41万亿元规模的消金行业,重构势在必行,AI算法会是突破口?
来源:互联网 发布:淘宝查询别人购买记录 编辑:程序博客网 时间:2024/06/10 22:38
( 本文由 CreditX氪信 授权 虎嗅网 发表,作者 唐正阳。)
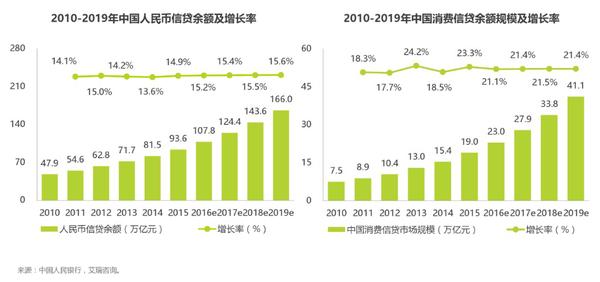
据BCG公布的数据显示,目前有1000多家金融科技创新企业获得超100亿美金的风投资金。与此同时,普惠金融持续爆发式增长,2015年中国消费信贷规模达到19万亿元,同比增长23.3%,预计2019年将达到41.1万亿元。
面对如此巨大的风口,整个消费金融业态正在技术、资本和市场的共同作用下发生数字化重构,不论是生活中我们每个人触手可及的借贷、支付、理财等金融服务,还是行业内BAT等互联网巨头布局金融的积极行动,都在昭示:我们正在迎来金融3.0时代,金融业务的变革势在必行。
金融3.0时代
颠覆背后,对比互联网金融与传统金融的差异,我们逐渐从以往依赖人工放贷或发信用卡等到现在实时的金融服务,不难发现本质是从人工数据收集处理方式到整个数据能力自动化的转变。这种转变不同于人工1.0时代到线上2.0时代的简单切换,偏向于在大数据上用规则或评分卡体系简单刻画数据与业务目标关系这样一种线上化的过程。
我们讲数据能力,核心在于将金融专家的深厚经验赋能机器,真正地让机器刻画纷繁数据与目标的复杂关系实现全自动化3.0时代,这对人工智能产生了真正的巨大需求。因此,如何搭建一整套从数据到人工智能算法到平台的数据架构体系,将直接决定未来商业竞争制高点,这也是所有金融业务变革的基础。

说易行难,现下关于神化或忧虑人工智能的观点都比较多,我们讲技术创新怎么才能定义为成功?一定是结合业务能产生核心价值的。过去谷歌、微软、亚马逊等巨头将人工智能用在搜索、推荐、广告上做了十几年的结合终获得巨大提升。
在金融场景上,人工智能真正能在业务上产生核心价值也必然面临一系列磨合的问题,把金融体系的深厚经验与机器刻画复杂数据关系的能力结合,实现金融业务的价值最大化,需要大量艰难的尝试。下面从工业实践的角度,简要分析当下人工智能重构金融数据架构体系的3个方面,以及为什么必须要用这些人工智能技术?
为什么必须要用全域知识图谱
首先谈底层数据架构体系的知识图谱,其本质是语义网络,一种基于图的数据结构,由节点(point)和边(edge)组成。 在金融知识图谱里,其实我们每一个申请人、手机号、设备、地址、IP等都是节点,而诸如申请人拥有设备、手机号呼叫手机号等有向联系就是图中的边,边的权重为关联的紧密程度。
通俗地讲,全域金融知识图谱就是把所有不同种类的信息连接在一起而得到的关系网络,为金融机构提供了从“关系”的角度去分析问题的能力。
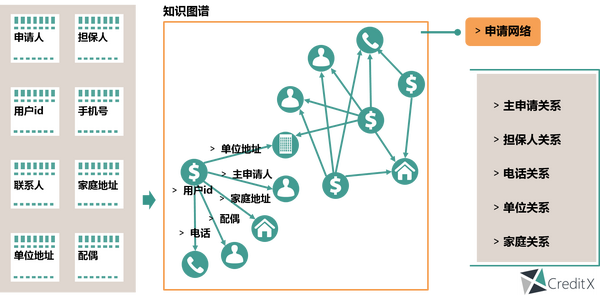
可为什么说我们需要知识图谱?金融的核心在于风险,而风险控制的关键就是基于纷繁复杂的各种数据,通过数据金融化和数据价值挖掘,合理建模从而进行风险程度评估。这涉及几个点:
一是数据的表现能力,以往我们只能局限于一度关系分析,而图谱对实体间关系的强扩展能力可有效帮助我们处理局部或全网数据间的关系;
