实时的YcoCg-DXT压缩
来源:互联网 发布:mac恢复出厂设置 编辑:程序博客网 时间:2024/05/16 11:19
实时YCoCg-DXT压缩
JMP van Waveren
id Software,Inc.
NVIDIA公司
2007年9月14日
©2007,id Software,Inc.
抽象
(译者注,在Doom3bfg代码中具有Dxt压缩算法,对于rage,我觉得应该也是应用了Dxt压缩算法,来进行对于纹理图像的解压缩运算)
原文下载地址
介绍
纹理是绘制到几何形状上的数字化图像,以增加视觉细节。在今天的计算机图形学中,在光栅化过程中将大量的细节映射到几何图形上。不仅使用颜色的纹理,还可以指定表面属性(例如镜面反射)或精细表面细节(以正常或凹凸贴图的形式)的纹理。所有这些纹理都可以消耗大量的系统和视频内存。幸运的是,可以使用压缩来减少存储纹理所需的内存量。今天的大多数显卡允许纹理以各种在光栅化期间实时解压缩的压缩格式存储。一种这样的格式,它是由大多数图形卡支持的,是S3TC -也被称为DXT压缩[ 1,2 ]。
压缩纹理不仅需要显卡更少的内存,而且由于带宽要求降低,通常渲染速度比未压缩纹理要快。由于压缩,某些质量可能会丢失。然而,减少的内存占用允许使用更高分辨率的纹理,使得在质量上实际上可以获得显着的增益。
DXT1
在DXT1格式[ 1,2 ]在图形卡上的硬件渲染过程中设计用于实时解压缩。DXT1是具有8:1固定压缩比的有损压缩格式。DXT1压缩是块截断编码(BTC)[ 3 ]的一种形式,其中图像被划分为非重叠块,并且每个块中的像素被量化为有限数量的值。4×4像素块中的像素的颜色值通过RGB颜色空间在一行上的等距点近似。该行由两个端点定义,对于4x4块中的每个像素,2位索引存储在该行上的一个等距点上。通过颜色空间的线的端点被量化为16位5:6:5 RGB格式,通过插值生成一个或两个中间点。DXT1格式允许通过根据终点的顺序切换到不同的模式,其中仅生成一个中间点并指定一个附加颜色,这是黑色和完全透明的。
下图显示柯达无损真彩色图像套件[ 16 ] 的图像14的一小部分。左边的图像是原来的。中间的图像显示了图像14的相同部分,其首先被缩小到四分之一的尺寸,然后用双线性滤波放大到原始尺寸。右图显示了压缩成DXT1格式的相同部分。


 切出
切出柯达图像套件图像14 的部分。
1.5 MB将图像缩小
到四分之一的大小。
384 kB
以最好的质量压缩到DXT1 。
192 kB
DXT1压缩图像具有比首先缩小到四分之一尺寸的图像更多的细节,然后用双线性滤波放大到原始尺寸。此外,DXT1压缩的图像使用图像的一半存储空间缩小到四分之一的大小。然而,与原始图像相比,DXT1压缩图像的质量明显下降。
3. CPU上的实时DXT1
DXT1格式设计用于硬件实时解压缩,而不是实时压缩。虽然解压缩非常简单,但对DXT1格式的压缩通常需要大量的工作。
有几种好的DXT压缩机可用。最显着的是ATI Compressonator [ 4 ]和NVIDIA DDS Utilities [ 5 ]。两台压缩机都生产高品质的DXT压缩图像。然而,这些压缩机不是开源的,并且它们被优化用于高质量的离线压缩,并且对于实时使用来说太慢。NVIDIA还发布了一套开源的纹理工具[ 6 ],其中包括DXT压缩器。这些DXT压缩机也以超速的质量为目标。有一个开源的DXT压缩器可供Roland Scheidegger用于Mesa 3D图形库[ 7 ]。另一个好的DXT压缩器是西蒙·布朗的Squish [ 8 ]。
直到最近,对DXT1格式的实时压缩并不被认为是一个可行的选择。然而,DXT1的实时压缩是非常有可能的,如[ 9 ] 所示,与最佳DXT1压缩相比,质量损失对于大多数图像是合理的。4×4像素块中的RGB颜色倾向于很好地映射到RGB颜色空间的边界区域的线上的等距点,因为该线跨越完整的动态范围,并且倾向于与亮度分布。
