HDFS:edit log & fsimage
来源:互联网 发布:js string 补0 编辑:程序博客网 时间:2024/04/28 07:43
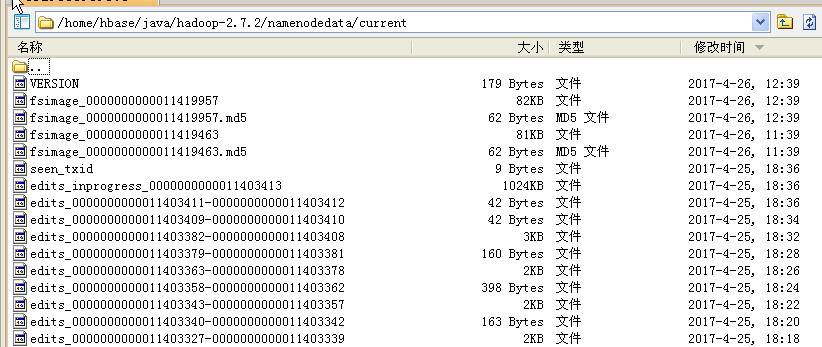
在NameNode的${dfs.namenode.name.dir}/current目录下,有这样几个文件:
在数据库系统中,log是用于记录写操作的日志的,并使用该Log进行备份、恢复数据等工作。有关写的操作的记录的,目前见过了两种:关系型数据库的log,HBase的WALs等等都是这样的写操作的日志。
HDFS也采用了类似的机制。在HDFS中,会将第一次的文件操作,看作一个事务。譬如说一个文件的创建、文件内容追加、文件移动等等写操作。从这个角度来看呢,fsimage文件就相当于HDFS 的元数据的数据库文件了,而edit log就相当于是操作日志文件了。
Fsimage:
每个fsimage文件都会包括整个文件系统中所有的目录和文件inodes信息。每个inode是HDFS内部的一个代表文件、或者目录的元数据,如果inode代表一个文件,它包括:文件的备份级别、修改时间、访问时间、访问权限、block的size、所有blocks的构成等信息。如果inode代表一个目录,它包括:修改时间、权限、其它相关元数据等。
Edit log:
它在逻辑上,是一个实例(也就是说可以理解为一个对象),实际上是由多个文件组成的。每个文件都被称为一个segment,并以 edits_作为前缀,文件名后面的是事务id。
譬如上面的:edits_0000000000011403382-0000000000011403408 就代表该文件中放的是
事务Id为0000000000011403382到0000000000011403408之间的那些事务的信息。当客户端完成了一个写操作,并收到namenode的success的响应码时,Namenode才会将该事务信息写到editlog文件中。
为什么将事务信息处理后不直接写到fsimage中?
如果这样做的话,也就是每个write操作完毕时,都去更新fsimage文件,在一个大的文件系统中,文件就会变得很大,上GB都是有可能的,那么将是一个缓慢的过程。
先写到edit log中,怎么合并到fsimage中呢?
