生成对抗网络介绍与原理分析
来源:互联网 发布:网络洗脑神曲 编辑:程序博客网 时间:2024/05/22 17:06
生成对抗网络介绍与原理分析
简介
生成对抗网络就是利用生成模型G和判别模型D的的相互博弈,提升生成模型的生成能力和判别模型的判别能力,直至生成模型所生成的与原始数据难以分辨。
原理
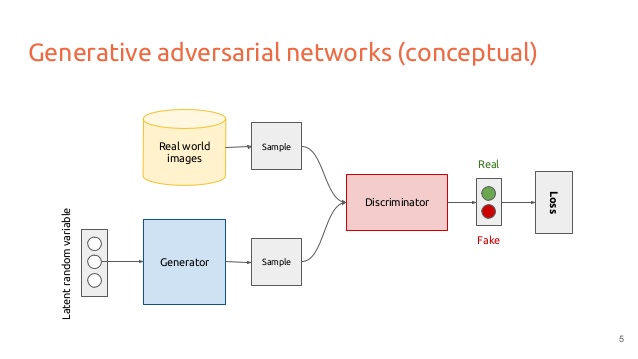
判别模型D:不断优化D,使其输入真实数据x时输出1,输入生成数据G(z)时输出0.
生成模型G:不断优化G,使其生成的数据被判断为真(输出1).
公式

最大化D:D(X)->1,D(G(z))->0,log内趋近于1,整个值变大。
最小化G,D(G(z))->0,log内趋近于0,整个值变小。
算法

K次选了D,一次训练G,是为了判别得准确,避免较差的生成数据合格。
将求最大值转换为求最小值 
在连续空间中 
对任意的非零实数 m 和 n, 且实数值
表达式
所以目标函数: 
当
理论运行图

- a图表示初始状态
- b图表示,保持G不动,优化D,知道分类器的准确率最高
- c图表示保持D不动,优化G,直到混淆程度最高
- d图表示,多次迭代后,终于使得G能够完全与M产生的数据一致,而D再也鉴别不出是原始数据还是由生成模型所产生的数据,从而认为G就是M
代码(TensorFlow)
from __future__ import absolute_importfrom __future__ import print_functionfrom __future__ import unicode_literalsfrom __future__ import divisionimport argparseimport numpy as npfrom scipy.stats import normimport tensorflow as tfimport matplotlib.pyplot as pltfrom matplotlib import animationimport seaborn as snssns.set(color_codes=True)seed = 42np.random.seed(seed)tf.set_random_seed(seed)class DataDistribution(object): def __init__(self): self.mu = 4 self.sigma = 0.5 def sample(self, N): samples = np.random.normal(self.mu, self.sigma, N) samples.sort() return samplesclass GeneratorDistribution(object): def __init__(self, range): self.range = range def sample(self, N): return np.linspace(-self.range, self.range, N) + \ np.random.random(N) * 0.01def linear(input, output_dim, scope=None, stddev=1.0): norm = tf.random_normal_initializer(stddev=stddev) const = tf.constant_initializer(0.0) with tf.variable_scope(scope or 'linear'): w = tf.get_variable('w', [input.get_shape()[1], output_dim], initializer=norm) b = tf.get_variable('b', [output_dim], initializer=const) return tf.matmul(input, w) + bdef generator(input, h_dim): h0 = tf.nn.softplus(linear(input, h_dim, 'g0')) h1 = linear(h0, 1, 'g1') return h1def discriminator(input, h_dim, minibatch_layer=True): h0 = tf.tanh(linear(input, h_dim * 2, 'd0')) h1 = tf.tanh(linear(h0, h_dim * 2, 'd1')) # without the minibatch layer, the discriminator needs an additional layer # to have enough capacity to separate the two distributions correctly if minibatch_layer: h2 = minibatch(h1) else: h2 = tf.tanh(linear(h1, h_dim * 2, scope='d2')) h3 = tf.sigmoid(linear(h2, 1, scope='d3')) return h3def minibatch(input, num_kernels=5, kernel_dim=3): x = linear(input, num_kernels * kernel_dim, scope='minibatch', stddev=0.02) activation = tf.reshape(x, (-1, num_kernels, kernel_dim)) diffs = tf.expand_dims(activation, 3) - tf.expand_dims(tf.transpose(activation, [1, 2, 0]), 0) eps = tf.expand_dims(np.eye(int(input.get_shape()[0]), dtype=np.float32), 1) abs_diffs = tf.reduce_sum(tf.abs(diffs), 2) + eps minibatch_features = tf.reduce_sum(tf.exp(-abs_diffs), 2) return tf.concat(1, [input, minibatch_features])def optimizer(loss, var_list): initial_learning_rate = 0.005 decay = 0.95 num_decay_steps = 150 batch = tf.Variable(0) learning_rate = tf.train.exponential_decay( initial_learning_rate, batch, num_decay_steps, decay, staircase=True ) optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize( loss, global_step=batch, var_list=var_list ) return optimizerclass GAN(object): def __init__(self, data, gen, num_steps, batch_size, minibatch, log_every, anim_path): self.data = data self.gen = gen self.num_steps = num_steps self.batch_size = batch_size self.minibatch = minibatch self.log_every = log_every self.mlp_hidden_size = 4 self.anim_path = anim_path self.anim_frames = [] self._create_model() def _create_model(self): # In order to make sure that the discriminator is providing useful gradient # information to the generator from the start, we're going to pretrain the # discriminator using a maximum likelihood objective. We define the network # for this pretraining step scoped as D_pre. with tf.variable_scope('D_pre'): self.pre_input = tf.placeholder(tf.float32, shape=(self.batch_size, 1)) self.pre_labels = tf.placeholder(tf.float32, shape=(self.batch_size, 1)) D_pre = discriminator(self.pre_input, self.mlp_hidden_size, self.minibatch) self.pre_loss = tf.reduce_mean(tf.square(D_pre - self.pre_labels)) self.pre_opt = optimizer(self.pre_loss, None) # This defines the generator network - it takes samples from a noise # distribution as input, and passes them through an MLP. with tf.variable_scope('G'): self.z = tf.placeholder(tf.float32, shape=(self.batch_size, 1)) self.G = generator(self.z, self.mlp_hidden_size) # The discriminator tries to tell the difference between samples from the # true data distribution (self.x) and the generated samples (self.z). # # Here we create two copies of the discriminator network (that share parameters), # as you cannot use the same network with different inputs in TensorFlow. with tf.variable_scope('D') as scope: self.x = tf.placeholder(tf.float32, shape=(self.batch_size, 1)) self.D1 = discriminator(self.x, self.mlp_hidden_size, self.minibatch) scope.reuse_variables() self.D2 = discriminator(self.G, self.mlp_hidden_size, self.minibatch) # Define the loss for discriminator and generator networks (see the original # paper for details), and create optimizers for both #self.pre_loss = tf.reduce_mean(tf.square(D_pre - self.pre_labels)) self.loss_d = tf.reduce_mean(-tf.log(self.D1) - tf.log(1 - self.D2)) self.loss_g = tf.reduce_mean(-tf.log(self.D2)) vars = tf.trainable_variables() self.d_pre_params = [v for v in vars if v.name.startswith('D_pre/')] self.d_params = [v for v in vars if v.name.startswith('D/')] self.g_params = [v for v in vars if v.name.startswith('G/')] #self.pre_opt = optimizer(self.pre_loss, self.d_pre_params) self.opt_d = optimizer(self.loss_d, self.d_params) self.opt_g = optimizer(self.loss_g, self.g_params) def train(self): with tf.Session() as session: tf.initialize_all_variables().run() # pretraining discriminator num_pretrain_steps = 1000 for step in xrange(num_pretrain_steps): d = (np.random.random(self.batch_size) - 0.5) * 10.0 labels = norm.pdf(d, loc=self.data.mu, scale=self.data.sigma) pretrain_loss, _ = session.run([self.pre_loss, self.pre_opt], { self.pre_input: np.reshape(d, (self.batch_size, 1)), self.pre_labels: np.reshape(labels, (self.batch_size, 1)) }) self.weightsD = session.run(self.d_pre_params) # copy weights from pre-training over to new D network for i, v in enumerate(self.d_params): session.run(v.assign(self.weightsD[i])) for step in xrange(self.num_steps): # update discriminator x = self.data.sample(self.batch_size) z = self.gen.sample(self.batch_size) loss_d, _ = session.run([self.loss_d, self.opt_d], { self.x: np.reshape(x, (self.batch_size, 1)), self.z: np.reshape(z, (self.batch_size, 1)) }) # update generator z = self.gen.sample(self.batch_size) loss_g, _ = session.run([self.loss_g, self.opt_g], { self.z: np.reshape(z, (self.batch_size, 1)) }) if step % self.log_every == 0: #pass print('{}: {}\t{}'.format(step, loss_d, loss_g)) if self.anim_path: self.anim_frames.append(self._samples(session)) if self.anim_path: self._save_animation() else: self._plot_distributions(session) def _samples(self, session, num_points=10000, num_bins=100): ''' Return a tuple (db, pd, pg), where db is the current decision boundary, pd is a histogram of samples from the data distribution, and pg is a histogram of generated samples. ''' xs = np.linspace(-self.gen.range, self.gen.range, num_points) bins = np.linspace(-self.gen.range, self.gen.range, num_bins) # decision boundary db = np.zeros((num_points, 1)) for i in range(num_points // self.batch_size): db[self.batch_size * i:self.batch_size * (i + 1)] = session.run(self.D1, { self.x: np.reshape( xs[self.batch_size * i:self.batch_size * (i + 