Google I/O 2017上推出的新 GC 算法的原理
来源:互联网 发布:js发送url请求 编辑:程序博客网 时间:2024/05/18 00:58
看了下youtube上的视频 https://www.youtube.com/watch?v=iFE2Utbv1Oo
貌似之前的Compact Copying Collector并不是concurrent的,然后在Android O里调整成为了Concurrent Copying Garbage Collector. 新的GC简单来说就是利用了read barrier来使得应用程序代码可以在GC过程中耗时最大的那些阶段依旧同GC一起运行。图是从Presentation里粘出来的,侵权删。
新的GC分为Pause, Copying, Reclaim三个阶段,以Region为单位进行GC。
Pause阶段:
<img data-rawwidth="1112" data-rawheight="556" src="https://pic4.zhimg.com/v2-c5f39f0ca3f2a0d213218f971e87981b_b.png" class="origin_image zh-lightbox-thumb" width="1112" data-original="https://pic4.zhimg.com/v2-c5f39f0ca3f2a0d213218f971e87981b_r.png">
这个阶段耗时非常少,这里很重要的一块儿工作是确定需要进行GC的region。当前进程中所有正被使用的那些region中存在高度碎片的region会被选中,而这些被选中的region被称为source region。在GC完成后这些被选中的source region就可以被释放了。从图中可以看出本次GC选中了中间的两个碎片比率很大的region作为source region。在Pause阶段完成对所有线程stack的walk并得到最终的root set之后,就可以唤醒所有的线程并进入到GC的下一个Copying阶段。
Copying阶段:
<img data-rawwidth="1110" data-rawheight="570" src="https://pic2.zhimg.com/v2-e190108ce592c25dc3a062907c5728ad_b.png" class="origin_image zh-lightbox-thumb" width="1110" data-original="https://pic2.zhimg.com/v2-e190108ce592c25dc3a062907c5728ad_r.png">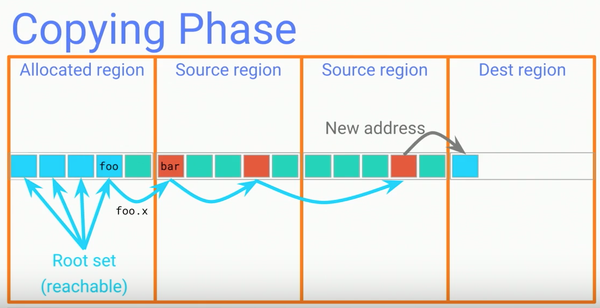
Copying阶段是整个GC中耗时最长的阶段。通过将source region中根据root set计算并标记为reachable的对象拷贝到destination region,并且确保在GC完成后没有任何指向source region中内存的引用,然后修改所有指向source region的活对象使他们指向新的destination region中的新地址。由于现在应用程序线程正在同GC线程一同运行,GC需要确保其它线程不会读到依旧指向source region的对象,而新的GC则使用了read barrier技术来达到这个目的。
<img data-rawwidth="1114" data-rawheight="564" src="https://pic3.zhimg.com/v2-742b6a5d48138f5661f838ff7603b97a_b.png" class="origin_image zh-lightbox-thumb" width="1114" data-original="https://pic3.zhimg.com/v2-742b6a5d48138f5661f838ff7603b97a_r.png">
所谓read barrier是一小段代码,并且被运行期环境(runtime)安插在field read前来防止其它线程看到指向source region的引用。如果其它线程在Copying阶段需要访问曾经存在于source region中的对象,GC的read barrier逻辑会负责截获这个读取并且将数据拷贝到destination region然后返回这个被拷贝到destination region的新引用。当所有的source region的所有reachable对象都被转移到destination region之后就可以进入到GC的下一个Reclaim阶段了
<img data-rawwidth="1102" data-rawheight="554" src="https://pic4.zhimg.com/v2-1bf2f9700cc0cea9c201d646ca9a1ee3_b.png" class="origin_image zh-lightbox-thumb" width="1102" data-original="https://pic4.zhimg.com/v2-1bf2f9700cc0cea9c201d646ca9a1ee3_r.png">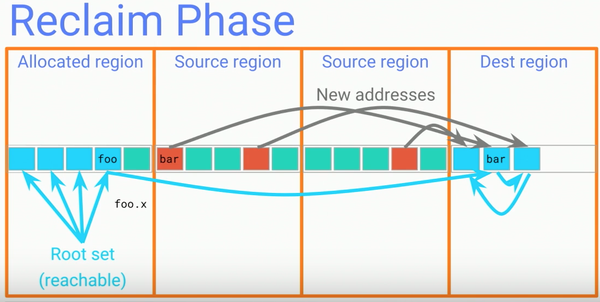
