds are available for subscription for a range of use cases including real-time processing, real-time monitoring, and loading into Hadoop or offline data warehousing systems for offline processing and reporting.
Log Aggregation
相比于 log-centric systems( Scribe or Flume) 由其备份,端到端的低延迟特性,Kafka可提供同等优质的服务。
日志聚合通常是将物理日志文件从servers收集后统一存储于类似于 file server or HDFS 的中心系统中待处理,Kafka抽象掉了文件细节,并提供一个清晰抽象后的日志对象或事件数据的消息流。允许低延迟处理并已多数据源轻松对外提供数据和分布式数据消费
Log aggregation typically collects physical log files off servers and puts them in a central place (a file server or HDFS perhaps) for processing. Kafka abstracts away the details of files and gives a cleaner abstraction of log or event data as a stream of messages. This allows for lower-latency processing and easier support for multiple data sources and distributed data consumption.
Stream Processing
Many users of Kafka process data in processing pipelines consisting of multiple stages, where raw input data is consumed from Kafka topics and then aggregated, enriched, or otherwise transformed into new topics for further consumption or follow-up processing.
0.10.0.0开始提供 Kafka Streams流处理库(类似的开源流处理 Apache Storm and Apache Samza.)
Kafka Streams :Starting in 0.10.0.0, a light-weight but powerful stream processing library
- Kafka-[1]-Documentation-概述
- Kafka 0.9.0 Documentation
- 《Kafka 0.9.0 Documentation》----Design
- Kafka-[2]-Documentation-单机QuickStart
- Kafka概述
- Kafka概述
- Kafka 概述
- kafka概述
- kafka概述
- 《Kafka 0.9.0 Documentation》----Getting Started
- Kafka (一) 概述
- TinyXml Documentation 2.5.1
- ffmpeg Documentation-1 简介
- Documentation
- Documentation
- Kafka概述—消息队列
- mysql-5.7.5-labs-http-documentation中文翻译-第一章 概述
- kafka(1)- kafka入门
- 欢迎使用CSDN-markdown编辑器
- 深入理解sping AOP
- 安装Dedecms模板的详细步骤
- SQL语句的优化
- 安卓7.0 加载libsqlite.so文件失败
- Kafka-[1]-Documentation-概述
- 某场小考(1)
- 关于使用sklearn进行数据预处理 —— 归一化/标准化/正则化
- 初见Hibernate
- 《Spring in action》——学习总结(一)
- 简明Pyhton教程余下基础内容
- heatmap.js调用百度地图api做热力图
- Java8新特性接口的增强之default方法
- 表单处理的方案与注意事项(servlet)