解决方案是启动一个Secondary namenode。它的存在就是在内存中生成Primary NameNode的fsimage文件。它的处理过程是这样的:
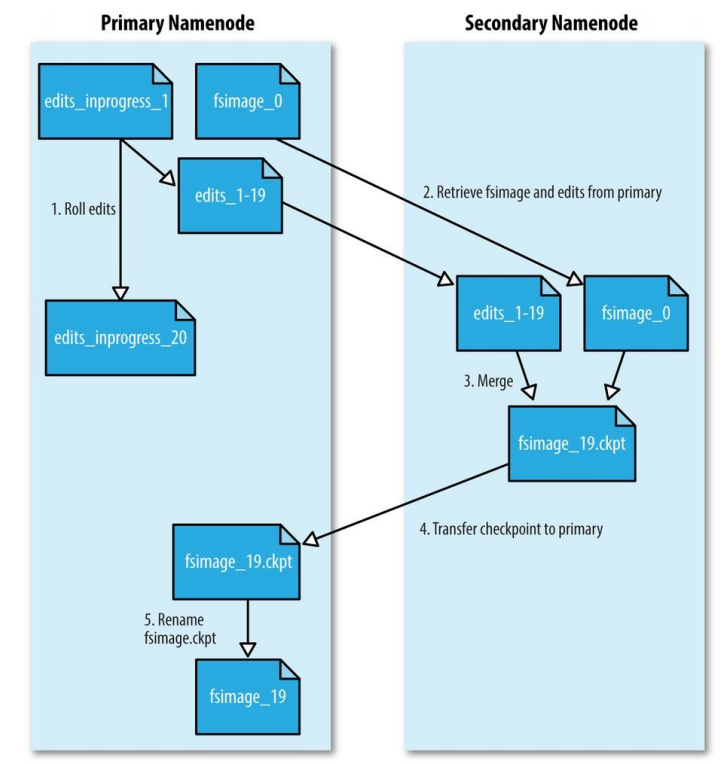
1、Secondary 告诉Primary去滚动它的in-progress edits文件,这样新来的write操作就会放到一个新的edit 文件中。同时Primary也会更新seen_txid文件。
2、Secondary 通过HTTP GET方式从Primary获取到最新的fsimage和edits文件
3、Secondary 将fsimage加载到内存中,并从edits文件中取出每一次事务,应用到fsimage上,如此就产生了一个合并的新的fsimage文件。
4、Secondary将这个新合并的fsimage文件通过HTTP PUT发到Primary,Primary把它保存到临时.ckpt文件中。
5、Primary再把临时文件重命名,并使它可用。
同时,这也是为啥Secondary需要与Primary类似的内存配置,并且需要部署在一个单独的机器。
NameNode为什么不自己做合并,而是由Seconary NameNode来做呢?
NameNode不是不自己做,只是在启动时做。
首先,所有的写操作都会经过NameNode来处理,所以faimage的内容,在NameNode的内存里,
肯定是有同样的一份。所以在运行期间,不需要通过合并来保证与内存一致。
其次,NameNode只是在启动时才进行合并操作。
也正由于这两点原因,所以需要由Secondary NameNode来完成了。不然NameNode运行了很长时间,比如累积了大量的editlog,而fsimage又是NameNode启动后的那一次合并后的状态。那么NameNode重启后必然要进行长时间的合并操作。
- HDFS:edit log & fsimage
- HDFS中SecondaryNameNode合并fsimage和edit log操作
- hadoop 2.2.0 关于 fsimage & edit log 的相关配置
- hadoop 2.2.0 关于 fsimage & edit log 的相关配置
- Hadoop2.6 HDFS EDIT LOG分析
- HDFS --- Load FSNameSystem, FSImage, and initialize FSEditlog
- HDFS fsimage和edits合并实现原理
- FSImage
- hadoop 2.2.0 fsimage和edit logs的处理逻辑
- Hadoop中的fsimage和edits log编辑日志
- Hadoop中的fsimage和edits log编辑日志
- HDFS源码分析之FSImage文件内容(一)总体格式
- Hadoop深入学习:HDFS主要流程——SNN合并fsimage和编辑日志
- HDFS追本溯源:HDFS操作的逻辑流程与源码解析 【SNN对fsimage和editslog文件的合并流程-------很重要】
- NameNode的FSImage以及EditLog的简化模型设计文档(HDFS-1073:Simpler model for Namenode's FsImage and EditLogs)
- hadoop的Namenode元数据持久化机制(fsImage、Edit)与secondaryNamenode的真正作用详解
- 启动hadoop报ERROR org.apache.hadoop.hdfs.server.namenode.FSImage: Failed to load image from FSImageFile
- 使用flume搜集服务器log到hdfs
- 案例:java中的基本排序
- 误删除Oracle数据库数据的恢复方法
- java编程思想读书笔记----第十四章 类型信息
- 正则表达式
- c++中内敛函数与宏定义的区别
- HDFS:edit log & fsimage
- 字符串共有最大的子序列数
- 常用PHP函数
- 入门训练 序列求和
- 如何把按钮点击单独放到一个类里面详解
- 移动端测试需要考虑的测试点
- BAT 批处理脚本教程
- JNI学习积累之一 ---- 常用函数大全
- mysql自增序列 sequence


