Harbor 源码分析之仓库同步(五)
来源:互联网 发布:吉首大学网络服务中心 编辑:程序博客网 时间:2024/05/21 19:28
Harbor支持分布式的部署,镜像仓库成树状结构。镜像仓库有父子结构,通过定制策略可以实现父子仓库之前的同步,这样可以在多个数据中心之前完成镜像同步,因为每个数据中心内容器的启动肯定是从本数据中心内的镜像仓库去拉取镜像。 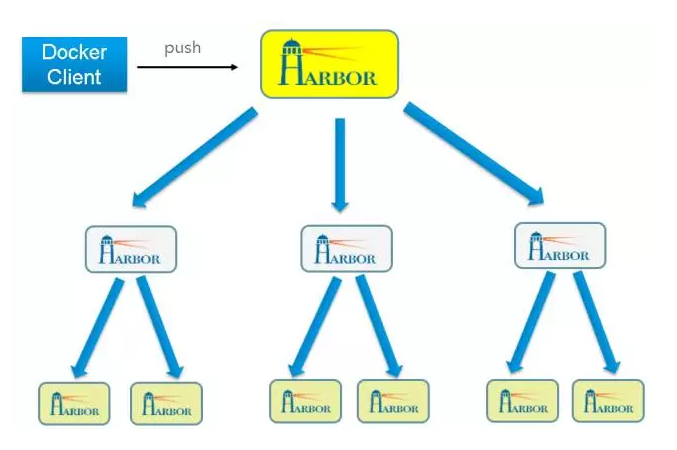
由于它是一个多租户的设计,可以设置同步的policy,这样控制哪些镜像去同步。是通过页面创建policy完成的src/ui/api/replication_policy.go。
func (pa *RepPolicyAPI) Post() { policy := &models.RepPolicy{} pa.DecodeJSONReqAndValidate(policy) /* po, err := dao.GetRepPolicyByName(policy.Name) if err != nil { log.Errorf("failed to get policy %s: %v", policy.Name, err) pa.CustomAbort(http.StatusInternalServerError, http.StatusText(http.StatusInternalServerError)) } if po != nil { pa.CustomAbort(http.StatusConflict, "name is already used") } */ project, err := dao.GetProjectByID(policy.ProjectID) if err != nil { log.Errorf("failed to get project %d: %v", policy.ProjectID, err) pa.CustomAbort(http.StatusInternalServerError, http.StatusText(http.StatusInternalServerError)) } if project == nil { pa.CustomAbort(http.StatusBadRequest, fmt.Sprintf("project %d does not exist", policy.ProjectID)) } target, err := dao.GetRepTarget(policy.TargetID) if err != nil { log.Errorf("failed to get target %d: %v", policy.TargetID, err) pa.CustomAbort(http.StatusInternalServerError, http.StatusText(http.StatusInternalServerError)) } if target == nil { pa.CustomAbort(http.StatusBadRequest, fmt.Sprintf("target %d does not exist", policy.TargetID)) } policies, err := dao.GetRepPolicyByProjectAndTarget(policy.ProjectID, policy.TargetID) if err != nil { log.Errorf("failed to get policy [project ID: %d,targetID: %d]: %v", policy.ProjectID, policy.TargetID, err) pa.CustomAbort(http.StatusInternalServerError, http.StatusText(http.StatusInternalServerError)) } if len(policies) > 0 { pa.CustomAbort(http.StatusConflict, "policy already exists with the same project and target") } pid, err := dao.AddRepPolicy(*policy) if err != nil { log.Errorf("Failed to add policy to DB, error: %v", err) pa.RenderError(http.StatusInternalServerError, "Internal Error") return } if policy.Enabled == 1 { go func() { if err := TriggerReplication(pid, "", nil, models.RepOpTransfer); err != nil { log.Errorf("failed to trigger replication of %d: %v", pid, err) } else { log.Infof("replication of %d triggered", pid) } }() } pa.Redirect(http.StatusCreated, strconv.FormatInt(pid, 10))}他是基于项目的同步,所以先判断是否具有相同项目和目标仓库的policy,如果有就是报policy already exists的错误,如果没有就新建一个policy并且触发policy,触发policy就是
func TriggerReplication(policyID int64, repository string, tags []string, operation string) error { data := struct { PolicyID int64 `json:"policy_id"` Repo string `json:"repository"` Operation string `json:"operation"` TagList []string `json:"tags"` }{ PolicyID: policyID, Repo: repository, TagList: tags, Operation: operation, } b, err := json.Marshal(&data) if err != nil { return err } url := buildReplicationURL() req, err := http.NewRequest("POST", url, bytes.NewBuffer(b)) if err != nil { return err } addAuthentication(req) client := &http.Client{} resp, err := client.Do(req) if err != nil { return err } defer resp.Body.Close() if resp.StatusCode == http.StatusOK { return nil } b, err = ioutil.ReadAll(resp.Body) if err != nil { return err } return fmt.Errorf("%d %s", resp.StatusCode, string(b))}通过调用harbor-jobservice的接口(/api/jobs/replication)创建job。代码在src/jobservice/api/replication.go里面
func (rj *ReplicationJob) Post() { var data ReplicationReq rj.DecodeJSONReq(&data) log.Debugf("data: %+v", data) p, err := dao.GetRepPolicy(data.PolicyID) if err != nil { log.Errorf("Failed to get policy, error: %v", err) rj.RenderError(http.StatusInternalServerError, fmt.Sprintf("Failed to get policy, id: %d", data.PolicyID)) return } if p == nil { log.Errorf("Policy not found, id: %d", data.PolicyID) rj.RenderError(http.StatusNotFound, fmt.Sprintf("Policy not found, id: %d", data.PolicyID)) return } if len(data.Repo) == 0 { // sync all repositories repoList, err := getRepoList(p.ProjectID) if err != nil { log.Errorf("Failed to get