下面的图像再次显示柯达无损真彩色图像套件的图像14的小部分[ 16 ]。图14的该特定部分示出了由于DXT压缩而可能发生的一些最差的压缩伪像。左边的图像是原来的。中间的图像显示了以最佳质量压缩到DXT1的相同部分。右图显示了实时DXT1压缩机的结果。
 切出
切出柯达图像套件图像14 的部分。
1.5 MB
以最好的质量压缩到DXT1 。
192 kB压缩到DXT1与
实时DXT1压缩机。
192 kB
使用实时DXT1压缩器时会出现明显的工件,但对DXT1格式的最佳压缩也显示出明显的质量损失。然而,对于许多图像,由于实时压缩造成的质量损失是不明显的或完全可以接受的。
4. YCoCg-DXT5
所述DXT5格式[ 2,3 ]存储三个颜色通道中的相同的方式DXT1确实,但没有1位alpha通道。代替1位alpha通道,DXT5格式存储与DXT1色彩通道相似的单独的Alpha通道。4x4块中的alpha值通过α空间在一行上的等距点近似。通过α空间的线的端点存储为8位值,并且基于端点的顺序,通过插值生成4或6个中间点。对于4个中间点的情况,生成两个附加点,一个完全不透明,另一个用于完全透明。对于4x4块中的每个像素,3位索引通过alpha空间存储在该行上的一个等距点上,或完全不透明或完全透明的两个附加点之一。使用相同数量的位来将alpha通道编码为三个DXT1颜色通道。因此,与三维颜色空间相反,α通道以比每个颜色通道更高的精度被存储,因为α空间是一维的。此外,总共有8个样本表示4×4块中的α值,而不是4个样本来表示颜色值。由于额外的Alpha通道,DXT5格式消耗DXT1格式的内存量的两倍。与每个颜色通道相比,alpha通道的存储精度高于每个颜色通道,因为与三维色彩空间相反,alpha空间是一维的。此外,总共有8个样本表示4×4块中的α值,而不是4个样本来表示颜色值。由于额外的Alpha通道,DXT5格式消耗DXT1格式的内存量的两倍。与每个颜色通道相比,alpha通道的存储精度高于每个颜色通道,因为与三维色彩空间相反,alpha空间是一维的。此外,总共有8个样本表示4×4块中的α值,而不是4个样本来表示颜色值。由于额外的Alpha通道,DXT5格式消耗DXT1格式的内存量的两倍。
DXT5格式可以以多种方式用于不同的目的。一个众所周知的例子是绞合正常映射[DXT5的压缩12,13 ]。DXT5格式也可用于通过使用YCoCg色彩空间进行高质量的彩色图像压缩。在YCoCg中颜色空间中首次引入了对H.264压缩[ 14,15 ]。已经显示RGB到YCoCg变换能够实现比由各种RGB到YCbCr变换获得的去相关更好的去相关性,并且当测量用于代表性的高质量RGB测试集合时,非常接近KL变换的解相关图像[ 15 ]。此外,从RGB到YCoCg的转换非常简单,只需要增加整数和移位。
在将RGB_数据转换为CoCg_Y后,可以通过使用DXT5格式实现彩色图像的高质量压缩。换句话说,亮度(Y)被存储在α通道中,色度(CoCg)被存储在5:6:5颜色通道中的前两个中。对于彩色图像,这种技术产生4:1的压缩比,质量非常好 - 通常优于4:2:0 JPEG在最高质量设置。
 切出
切出柯达图像套件图像14 的部分。
1.5 MB
以最好的质量压缩到DXT1 。
192 kB
以最好的质量压缩到YCoCg-DXT5 。
384 kB
CoCg_Y DXT5压缩图像没有显着的质量损失,消耗原始图像的四分之一。CoCg_Y DXT5看起来也比压缩成DXT1格式的图像好多了。
显然,在片段程序中检索到CoCg_Y颜色数据,需要一些工作来执行转换回RGB。然而,转换成RGB是相当简单的:
Co = color.x - (0.5 * 256.0 / 255.0)
Cg = color.y - (0.5 * 256.0 / 255.0)
Y = color.w
R = Y + Co-Cg
G = Y + Cg
B = Y-Co-Cg
此转换只需要片段程序中的三个指令。此外,过滤和其他计算通常可以在YCoCg空间中完成。
