FME中通过HTMLExtractor向HTML要数据
来源:互联网 发布:淘宝优惠券公开推广 编辑:程序博客网 时间:2024/06/05 11:23
如何不断扩充数据中心的数据规模,提升数据挖掘的价值,这是我们思考的问题,数据一方面来自于内部生产,一部分数据可以来自于互联网,互联网上的数据体量庞大,形态多样,之前blog里很多FMEer已经提出了方案,比如json,xml,正则表达式等等,但对于比较松散的HTML如何进行数据解析提取呢?我问了一下度娘,貌似没有FME下的文章,恰逢今天有时间,就写一点关于HTML提取的东东,算是自己做的笔记吧!
这次我要提取的范例数据来自国土资源局土地招拍挂系统,我要提取上面的交易结果以及地块信息,样式如下图:

图1:交易结果列表

图2:地块信息
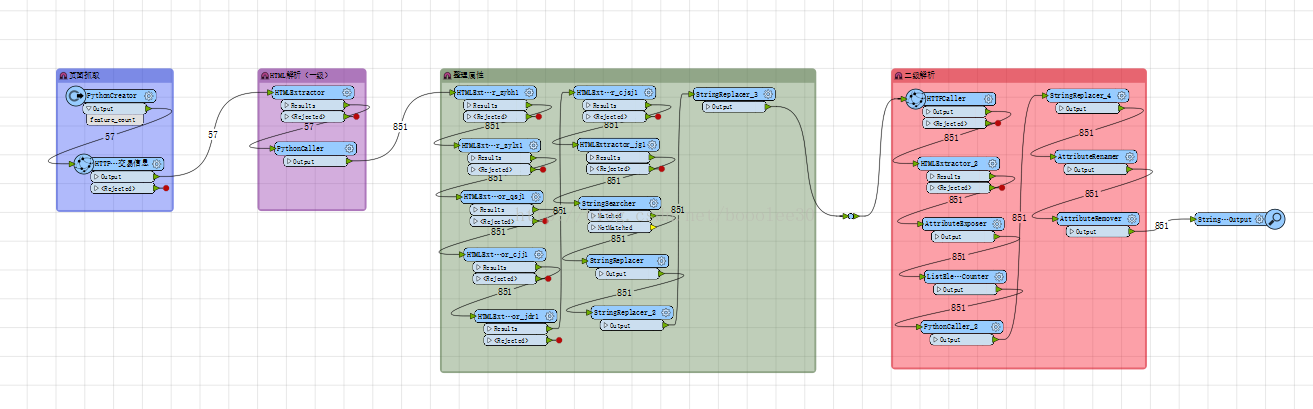
图3:转换工程
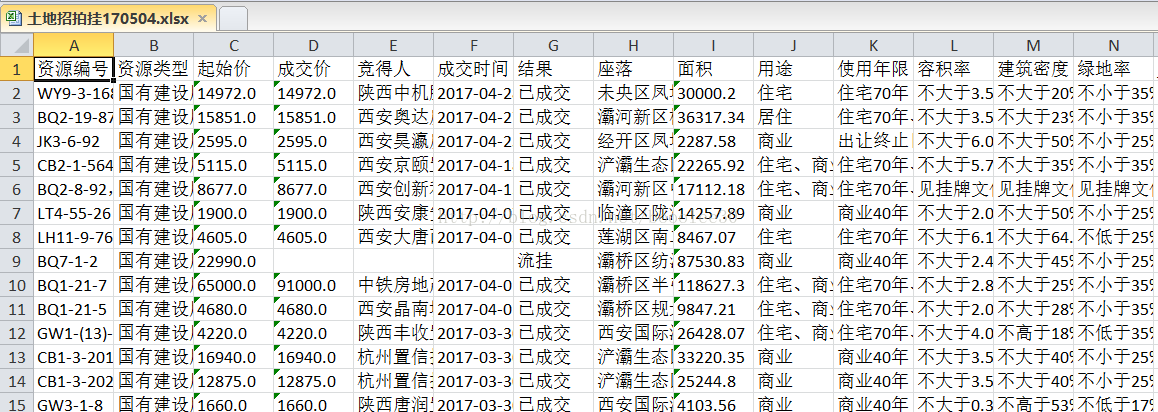
图4:提取后的数据
在这个转换工程里,用到了几个转换器,它们是:pythonCreator,HTTPCaller,HTMLExtractor、PythonCaller、StringSearcher、StringReplacer、AttributeExposer、AttributeRenamer、AttributeRemover
本文重点介绍一下HTMLExtractor,转换器的参数如下图:
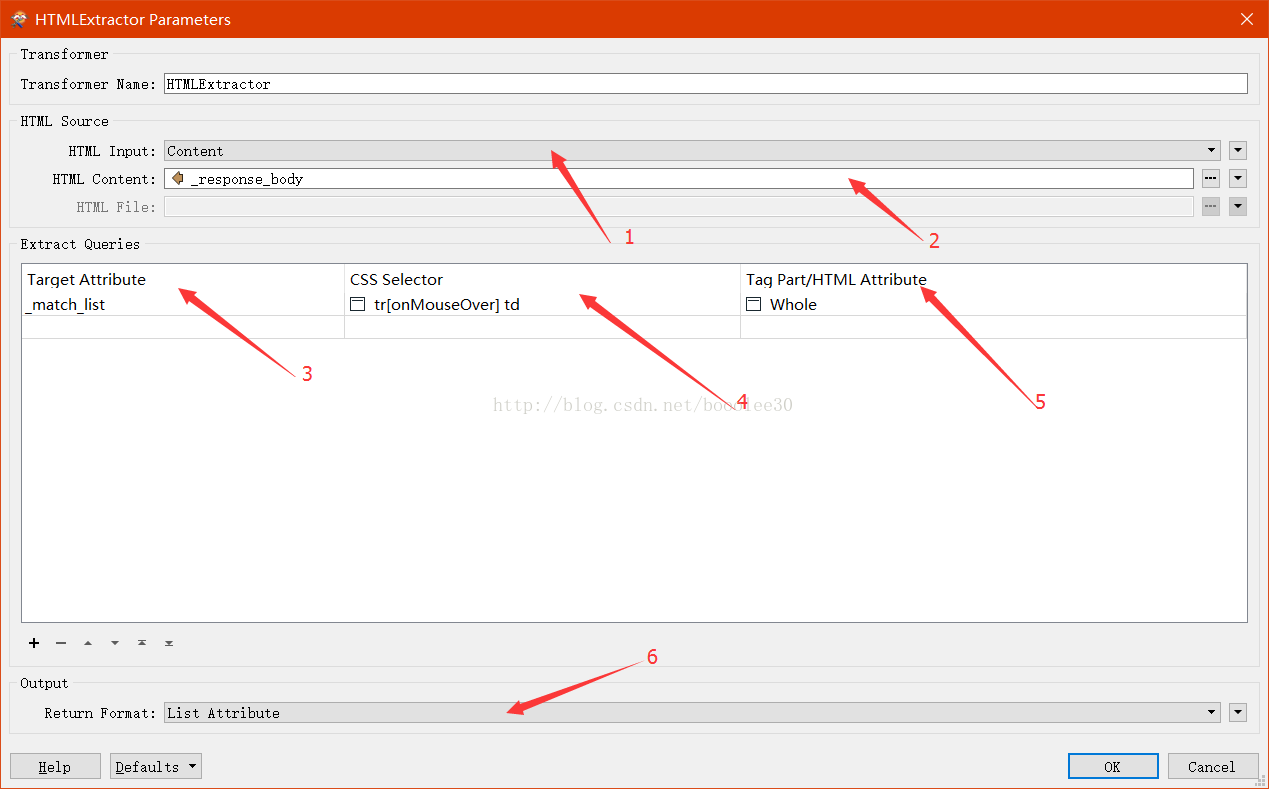
图5:HTMLExtractor参数
图上标注的参数依次是:
1、 HTML Input:HTML的内容来源,可以是content,表示来源于传入的属性、参数等,也可以是File,表示来源于一个已存在的HTML文件。
2、 HTML Content:本案例用的是content作为源,与HttpCaller连用,HTML存放于_response_body属性中。如果是File作为源,则需要设置HTML File为文件路径。
3、 Target Attribute:设置一个属性(列表)名称,这个属性名称将包含HTML解析的结果。
4、 CSS Selector:设置CSS选择器,类似正则表达式,但用起来更简单,特别适合解析HTML。
5、 Tag Part/HTML Attribute:可以设置为Value(匹配标签里的值)、Whole(匹配的标签和值)、或者输入匹配标签拥有的一个属性名称,比如<a>标记的href属性。
6、 Return Format:可以设置为List Attribute,则将所有匹配的内容作为一个list返回,如果为First Match,则仅返回第一个匹配的内容。
举个栗子,下面是我要匹配的交易结果HTML源文件:
<tr class="TR2" onMouseOver="this.className='TR3';" onMouseOut="this.className='TR2';">
<td height="31" align="left" class="TD1"><img src="images/arrow_yellow.gif">2</td>
<td class="TD1" align="left">BQ2-19-87</td>
<td class="TD1" align="left">国有建设用地使用权</td>