Reclaim阶段:在经过Copying阶段后,整个进程中就不再存在指向source regions的引用了,GC就可以将这些source region的内存释放供以后使用了。
新的GC算法在提高了GC效率的同时还得益于对后台任务甚至系统后台任务的支持,整个heap的平均尺寸得到了32%的下降。
<img data-rawwidth="992" data-rawheight="552" src="https://pic3.zhimg.com/v2-033fd4784aae7313d6e3fbc428b2f17e_b.png" class="origin_image zh-lightbox-thumb" width="992" data-original="https://pic3.zhimg.com/v2-033fd4784aae7313d6e3fbc428b2f17e_r.png">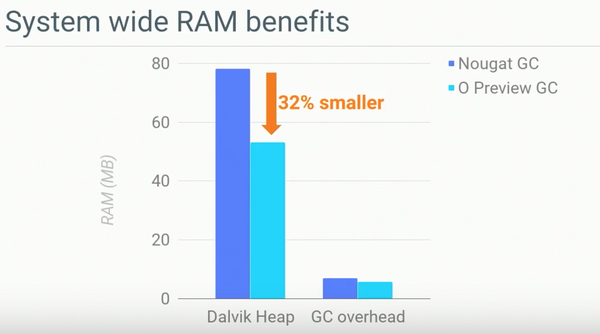
而平均GC Latency也得到了大大的降低,具体对比见图
<img data-rawwidth="1102" data-rawheight="562" src="https://pic3.zhimg.com/v2-e8d728ed6bc65a240033cf3b4c2fdd0a_b.png" class="origin_image zh-lightbox-thumb" width="1102" data-original="https://pic3.zhimg.com/v2-e8d728ed6bc65a240033cf3b4c2fdd0a_r.png">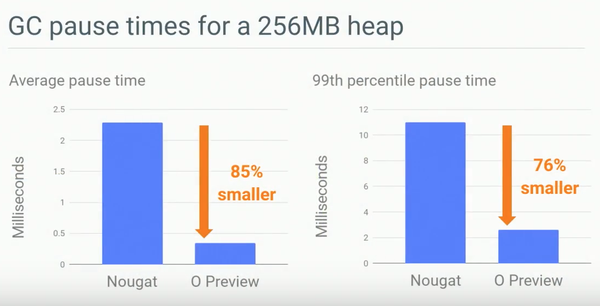
另外由于heap总是经过compact的,从而可以实现Thread Local Bump Pointer的简单内存分配器,因为现在分配内存不再需要复杂的free list管理只需要一个简单的pointer bump,内存分配的速度也得到了显著的提升。
<img data-rawwidth="1116" data-rawheight="544" src="https://pic3.zhimg.com/v2-d1501d9d10c4789cbc05c6cfbcba6ef6_b.png" class="origin_image zh-lightbox-thumb" width="1116" data-original="https://pic3.zhimg.com/v2-d1501d9d10c4789cbc05c6cfbcba6ef6_r.png">
- Google I/O 2017上推出的新 GC 算法的原理
- Google I/O ‘17 推出的物理动画库PhysicsBasedAnimation
- Google I\/O 2017上的Firebase新功能速递
- Google I/O 2017 Android O 新特性
- 明晚的Google I/O,这6大看点值得期待 | Google I/O 2017
- Google公布I\/O 2017 for Android的源代码
- Google I/O 2017
- 对于明天的Google I/O大会,企业用户可能比你更关注 | Google I/O 2017
- Google I/O 2016 RecyclerView的前世今生,原理详解等
- J2SE1.4的I/O新特性
- J2SE1.4的I/O新特性
- Google推出Developers Live为I/O开发者大会预热
- 2014谷歌I/O上的Google Cloud Platform和Cloud Dataflow
- Google I/O 2016 上发布的 ConstraintLayout是什么东东?Android Layout新世界
- 【Android 基础】Google新推出的Android布局控件FlexboxLayout
- Google的AI并不完美,却是AI的正确打开方式 | Google I/O 2017
- I/O接口的输入输出编程原理
- Linux 异步通知I/O的原理
- (51)组件之音频组件
- android property aniamtion(属性动画)详解
- wxPython之GraphicsContext
- MyBatis insert操作返回主键
- 蓝桥杯决赛之积分之迷
- Google I/O 2017上推出的新 GC 算法的原理
- 前台遍历数组,后台foreach循环添加
- oracle创建序列以及时间戳的使用
- firewalld 造成 mesos slave不断disconnect
- 分布式锁的几种实现形式
- C++中Static作用和使用方法
- 字符串表达式的计算
- libmad的移植、交叉编译、安装——基于ubuntu16
- (个人)AR电子书系统创新实训第二周(2)