1)], (self.batch_size, 1) ) }) # data distribution d = self.data.sample(num_points) pd, _ = np.histogram(d, bins=bins, density=True) # generated samples zs = np.linspace(-self.gen.range, self.gen.range, num_points) g = np.zeros((num_points, 1)) for i in range(num_points // self.batch_size): g[self.batch_size * i:self.batch_size * (i + 1)] = session.run(self.G, { self.z: np.reshape( zs[self.batch_size * i:self.batch_size * (i + 1)], (self.batch_size, 1) ) }) pg, _ = np.histogram(g, bins=bins, density=True) return db, pd, pg def _plot_distributions(self, session): db, pd, pg = self._samples(session) db_x = np.linspace(-self.gen.range, self.gen.range, len(db)) p_x = np.linspace(-self.gen.range, self.gen.range, len(pd)) f, ax = plt.subplots(1) ax.plot(db_x, db, label='decision boundary') ax.set_ylim(0, 1) plt.plot(p_x, pd, label='real data') plt.plot(p_x, pg, label='generated data') plt.title('1D Generative Adversarial Network') plt.xlabel('Data values') plt.ylabel('Probability density') plt.legend() plt.show() def _save_animation(self): f, ax = plt.subplots(figsize=(6, 4)) f.suptitle('1D Generative Adversarial Network', fontsize=15) plt.xlabel('Data values') plt.ylabel('Probability density') ax.set_xlim(-6, 6) ax.set_ylim(0, 1.4) line_db, = ax.plot([], [], label='decision boundary') line_pd, = ax.plot([], [], label='real data') line_pg, = ax.plot([], [], label='generated data') frame_number = ax.text( 0.02, 0.95, '', horizontalalignment='left', verticalalignment='top', transform=ax.transAxes ) ax.legend() db, pd, _ = self.anim_frames[0] db_x = np.linspace(-self.gen.range, self.gen.range, len(db)) p_x = np.linspace(-self.gen.range, self.gen.range, len(pd)) def init(): line_db.set_data([], []) line_pd.set_data([], []) line_pg.set_data([], []) frame_number.set_text('') return (line_db, line_pd, line_pg, frame_number) def animate(i): frame_number.set_text( 'Frame: {}/{}'.format(i, len(self.anim_frames)) ) db, pd, pg = self.anim_frames[i] line_db.set_data(db_x, db) line_pd.set_data(p_x, pd) line_pg.set_data(p_x, pg) return (line_db, line_pd, line_pg, frame_number) anim = animation.FuncAnimation( f, animate, init_func=init, frames=len(self.anim_frames), blit=True ) anim.save(self.anim_path, fps=30, extra_args=['-vcodec', 'libx264'])def main(args): model = GAN( DataDistribution(), GeneratorDistribution(range=8), args.num_steps, args.batch_size, args.minibatch, args.log_every, args.anim ) model.train()def parse_args(): parser = argparse.ArgumentParser() parser.add_argument('--num-steps', type=int, default=1200, help='the number of training steps to take') parser.add_argument('--batch-size', type=int, default=12, help='the batch size') parser.add_argument('--minibatch', type=bool, default=False, help='use minibatch discrimination') parser.add_argument('--log-every', type=int, default=10, help='print loss after this many steps') parser.add_argument('--anim', type=str, default=None, help='name of the output animation file (default: none)') return parser.parse_args()if __name__ == '__main__': ''' data_sample = DataDistribution() d = data_sample.sample(10) print(d) ''' main(parse_args())参考资料:
An introduction to Generative Adversarial Networks (with code in TensorFlow
0 0
- 生成对抗网络介绍与原理分析
- 对抗样本与生成式对抗网络
- 对抗样本与生成式对抗网络
- 对抗样本与生成式对抗网络
- 对抗样本与生成式对抗网络
- [TensorFlow]生成对抗网络(GAN)介绍与实践
- 对抗生成网络原理和作用
- 生成对抗网络(GAN)的理论与应用完整入门介绍
- 生成对抗网络(GAN)的理论与应用完整入门介绍
- 生成对抗网络(GAN)的理论与应用完整入门介绍
- 生成对抗网络
- 生成对抗网络
- 生成对抗网络
- 生成对抗网络GAN
- 论文生成对抗网络
- 生成对抗网络推导
- GAN生成对抗网络
- 生成对抗网络简介
- 单片机控制继电器时碰到的问题
- 《PCL点云库学习&VS2010(X64)》Part 36 OpenTopography-激光雷达技术工具集
- nodepad++使用总结
- tensorflow之RNN
- 警告: Establishing SSL connection without server
- 生成对抗网络介绍与原理分析
- 基于loongson处理器ejtag工具使用记录(持续)
- HDOJ_P2032
- 9.矩形覆盖
- HDUOJ #2012 素数判定
- JavaScript中控制页面的跳转
- web安全色
- linux中文件的访问时间异常
- JSP数据交互(二)