<td class="TD1" align="left">15851.0万元</td>
<td class="TD1" align="left">15851.0万元</td>
<td class="TD1" align="left">西安奥达房地产开发有限责任公司</td>
<td class="TD1" align="left">2017-04-27 16:00</td>
<td class="TD1" align="center" style="color:#FF0000;cursor:pointer;" onClick="window.open('publics/ResourceFrame.jsp?id=933&lx=L','','left=10,top=10,width=890,height=650,scrollbars=yes,resizable=yes,status=yes')">已成交</td>
</tr>
我要把红色的内容提取出来,我只需要简单的写一句CSS选择器进行匹配即可,但在写之前一般是要先整理分析一下HTML源文件,找出可以用于匹配的特征,提高匹配的准确度,减少其他杂质数据被提取出来。
因为HTML源文件中有大量的<td>,所以直接匹配td是不行的,经过分析我找到了特征,CSS选择器为:tr[onMouseOver] td。意思是拥有onMouseOver属性的tr标记下的td标记。
就这么简单,获取的数据还有少量杂质,再用其他的转换器清洗一下即可。
另外,最近正则表达式呼声很高,必须承认,正则表达式非常强大,但有些工作还是有更简单的办法,杀鸡焉用牛刀,对于HTML,通过编写CSS选择器应用HTMLExtractor转换器来解析数据,更加敏捷高效!