二是数据的管理能力,随着金融机构不同渠道和系统数据越来越多,整个底层数据体系的管理将愈发复杂,通过定义主流的业界规范来对数据进行转换和清洗,可将异质异构的数据统一管理;
三是扩展能力,我们知道大机构接入的数据越来越多,与以往大量数据表间的合并不同,知识图谱可按之前所述对新数据转换从而无限扩展整合。
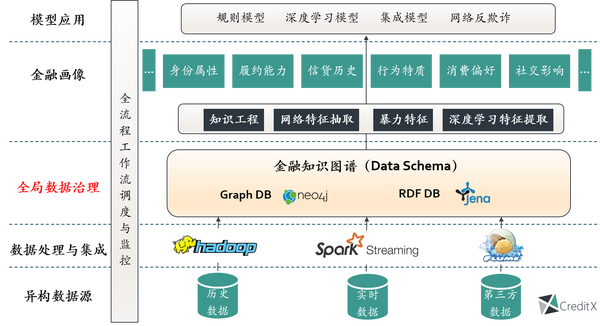
有了知识图谱,事实上就可以实现针对金融风险的精准用户画像构建,我们既可以抽取丰富的局部关系特征和网络全局特征,同时也可以运用先进的无监督聚类算法辟如社区挖掘来识别风险团体,在此之上运用有监督算法的集成机器学习模型,相对传统规则模型,金融机构自身的群体反欺诈能力往往会有一个巨大的提升。如下图,从解决当下互金曝光较多的黑产、团贷等问题角度看,也是必须用知识图谱的一个理由。
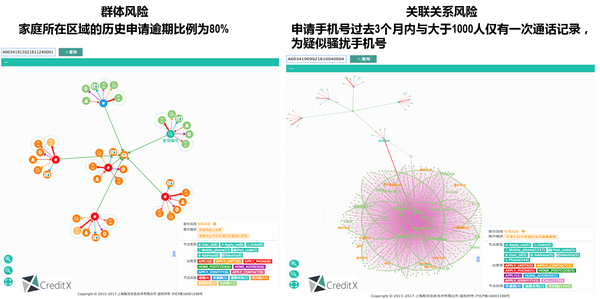
为什么必须要用深度学习
目前深度学习的应用异常火热,尤其在图像识别领域,微软等巨头的机器错误率已低于人类,深度学习在模型层面和特征层面都有应用。但为什么说金融场景必须要用深度学习?
从整个金融底层数据结构来看,主要是结构化和非结构化两类。尤其是后者,据IDC的数据显示,未来金融行业的非结构化数据占比将达到80%。讲到底,谁能把非结构化数据用起来,谁就能跑赢数据能力竞争的关键一段。
传统的数据分析方式辟如在文本上,金融专家们可根据丰富的经验,计算相应的统计指标、或者写正则表达式等人工方式提取特征。但不可置否的是,随着线上风险的迅速演化,在非结构化数据上人工定义天生难以穷尽风险,比如无法捕捉新的黑产术语。
而深度学习是最适合处理图像、文本、时序等非结构化数据的手段,尤其在特征加工方面,如下图,通过将诸如文本、时序等数据转化为向量,用深度学习提取向量空间中的关系可自动生成抽象的特征表征,进一步我们就能计算语义相似性,并运用分类器网络实现非结构化数据与金融风险的深度挂钩。
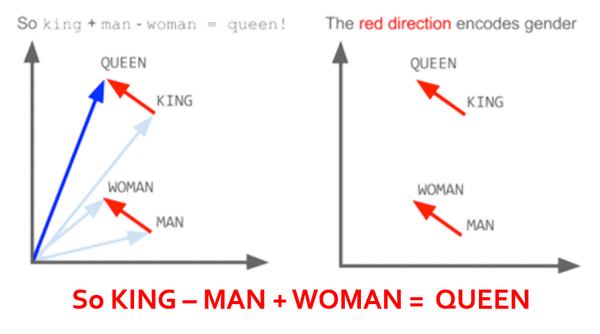
当然,“深度学习”价值还是在于对金融专家经验体系的补充,在处理人工难以固化为特定风险知识或规则的基础上予以最大弥补,这不意味深度学习可以替代金融专家,长远来看,现在不能,以后也不能。
为什么必须要用复杂集成模型
谈到现在,金融场景可用的数据其实远远比我们传统认为的强征信数据要丰富的多,既有非结构化的文本、时序等特征,也有基于知识图谱的网络风险特征,此外在大型场景中的实践我们也都认识到移动互联网行为、社交、地理位置等几乎所有数据其实都可以是风险数据,且价值超出想象。
这带来一个问题,就是变量维度非常多,少则几千,多则上万,且非常稀疏、低饱和。怎么用好这些真正的大数据?已经远远超出了过去评分卡体系的能力范围。
这也是为什么必须要用复杂集成模型的初衷,集成模型从“voting”的思想去简单理解,就是针对不同类型的数据我们选用最合适的子模型来处理,然后每个子模型投票做出决策。相对单一模型有限的预测能力,“好而不同”的模型集成效果明显会卓越很多,此外无论从稳定度、容错、还是抗扰动能力来讲,集成模型也都在效果和稳定之间取得了极好的平衡。