DP4 result.color.x,color,{1.0,-1.0,0.0 * 256.0 / 255.0,1.0};DP4 result.color.y,color,{0.0,1.0,-0.5 * 256.0 / 255.0,1.0};DP4 result.color.z,color,{-1.0,-1.0,1.0 * 256.0 / 255.0,1.0};
色度橙色(Co)和色度绿色(Cg)存储在前两个通道中,其中Co端点以5位存储,Cg终点存储6位。即使端点以不同的量化存储,这样也能获得最佳质量。由于Cg值影响所有三个RGB通道,Cg通道的终点以比Co通道的终点(5位)更高的精度(6位)存储,而Co值仅影响红色和蓝色渠道。
CoCg颜色空间的5:6量化可能导致轻微的颜色偏移和可能的颜色损失。理想情况下,不会有任何量化,通过CoCg颜色空间的线的终点将以8:8格式存储。幸运的是,DXT5格式的第三个通道可以用于为4×4像素块中的许多块获得高达2位的精度。当4×4块中的颜色的动态范围非常低时,颜色空间的量化是最显着的。量化可以使颜色映射到单个点,或者颜色映射到动态范围之外的点。为了克服这个问题,当颜色的动态范围很低时,颜色可以放大。在压缩过程中,颜色被放大,并在片段程序中按比例缩小到其原始值。
当CoCg空间映射到[0,255] x [0,255]的范围时,颜色灰色表示为点(128,128)。对于大多数图像,随着CoCg空间的动态范围减小,颜色趋向于变得更接近于灰色。因此,通过从所有颜色中减去(128,128),4×4像素块的颜色空间首先以灰色为中心。然后,围绕原点测量4x4块的色彩空间的动态范围:max(abs(min),abs(max))。如果两个通道的动态范围小于64,则所有CoCg值都按比例放大2倍。如果动态范围小于32,则所有CoCg值都按比例增加4倍。动态范围范围必须分别小于64和32,以确保颜色值不会溢出。实际上,将颜色缩放2,所有CoCg值的最后一位总是设置为零,因此不受量化的影响。以相同的方式,如果颜色按比例放大4,则最后两位始终为零,也不受量化影响。
在DXT5格式的第三个通道中,比例因子1,2或4作为一个恒定值存储在整个4×4像素块上。存储在整个块上的恒定值,比例因子的存在不影响CoCg通道的压缩。比例因子存储为(scale-1)* 8,使得比例因子仅使用5位通道的两个最低有效位。因此,比例因子不受到5比特的量化和DXT5解码器中的反量化和扩展的影响,其中较高的3比特被复制到较低的三比特。下图显示了DXT5解码器中缩放因子从5位扩展到8位。
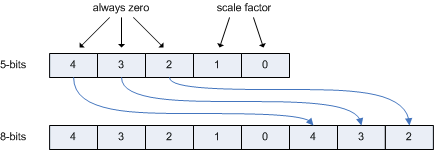
当像这样将图像编码为YCoCg-DXT5时,片段程序需要更多的工作才能转换回RGB。以下伪代码显示了转换。
scale =(color.z *(255.0 / 8.0))+ 1.0
Co =(color.x - (0.5 * 256.0 / 255.0))/ scale
Cg =(color.y - (0.5 * 256.0 / 255.0))/ scale
Y = color.w
R = Y + Co-Cg
G = Y + Cg
B = Y-Co-Cg
在片段程序中,这意味着:
MAD color.z,color.z,255.0 / 8.0,1.0;RCP color.z,color.z;MUL color.xy,color.xyxy,color.z;DP4 result.color.x,color,{1.0,-1.0,0.0 * 256.0 / 255.0,1.0};DP4 result.color.y,color,{0.0,1.0,-0.5 * 256.0 / 255.0,1.0};DP4 result.color.z,color,{-1.0,-1.0,1.0 * 256.0 / 255.0,1.0};
换句话说,片段程序中只需要三个指令来缩小CoCg值。
右下方的图像显示了在左侧原始图像旁边的CoCg值缩放的YCoCg压缩结果。
 切出
切出柯达图像套件图像14 的部分。
1.5 MB压缩至可扩展的YCoCg-DXT5
,质量最好。
384 kB
