kafka (一)
来源:互联网 发布:晋城网络台少年心学院 编辑:程序博客网 时间:2024/06/04 01:34
Kafka产生于Mapreduce的子项目,是一种分布式流平台,在Kafka上,一个消息可以被认为是一个流或者是一个记录,消息通过 发布/订阅 的工作模式进行传递。Kafka是一种适用于高并发的高速实时消息系统,其实时性通过存储消息隐含的时间序列来保证。kafka的设计初衷是希望作为一个统一的信息收集平台,能够实时的收集反馈信息,并需要能够支撑较大的数据量,且具备良好的容错能力。
Kafka使用场景:
1、消息系统
kafka主要通过partitons/replication和容错保证消息的可靠传输。
2、追踪系统
其实时性通过topic和offset保证,使得一些在实际生产环境中需要基于做时间统计的场景非常适合使用kafka。
3、日志系统
application可以将操作日志"批量""异步"的发送到kafka集群中;同时kafka支持批量提交和消息压缩,在kafka生产/消费过程中体现出良好的性能。
Kafka架构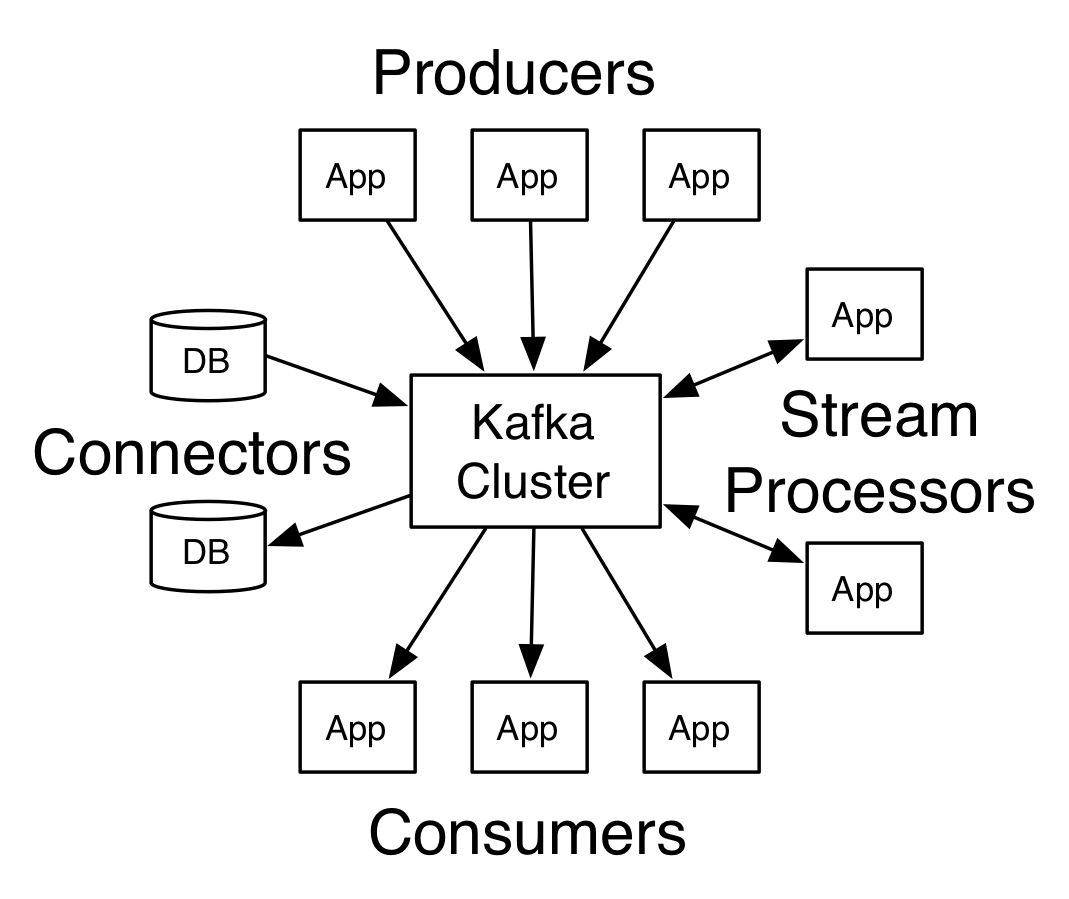 及工作原理:
及工作原理:
工作模式(整体角度):Kafka通过生产者消费者模式来生产消费消息,Produce通过业务逻辑产生消息后,由Kafka Connector提供连接服务,将消息通过Kafka Connector加入Kafka的消息队列(Topics)中;消费者调用Kafka Connector找到相应的Topic队列,将消息从Topic中取出来进行消费。(如右图)
工作模式(消息角度):对于消息来说,消息通过 发布/订阅 的工作模式进行传递。消息由生产者确定Topic进行发布,消费者需要订阅消息,每次所订阅的Topic内容增加后就会给相应的处于工作状态的消费者推送消息,消费者将消息从Topic队列取出进行消费。
Topic队列和Offset:Kafka集群中逻辑上存在多个Topic队列,任何发布到此partition的消息都会被直接追加到log文件的尾部。使用Topic来标记不同的逻辑队列,一般不同的逻辑队列的用途是不同的,在一个非变动的队列结构中,不同的消息共享一个Schema数据存储格式,所以在生产者和消费者过程中指定确定的Schema数据格式非常重要,这决定了我们的生产者和消费者如何存储和读取数据。每条消息在文件中的位置称为Offset(偏移量),Offset为一个long型数字,它是唯一标记一条消息。它唯一的标记一条消息。Kafka并没有提供其他额外的索引机制来存储offset,因为在Kafka中几乎不允许对消息进行“随机读写”。在一个Topic中存在唯一的Offset提供给不同的Comsumer进行操作,每个消息被正常消费过后Consumer会将Offset后移。Consumer有权将Offset重置,已解决消费失败的状态。Kafka本身不维护消息消费状态,这一般通过Zookeeper去维护。