这次我要提取的范例数据来自国土资源局土地招拍挂系统,我要提取上面的交易结果以及地块信息,样式如下图:
图1:交易结果列表
图2:地块信息
图3:转换工程
图4:提取后的数据
在这个转换工程里,用到了几个转换器,它们是:pythonCreator,HTTPCaller,HTMLExtractor、PythonCaller、StringSearcher、StringReplacer、AttributeExposer、AttributeRenamer、AttributeRemover
本文重点介绍一下HTMLExtractor,转换器的参数如下图:
图5:HTMLExtractor参数
图上标注的参数依次是:
1、 HTML Input:HTML的内容来源,可以是content,表示来源于传入的属性、参数等,也可以是File,表示来源于一个已存在的HTML文件。
2、 HTML Content:本案例用的是content作为源,与HttpCaller连用,HTML存放于_response_body属性中。如果是File作为源,则需要设置HTML File为文件路径。
3、 Target Attribute:设置一个属性(列表)名称,这个属性名称将包含HTML解析的结果。
4、 CSS Selector:设置CSS选择器,类似正则表达式,但用起来更简单,特别适合解析HTML。
5、 Tag Part/HTML Attribute:可以设置为Value(匹配标签里的值)、Whole(匹配的标签和值)、或者输入匹配标签拥有的一个属性名称,比如<a>标记的href属性。
6、 Return Format:可以设置为List Attribute,则将所有匹配的内容作为一个list返回,如果为First Match,则仅返回第一个匹配的内容。
举个栗子,下面是我要匹配的交易结果HTML源文件:
<tr class="TR2" onMouseOver="this.className='TR3';" onMouseOut="this.className='TR2';">
<td height="31" align="left" class="TD1"><img src="images/arrow_yellow.gif">2</td>
<td class="TD1" align="left">BQ2-19-87</td>
<td class="TD1" align="left">国有建设用地使用权</td>
<td class="TD1" align="left">15851.0万元</td>
<td class="TD1" align="left">15851.0万元</td>
<td class="TD1" align="left">西安奥达房地产开发有限责任公司</td>
<td class="TD1" align="left">2017-04-27 16:00</td>
<td class="TD1" align="center" style="color:#FF0000;cursor:pointer;" onClick="window.open('publics/ResourceFrame.jsp?id=933&lx=L','','left=10,top=10,width=890,height=650,scrollbars=yes,resizable=yes,status=yes')">已成交</td>
</tr>
我要把红色的内容提取出来,我只需要简单的写一句CSS选择器进行匹配即可,但在写之前一般是要先整理分析一下HTML源文件,找出可以用于匹配的特征,提高匹配的准确度,减少其他杂质数据被提取出来。
因为HTML源文件中有大量的<td>,所以直接匹配td是不行的,经过分析我找到了特征,CSS选择器为:tr[onMouseOver] td。意思是拥有onMouseOver属性的tr标记下的td标记。
就这么简单,获取的数据还有少量杂质,再用其他的转换器清洗一下即可。
另外,最近正则表达式呼声很高,必须承认,正则表达式非常强大,但有些工作还是有更简单的办法,杀鸡焉用牛刀,对于HTML,通过编写CSS选择器应用HTMLExtractor转换器来解析数据,更加敏捷高效!
0 0
- FME中通过HTMLExtractor向HTML要数据
- 通过HTMLExtractor向HTML要数据
- 通过工具向Oracle中上载数据
- 通过驱动向Excle中写入数据
- 万能数据转换fme
- 通过VB写的ACTIVEX向本地文件中写数据
- GameKit中通过GKSession向联机设备发送数据
- 通过场景运行脚本向数据库中插入数据失败
- 通过JavaScript函数向网页中输出数据
- Android通过RandomAccessFile 向文件中写入数据
- openlayers中通过拼接xml向postgis插入数据
- 通过 httpclientget 方法 向服务器中请求数据
- 前台post通过web api向数据库中添加数据
- 通过读取文件向mysql表单中插入某几列数据
- 通过JDBC向数据库中存储&读取Blob数据
- 向视图中插入数据的问题(通过触发器向视图插入数据)
- FME读写国内MAPGIS数据
- android中向通过contentProvider向数据库中插入数据的实现
- 股票数据的获取分析
- NOIP2007提高组——矩阵取数游戏(game)
- datagrid选中行
- 【js】日期字符串比较大小
- 仿蘑菇街,蜜芽宝贝,京东商品详情界面,与NestedScroll滑动
- FME中通过HTMLExtractor向HTML要数据
- OpenAI Gym学习
- 准确率的概念
- 深入理解JVM性能调优
- Depends:libreoffice-base but it is not going to be installed
- sql数据操作0509
- POJ3613 Cow Relays 倍增floyd求最短路
- 剑指offer 23. 从上往下打印二叉树
- jsp中添加验证码