对于几乎所有的图像,当放大CoCg值时,质量明显更高。然而,值得注意的是,缩放的CoCg值的线性纹理滤波(例如双线性滤波)可以导致颜色值的非线性滤波。在颜色值按比例缩小之前,分别对颜色值和比例因子进行过滤。换句话说,将过滤的比例因子应用于过滤的CoCg值 - 这与先前按比例缩小的过滤颜色值不同。有趣的是,当测量双线性滤波的YCoCg-DXT5压缩纹理相对于双线性滤波的原始纹理的质量时,当CoCg值被放大时,质量仍然显着更高,即使纹理过滤可能导致颜色被缩放向下错误
不正确的缩放仅影响具有不同比例因子的4×4块纹素之间的边界上的样本,并且大多数时间相邻块的比例因子相同。具有不同比例因子的块之间的内插颜色趋向于与具有最高比例因子的4×4块的颜色值更快地收敛。然而,由于难以辨别双线性滤波器图案和非线性滤波器图案之间的差异,感知质量通常没有明显的差异。也没有不自然的色彩转换,因为Co和Cg值经历相同的非线性滤波,不会漂移。换句话说,颜色转换仍然沿着CoCg空间中的直线 - 只是不是以恒定的速度。
由于过滤在具有不同比例因子的4x4块的边界处是非线性的,重要的是滤除的颜色值保持在来自4×4块的原始颜色值之间。换句话说,颜色值不应超出范围 - 这将导致伪像。下图显示了带有比例因子S0,S1,S2和S3以及参数“q”和“r”的纹素值P0,P1,P2和P3之间双线性滤波的工作原理。
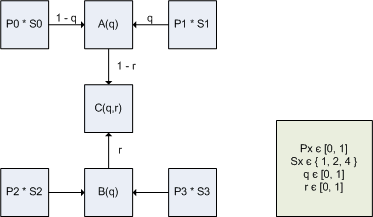
对于常规双线性滤波,比例因子S0,S1,S2和S3都设置为1,并且纹理值如下内插。
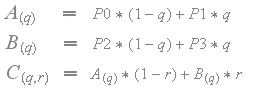
当CoCg值用相邻块的不同比例因子放大时,则滤波变为非线性,如下。
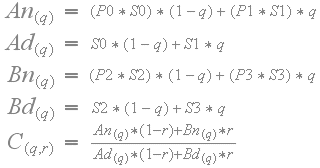
滤波后的颜色值不应超出范围,因此对于滤波后的样本C(q,r),必须满足以下条件:min(P0,P1,P2,P3)<= C(q,r)<= max ,P1,P2,P3)。首先,看到滤波后的样本C(q,r)等于拐角处的原始纹素值之一是很简单的。
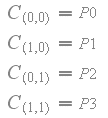
由于样本C(q,r)等于拐角处的原始纹理值之一,所以函数C(q,r)对于任何常数“r”必须单调递增或单调递减,因此样本不能出来的范围。换句话说,C(q,r)相对于'q'的偏导数不能改变符号。C(q,r)相对于'q'的偏导数如下:
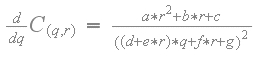
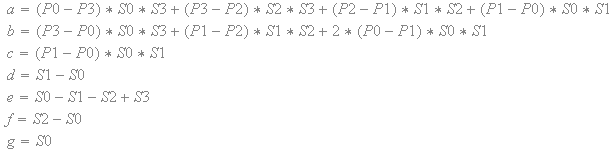
基于纹素值和比例因子,'a','b','c','d','e','f'和'g'的表达式是正或负常数。分子是正或负的常数。变量“q”只能在分母中出现一次。此外,分母是平方的,因此总是积极的。换句话说,偏导数永远不会改变符号。
同样,函数C(q,r)对于任何常数“q”必须单调增加或单调递减,这意味着C(q,r)相对于'r'的偏导数也必须永远不会改变符号。C(q,r)相对于'r'的偏导数如下:
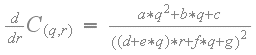
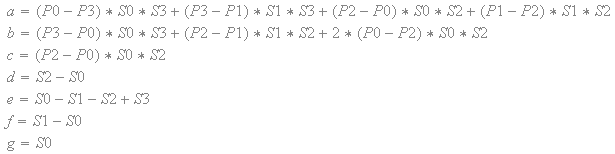
与对于'q'的偏导数一样,相对于'r'的偏导数也从不改变符号。由于函数C(q,r)经过了角部的原始纹素值,并且函数在常数“r”下单调增加或单调递减,并且在恒定“q”时也单调递增或单调递减,样本C(q,r)永远不能超出范围,如下:min(P0,P1,P2,P3)<= C(q,r)<= max(P0,P1,P2,P3)
如果比例因子不同,三线滤波和各向异性过滤也会变得非线性。然而,与双线性滤波一样,滤波后的样本也在原始纹素值之间很好地界定。
5. CPU上的实时YCoCg-DXT5