repository list, project id: %d, error: %v", p.ProjectID, err) rj.RenderError(http.StatusInternalServerError, err.Error()) return } log.Debugf("repo list: %v", repoList) for _, repo := range repoList { err := rj.addJob(repo, data.PolicyID, models.RepOpTransfer) if err != nil { log.Errorf("Failed to insert job record, error: %v", err) rj.RenderError(http.StatusInternalServerError, err.Error()) return } } } else { // sync a single repository var op string if len(data.Operation) > 0 { op = data.Operation } else { op = models.RepOpTransfer } err := rj.addJob(data.Repo, data.PolicyID, op, data.TagList...) if err != nil { log.Errorf("Failed to insert job record, error: %v", err) rj.RenderError(http.StatusInternalServerError, err.Error()) return } }}通过addJob创建job。这个方法首先肯定是入库,保存job然后后调度运行,此时job的操作是models.RepOpTransfer,它代表job传输本地仓库到远程仓库,就是镜像复制。
func (rj *ReplicationJob) addJob(repo string, policyID int64, operation string, tags ...string) error { j := models.RepJob{ Repository: repo, PolicyID: policyID, Operation: operation, TagList: tags, } log.Debugf("Creating job for repo: %s, policy: %d", repo, policyID) id, err := dao.AddRepJob(j) if err != nil { return err } log.Debugf("Send job to scheduler, job id: %d", id) job.Schedule(id) return nil}然后就通过Schedule开始调度运行容器了。
func Schedule(jobID int64) { jobQueue <- jobID}其实就是把job加入到jobQueue任务队列中。有人放就有人取,那么谁来取呢?
就是说工作池src/jobservice/job/workerpool.go,
func Dispatch() { for { select { case job := <-jobQueue: go func(jobID int64) { log.Debugf("Trying to dispatch job: %d", jobID) worker := <-WorkerPool.workerChan worker.RepJobs <- jobID }(job) } }}这个work是个什么呢?
type Worker struct { ID int RepJobs chan int64 SM *SM quit chan bool}它其实是一个RepJobs的管道,复制接受jobid,更重要是SM,它是一个状态机,是下面要讲的重点。接着上面说,当接受到一个job后处理
func (w *Worker) handleRepJob(id int64) { err := w.SM.Reset(id) if err != nil { log.Errorf("Worker %d, failed to re-initialize statemachine for job: %d, error: %v", w.ID, id, err) err2 := dao.UpdateRepJobStatus(id, models.JobError) if err2 != nil { log.Errorf("Failed to update job status to ERROR, job: %d, error:%v", id, err2) } return } if w.SM.Parms.Enabled == 0 { log.Debugf("The policy of job:%d is disabled, will cancel the job", id) _ = dao.UpdateRepJobStatus(id, models.JobCanceled) w.SM.Logger.Info("The job has been canceled") } else { w.SM.Start(models.JobRunning) }}先是重置状态Reset,然后启动Start,将把job设置成JobRunning,此时会出触发镜像推送。就是把本地的pull下来在push到远程。具体pull分两部分Manifest和blob如下,manifes是元数据,blob是分层:
func (b *BlobTransfer) enter() (string, error) { name := b.repository tag := b.tags[0] for _, blob := range b.blobs { b.logger.Infof("transferring blob %s of %s:%s to %s ...", blob, name, tag, b.dstURL) size, data, err := b.srcClient.PullBlob(blob) if err != nil { b.logger.Errorf("an error occurred while pulling blob %s of %s:%s from %s: %v", blob, name, tag, b.srcURL, err) return "", err } if data != nil { defer data.Close() } if err = b.dstClient.PushBlob(blob, size, data); err != nil { b.logger.Errorf("an error occurred while pushing blob %s of %s:%s to %s : %v", blob, name, tag, b.dstURL, err) return "", err } b.logger.Infof("blob %s of %s:%s transferred to %s completed", blob, name, tag, b.dstURL) } return StatePushManifest, nil}上面是blob同步过程:先pull然后push,梳理成章。
- Harbor 源码分析之仓库同步(五)
- Harbor 源码分析之状态机(五)
- Harbor 源码分析之API(四)
- Harbor 源码分析之组件分析(二)
- Harbor 源码分析之安装部署(一)
- Harbor 源码分析之registry v2认证(三)
- Harbor 源码分析之安装部署(一)
- Docker私有仓库管理之Harbor搭建
- elasticsearch源码分析之Transport(五)
- elasticsearch源码分析之Transport(五)
- kubenetes源码分析之DNS(五)
- Docker镜像仓库Harbor之搭建及配置
- Kubernetes使用Harbor仓库
- 搭建docker仓库harbor
- leveldb源码分析之五
- docker基础:私有仓库repository搭建(2):Harbor
- Harbor -- 搭建Docker私有仓库
- Maven之(五)Maven仓库
- 使用Kotlin编写Android项目示例
- Git用法之撤销操作
- ImagView宽度固定,高度根据控件宽度与图片宽度比例进行自适应
- ArrayList和数组间的相互转换
- MYSQL数据库设计规范与原则
- Harbor 源码分析之仓库同步(五)
- pagehelper mybatis的分页插件
- 令人振奋的Class(上)
- 玩转 Windows 10 中的 Linux 子系统
- 数据结构——最小生成树
- 界面适配华为手机的虚拟按键的解决方案
- Oracle并行操作——从串行到并行
- 令人振奋的Class(下):继承和实战代码示例
- 关于Mongodb的操作