消息持久性: Kakfa即使消息被消费,消息仍然不会被立即删除.日志文件将会根据broker中的配置要求,保留一定的时间之后删除;比如log文件保留2天,那么两天后,文件会被清除,无论其中的消息是否被消费.kafka通过这种简单的手段,来释放磁盘空间,以及减少消息消费之后对文件内容改动的磁盘IO开支,这也就是kafka和JMS(Java Message Service)实现(activeMQ)的不同。
磁盘IO以及网络IO:Kafka因为以文件的形式存储消息,所以在性能上严重依赖文件系统本身。Kafka在每次消息传递中不会直接将消息append到文件,而是通过内存buffer将消息积累,等达到一定阈值后再flush到磁盘,从而减少磁盘的IO操作。在网络IO方面,在文件传输时Kafka支持gzip等压缩方式将消息进行压缩后通过网络传输,从而减少网络传输时延。
先写到这里后续将补充Kafka逻辑和物理映射(Partition和Topic)、replication Set和Leader Selection、Avro和Schema等相关内容。
参考文献:
http://kafka.apache.org/intro
http://www.tuicool.com/articles/QJvu2e
http://www.cnblogs.com/likehua/p/3999538.html
- Kafka(一): Kafka 入门
- kafka笔记(一)
- kafka学习(一)
- kafka入门(一)
- Kafka入门(一)
- kafka安装(一)
- 初识Kafka(一)
- Kafka学习(一)
- kafka (一)
- 白话kafka(一)
- Kafka基础(一)
- Kafka (一) 概述
- Kafka原理(一)
- (一)Kafka中文教程-初识kafka
- kafka--Kafka剖析(一):Kafka背景及架构介绍
- Kafka 学习笔记(一)
- Kafka总结系列(一)
- Kafka学习笔记(一)
- 1026. 程序运行时间(15) PAT
- 《算法导论》第9章 中位数和顺序统计量 个人笔记
- wow.js中各种特效对应的类名
- android存储五个方法
- 防护比特币病毒,关闭相应端口步骤
- kafka (一)
- Oracle笔记(七) 数据更新、事务处理、数据伪列
- Java多线程系列--“JUC集合”06之 ConcurrentSkipListSet
- 阻止按空格键页面下拉
- 双城记 A Tale of Two Cities
- js实现限时抢倒计时
- Java多线程系列--“JUC集合”07之 ArrayBlockingQueue
- Oracle笔记(八) 复杂查询及总结
- PNG文件结构分析 ---Png解析


