机器学习中的代价函数
来源:互联网 发布:河南教师网络研修社区 编辑:程序博客网 时间:2024/06/05 05:44
注:代价函数(有的地方也叫损失函数,Loss Function)在机器学习中的每一种算法中都很重要,因为训练模型的过程就是优化代价函数的过程,代价函数对每个参数的偏导数就是梯度下降中提到的梯度,防止过拟合时添加的正则化项也是加在代价函数后面的。在学习相关算法的过程中,对代价函数的理解也在不断的加深,在此做一个小结。
什么是代价函数?
假设有训练样本(x, y),模型为h,参数为θ。h(θ) = θTx(θT表示θ的转置)。
(1)概况来讲,任何能够衡量模型预测出来的值h(θ)与真实值y之间的差异的函数都可以叫做代价函数C(θ),如果有多个样本,则可以将所有代价函数的取值求均值,记做J(θ)。因此很容易就可以得出以下关于代价函数的性质:
- 对于每种算法来说,代价函数不是唯一的;
- 代价函数是参数θ的函数;
- 总的代价函数J(θ)可以用来评价模型的好坏,代价函数越小说明模型和参数越符合训练样本(x, y);
- J(θ)是一个标量;
(2)当我们确定了模型h,后面做的所有事情就是训练模型的参数θ。那么什么时候模型的训练才能结束呢?这时候也涉及到代价函数,由于代价函数是用来衡量模型好坏的,我们的目标当然是得到最好的模型(也就是最符合训练样本(x, y)的模型)。因此训练参数的过程就是不断改变θ,从而得到更小的J(θ)的过程。理想情况下,当我们取到代价函数J的最小值时,就得到了最优的参数θ,记为:
例如,J(θ) = 0,表示我们的模型完美的拟合了观察的数据,没有任何误差。
(3)在优化参数θ的过程中,最常用的方法是梯度下降,这里的梯度就是代价函数J(θ)对θ1, θ2, ..., θn的偏导数。由于需要求偏导,我们可以得到另一个关于代价函数的性质:
- 选择代价函数时,最好挑选对参数θ可微的函数(全微分存在,偏导数一定存在)
代价函数的常见形式
经过上面的描述,一个好的代价函数需要满足两个最基本的要求:能够评价模型的准确性,对参数θ可微。
(1)在线性回归中,最常用的是均方误差(Mean squared error),即

m:训练样本的个数;
hθ(x):用参数θ和x预测出来的y值;
y:原训练样本中的y值,也就是标准答案
上角标(i):第i个样本
(2)在逻辑回归中,最常用的是代价函数是交叉熵(Cross Entropy),交叉熵是一个常见的代价函数,在神经网络中也会用到。下面是《神经网络与深度学习》一书对交叉熵的解释:
交叉熵是对「出乎意料」(译者注:原文使用suprise)的度量。神经元的目标是去计算函数x→y=y(x)
在1948年,克劳德·艾尔伍德·香农将热力学的熵,引入到信息论,因此它又被称为香农熵(Shannon Entropy),它是香农信息量(Shannon Information Content, SIC)的期望。香农信息量用来度量不确定性的大小:一个事件的香农信息量等于0,表示该事件的发生不会给我们提供任何新的信息,例如确定性的事件,发生的概率是1,发生了也不会引起任何惊讶;当不可能事件发生时,香农信息量为无穷大,这表示给我们提供了无穷多的新信息,并且使我们无限的惊讶。更多解释可以看这里。

符号说明同上
(3)学习过神经网络后,发现逻辑回归其实是神经网络的一种特例(没有隐藏层的神经网络)。因此神经网络中的代价函数与逻辑回归中的代价函数非常相似:

代价函数与参数
代价函数衡量的是模型预测值h(θ) 与标准答案y之间的差异,所以总的代价函数J是h(θ)和y的函数,即,J=f(h(θ), y)。又因为y都是训练样本中给定的,h(θ)有θ决定,所以,最终还是模型参数θ的改变导致了J的改变。对于不同的θ,对应不同的预测值h(θ),也就对应着不同的代价函数J的取值。变化过程为:
通过下图可以查看随着θ1的变化,J(θ)的变化情况:
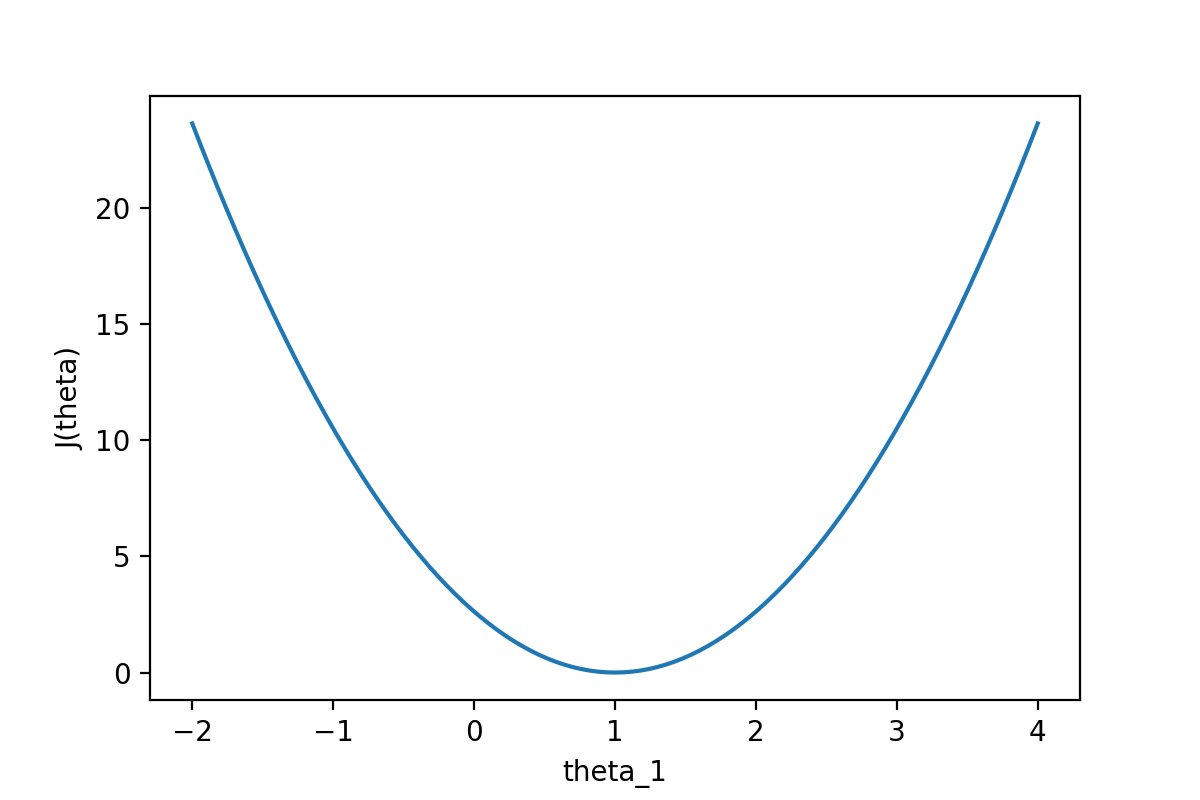
从图中可以很直观的看到θ对代价函数的影响,当θ1=1时,代价函数J(θ)取到最小值。因为线性回归模型的代价函数(均方误差)的性质非常好,因此也可以直接使用代数的方法,求J(θ)的一阶导数为0的点,就可以直接求出最优的θ值。
代价函数与梯度
梯度下降中的梯度指的是代价函数对各个参数的偏导数,偏导数的方向决定了在学习过程中参数下降的方向,学习率(通常用α表示)决定了每步变化的步长,有了导数和学习率就可以使用梯度下降算法(Gradient Descent Algorithm)更新参数了。下图中展示了只有两个参数的模型运用梯度下降算法的过程。

- 机器学习中的代价函数
- 机器学习中的代价函数
- 机器学习-代价函数
- 机器学习-代价函数
- 【机器学习】代价函数
- 机器学习-代价函数 I
- 机器学习-代价函数 II
- 机器学习-逻辑回归-代价函数
- 机器学习入门(4)--代价函数
- 第一周-机器学习-代价函数_intuition
- 机器学习:代价函数cost function
- 机器学习-3 cost function 代价函数
- 机器学习笔记之代价函数
- [机器学习2]模型与代价函数
- 机器学习入门——代价函数
- [机器学习] 代价函数(cost function)
- 机器学习之建模与代价函数
- 机器学习-逻辑回归-代价函数
- 我的页面
- jfinal jquery解决ajax 跨域访问--jsonp
- 两段简单的脚本....
- Micropython加速物联网开发2
- 使用netns虚拟网络进行网络测试
- 机器学习中的代价函数
- word中写出打对号的框
- [leetcode] 87. Scramble String
- android 用原生的人脸检测 检测图片
- RPC 和 Web Service 有什么区别?
- ES5与ES6继承的区别
- centos 没有netstat 命令问题
- IOS网络请求Get,Post请求差异及用法
- 分别用Shell和Python遍历查询Hdfs文件路径