使用常规实时DXT5压缩器压缩到YCoCg-DXT5确实比使用DXT1压缩更好的质量,并且通常几乎没有细节损失[ 9 ]。然而,有明显的色彩瑕疵。特别是有颜色阻挡和颜色渗色伪像。来自[ 9 ] 的实时DXT5压缩器通过CoCg空间在线上以等距点近似每个4x4块中的颜色,其中线通过CoCg空间的边界框的范围创建。问题是,经常选择CoCg空间边界的错误对角线。这在基本颜色之间的过渡特别明显,这导致颜色渗色伪像。
要获得更好的质量,应使用CoCg空间的二维边界盒的两个对角线中最好的。[ 9 ]中描述的实时DXT5压缩器可以扩展为选择两个对角线之一。确定使用哪个对角线的最佳方式是测试颜色值相对于CoCg空间边界中心的协方差的符号。以下例程通过CoCg空间交换线的端点的两个坐标,基于哪个对角线最适合4×4像素块中的颜色。
void SelectYCoCgDiagonal(const byte * colorBlock,byte * minColor,byte * maxColor){ 字节mid0 =((int)minColor [0] + maxColor [0] + 1)>> 1; 字节mid1 =((int)minColor [1] + maxColor [1] + 1)>> 1; int协方差= 0; for(int i = 0; i <16; i ++){ int b0 = colorBlock [i * 4 + 0] - mid0; int b1 = colorBlock [i * 4 + 1] - mid1; 协方差+ =(b0 * b1); } if(协方差<0){ 字节t = minColor [1]; minColor [1] = maxColor [1] maxColor [1] = t; }}
计算协方差需要颜色值的乘法,这增加了动态范围,并限制了通过SIMD指令集可以利用的并行度。代替计算颜色值的协方差,也可以选择仅相对于颜色空间的边界框的中心的颜色的符号位的协方差。有趣的是,仅使用符号位时质量的损失真的很小,一般可以忽略不计。以下例程仅基于符号位的协方差,通过CoCg空间交换线路端点的两个坐标。
void SelectYCoCgDiagonal(const byte * colorBlock,byte * minColor,byte * maxColor){ 字节mid0 =((int)minColor [0] + maxColor [0] + 1)>> 1; 字节mid1 =((int)minColor [1] + maxColor [1] + 1)>> 1; 字节边= 0; for(int i = 0; i <16; i ++){ 字节b0 = colorBlock [i * 4 + 0]> = mid0; 字节b1 = colorBlock [i * 4 + 1]> = mid1; 侧+ =(b0 ^ b1); } byte mask = - (side> 8); 字节c0 = minColor [1]; 字节c1 = maxColor [1]; c0 ^ = c1 ^ = mask&= c0 ^ = c1; minColor [1] = c0; maxColor [1] = c1;}
动态范围没有增加,上述例程中的循环可以使用仅对字节进行操作来实现,这允许通过SIMD指令集最大化并行化。实际上,该例程将CoCg空间的边界框划分为四个统一象限如下:
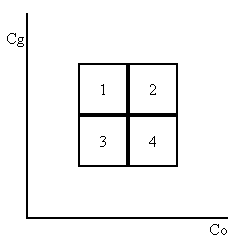
然后,例程计算落入每个象限的颜色数量。如果大多数颜色在象限2和3中,则使用通过边界框扩展区的规则对角线。然而,如果大多数颜色在象限1和4中,则使用相反的对角线。
例程首先计算Co和Cg范围的中点。然后将颜色值与这些中点进行比较。下表显示了4个象限与大于或等于中点的CoCg值之间的关系。对比较结果使用按位逻辑异或运算,只能对于象限1或4中的颜色产生“1”。颜色的异或运算结果可以累加,以计算颜色数在象限1和4中。如果超过一半的颜色在象限1或4中,则对角线需要翻转。