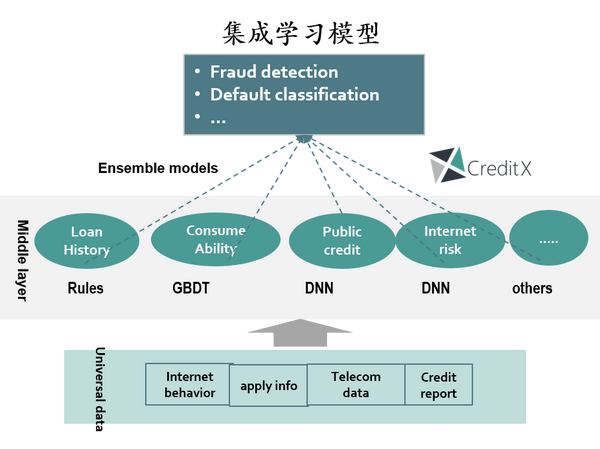
这里简单提及一下模型框架体系,我们知道消费金融有现金贷、消费分期等诸多场景,集成模型这套框架体系的每一个单独领域子模型都可以快速迁移应用到新业务领域上,对机构在战略层面实现场景间的切换和业务冷启动阶段都可以发挥极其重要的作用。
金融数据架构体系的未来
当下,“数字驱动业务”已深入人心,整个金融业态的重构也是摆在金融机构和科技公司面前的机遇和挑战。可以说,现在的确到了必须依靠机器来解决业务问题的阶段。金融的人工智能并不万能,但在国人绝大多数无法得到合理金融服务的环境和需求下,确实能够引领普惠金融发展,产生巨大的核心价值。
毫无疑问,基于人工智能的金融数据架构平台正在重新定义业务形态和与客户交互的方式。未来,我们的金融生活终究会变成怎样?我们拭目以待。
- 41万亿元规模的消金行业,重构势在必行,AI算法会是突破口?
- 突破口,横冲直撞也许是最好的
- 余额宝资产规模破万亿元,用户数量超3亿
- 明年大数据行业的趋势会是哪些?
- “明年AI会如何?”英伟达问了13位不同行业的专家
- 进入AI行业的基础
- 2015互联网+农业(B2B)报告:10万亿规模的市场,还有大把的机会
- MWC 2012趋势看点之M2M:万亿美元规模的生意谁来支撑
- 2万亿庞大规模,市场刮起金融科技风潮,我们也能做的风口
- 五子棋AI算法第八篇-重构代码
- 谁来切分1.8万亿元的社区服务蛋糕?
- 吴恩达新演讲:AI正改变行业格局,公司的壁垒非算法而是数据
- 中国钢铁行业两个“突破口”助力转型升级
- 2017 Q3 AI行业热度观察:全球AI公司融资金额突破77亿元
- 这是容易把规模的概念
- 北大 AI 公开课第1讲:雷鸣评人工智能前沿与行业结合点(41PPT) 及 徐小平对话雷鸣——AI 创业仅有科学家是万万不行的
- 快消行业指的是哪些?
- AI在医疗行业的最新进展
- spring与mybatis整合配置文件详解
- Java高新技术第一篇:类加载器详解
- 各厂商接入交换机通过ACL限制端口应用的配置信息
- 一个UILabel不同部分显示不同颜色
- 【Java深入】ArrayList源码剖析(一)
- 41万亿元规模的消金行业,重构势在必行,AI算法会是突破口?
- 关于移动端input框 在手机页面中无法输入文字的问题
- [Leetcode]2. Add Two Numbers
- leetcode 508. Most Frequent Subtree Sum
- Java.NET.BindException java.net.ConnectException java.net.SocketException异常
- IP协议相关技术简介
- 关于select标签的操作
- 22. Generate Parentheses
- (1)高通AP10.4开发者指南——WLAN(1.1 Wireless LAN简介)