使用MMX和SSE2指令集的实现可以分别在附录C和D中找到。MMX / SSE2指令“pavgb”用于计算Co和Cg范围的中点。不幸的是,在MMX或SSE2指令集中没有指令用于比较无符号字节。只有“pcmpeqb”指令对有符号和无符号字节都有效。但是,'pmaxub'指令使用无符号字节。为了评估一个大于或等于的关系,使用'pmaxub'指令后跟'pcmpeqb'指令,因为表达式(x> = y)等价于表达式(max(x,y)== x )。
MMX / SSE2指令“psadbw”通常用于计算绝对差的和。但是,该指令也可用于通过将其中一个操作数设置为全零来执行水平加法。附录C和D中的MMX / SSE2实现使用“psadbw”指令来添加按位逻辑异或运算的结果。
为了翻转对角线,例程使用一个掩蔽的XOR交换,这只需要4条指令。该掩码用于选择需要交换的两个寄存器的位。假设要交换的位被存储在寄存器“xmm0”和“xmm1”中,掩码存储在寄存器“xmm2”中。以下SSE2代码从“xmm0”和“xmm1”中的每对位置换掉,“xmm2”中的等效位设置为1。
pxor xmm0,xmm1pand xmm2,xmm0pxor xmm1,xmm2pxor xmm0,xmm1
使用屏蔽XOR交换,“minColor”和“maxColor”字节数组可以直接读入两个寄存器。然后可以通过使用适当的掩码来交换第二个字节,而不必从寄存器中提取字节。
以下图像显示原始图像,压缩为YCoCg-DXT5的图像与实时DXT5压缩器[ 9 ]之间的差异,以及使用新的实时YCoCg-DXT5压缩器压缩为YCoCg-DXT5的图像最好的对角线。图像显示当使用这个小型扩展到实时DXT5压缩器时,没有明显的颜色渗色。

 切出
切出柯达图像套件图像14 的部分。
1.5 MB压缩至具有
实时DXT5压缩机的YCoCg-DXT5 。
384 kB使用
实时YCoCg-DXT5压缩机压缩至YCoCg-DXT5 。
384 kB
来自[ 9 ] 的DXT5压缩器插入了颜色空间和alpha空间的边界框,以提高均方误差(MSE)。颜色空间的边界框通过颜色空间在线上的两点之间的距离总共为一半。通过颜色空间有4点,因此边框在任意一端插入范围的1/16。以相同的方式,α空间的界限通过α空间在线上的两点之间的距离总共插入一半。换句话说,alpha空间的边界在任一端插入范围的1/32。
插入边框的副作用是对于具有低动态范围(小边界框)的4x4像素的块,通过颜色空间或α空间的线上的点可能捕捉到彼此非常接近的点。在这种情况下,将线的端点稍微分开一点,以便覆盖较大的动态范围,其中内插点通常将更接近原始值。以下代码首先插入颜色空间的边界框,然后向外舍入线的端点,以便线覆盖更大的动态范围。以同样的方式,α空间的界限首先插入,然后向外舍入。
#define INSET_COLOR_SHIFT 4 //插入颜色边界框#define INSET_ALPHA_SHIFT 5 //插入alpha边界框 #define C565_5_MASK 0xF8 // 0xFF减去最后三位#define C565_6_MASK 0xFC // 0xFF减去最后两位 void InsetYCoCgBBox(byte * minColor,byte * maxColor){ int inset [4]; int mini [4]; int maxi [4]; inset [0] =(maxColor [0] - minColor [0]) - ((1 <<(INSET_COLOR_SHIFT-1)) - 1); inset [1] =(maxColor [1] - minColor [1]) - ((1 <<(INSET_COLOR_SHIFT-1)) - 1); inset [3] =(maxColor [3] - minColor [3]) - ((1 <<(INSET_ALPHA_SHIFT-1))-1); mini [0] =((minColor [0] << INSET_COLOR_SHIFT)+ inset [0])>> INSET_COLOR_SHIFT; mini [1] =((minColor [1] << INSET_COLOR_SHIFT)+ inset [1])>> INSET_COLOR_SHIFT; mini [3] =((minColor [3] << INSET_ALPHA_SHIFT)+ inset [3])>> INSET_ALPHA_SHIFT; maxi [0] =((maxColor [0] << INSET_COLOR_SHIFT) - inset [0])>> INSET_COLOR_SHIFT; maxi [1] =((maxColor [1] << INSET_COLOR_SHIFT) - inset [1])>> INSET_COLOR_SHIFT; maxi [3] =((maxColor [3] << INSET_ALPHA_SHIFT) - inset [3])>> INSET_ALPHA_SHIFT; mini [0] =(mini [0]> = 0)?迷你[0]:0; mini [1] =(mini [1]> = 0)?迷你[1]:0; mini [3] =(mini [3]> = 0)?迷你[3]:0; maxi [0] =(maxi [0] <= 255)?maxi [0]:255; maxi [1] =(maxi [1] <= 255)?maxi [1]:255; maxi [3] =(maxi [3] <= 255)?maxi [3]:255; minColor [0] =(mini [0]&C565_5_MASK)| (mini [0] >> 5); minColor [1] =(mini [1]&C565_6_MASK)| (mini [1] >> 6); minColor [3] =迷你[3]; maxColor [0] =(maxi [0]&C565_5_MASK)| (maxi [0] >> 5); maxColor [1] =(maxi [1]&C565_6_MASK)| (maxi [1] >> 6); maxColor [3] = maxi [3];}
'pmullw'指令用于升档值。与MMX / SSE2移位指令不同,'pmullw'指令允许寄存器中的单个字与不同的值相乘。乘法器是存储在前两个通道中的CoCg值的(1 << INSET_COLOR_SHIFT)和存储在阿尔法通道中的Y值的(1 << INSET_ALPHA_SHIFT)。以同样的方式,通过使用CoCg值的乘法器(1 <<(16 - INSET_COLOR_SHIFT))和Y值的(1 <<(16 - INSET_ALPHA_SHIFT))来使用'pmulhw'指令向下移动。
除了选择最佳的对角线和用适当的四舍五入对边界进行插值外,CoCg值也可以实时放大以获得精确度。以下代码显示了如何将其作为现有实时DXT5编码器的扩展来实现。
void ScaleYCoCg(byte * colorBlock,byte * minColor,byte * maxColor){ int m0 = abs(minColor [0] - 128); int m1 = abs(minColor [1] - 128); int m2 = abs(maxColor [0] - 128); int m3 = abs(maxColor [1] - 128); if(m1> m0)m0 = m1; 如果(m3> m2)m2 = m3; 如果(m2> m0)m0 = m2; const int s0 = 128/2 - 1; const int s1 = 128/4 - 1; int mask0 = - (m0 <= s0); int mask1 = - (m0 <= s1); int scale = 1 +(1&mask0)+(2&mask1); minColor [0] =(minColor [0] - 128)* scale + 128; minColor [1] =(minColor [1] - 128)* scale + 128; minColor [2] =(scale-1)<< 3; maxColor [0] =(maxColor [0] - 128)* scale + 128; maxColor [1] =(maxColor [1] - 128)* scale + 128; maxColor [2] =(scale-1)<< 3; for(int i = 0; i <16; i ++){ colorBlock [i * 4 + 0] =(colorBlock [i * 4 + 0] - 128)* scale + 128; colorBlock [i * 4 + 1] =(colorBlock [i * 4 + 1] - 128)* scale + 128; }}
为了利用最大并行度,CoCg值最好放大为字节,而不需要更多的位。这似乎很直接,除了MMX和SSE2指令集中没有指令移位或乘以字节。此外,128需要从无符号字节中减去,这可能导致负值。也不能将128表示为有符号字节。但是,无符号字节可以静默地转换为有符号字节,然后可以添加带符号的字节值-128。对于正确处理的包装,这将得到与从无符号字节减去128相同的计算结果,其中结果是有符号字节,如果原始值低于128,则可能会变为负数。
比例因子是2的幂,这意味着比例等于移位。因此,可以使用字乘法同时缩放两个字节,并且可以将结果屏蔽以从移入第二个字节的第一个字节中移除任何进位位。以下代码显示了在bias = 128和scale = 1,2或4时如何实现。
词1字0 词1字0 / \/ \ / \/ \ 字节3字节2字节1字节0 字节3字节2字节1字节0PADDBÿ一个CG有限公司+ =00- 偏见- 偏见pmullwYACgCo* =1规模PANDÿ一个CG有限公司&=为0xFF为0xFF〜(刻度-1)〜(刻度-1)PSUBBÿ一个CG有限公司- =00- 偏见- 偏见缩放字节后,通过减去有符号字节值-128将它们放回[0,255]范围内。上面的代码显示了像素的所有四个字节如何加载到寄存器中,但只有CoCg值被放大,而Y值乘以1.这样可以避免大量的解压缩和swizzle代码,否则需要提取所有像素的CoCg值。
下图右侧的图像显示了实时DXT5压缩器的扩展结果,在左侧的原始图像旁边。
 切出
切出柯达图像套件图像14 的部分。
1.5 MB使用
实时YCoCg-DXT5压缩器压缩至YCoCg-DXT5,
使用所有扩展。
384 kB
最终的结果是没有颜色阻挡伪像,并且由于5:6量化,颜色偏移很小。
6.DXT压缩在GPU上
实时DXT1和YCoCg-DXT5也可以在GPU上实现。这是可能的,由于DX10类图形硬件上提供的新功能。特别是整数纹理[ 17 ]和整数指令[ 18 ]对于在GPU上实现纹理压缩非常有用。
假设需要压缩的图像作为未压缩的RGB纹理存在于视频存储器中。如果图像在视频内存中不可用,则必须从主机上传。这是使用DMA传输完成的,通常速度通常为2 GB / s。为了压缩纹理,通过在整个目标表面上渲染四边形,为4x4纹理的每个块使用片段程序。现在不可能直接将结果写入DXT压缩纹理,而是将结果写入整数纹理。请注意,DXT1块的大小为64位,这等于每个组件32位的一个LA纹理。类似地,DXT5块的大小是128位,这等于一个RGBA纹素,每个元件有32位。
一旦将压缩的DXT块存储到整数纹理的纹素中,就需要将它们复制到压缩纹理。此副本无法直接执行。然而,通过将整数纹理的内容复制到PBO中,可以使用中间像素缓冲对象(PBO),然后从PBO到压缩纹理。这两个副本在视频驱动程序中实现为非常快的视频存储器副本,并且与压缩成本相比,成本是微不足道的。
此处介绍的片段和顶点程序针对NVIDIA GeForce 8系列GPU进行了优化。从优化的角度来看,CPU和GeForce 8系列GPU之间有几个重要的区别。在CPU上,使用整数运算来利用最大并行度有一个优势。然而,在GeForce 8系列GPU中,大多数浮点运算与整数运算一样快或更快。因为这样的浮点值在它更自然或者节省计算时就被使用。由于使用浮点运算,GPU实现的结果与CPU实现的结果并不等同。然而,结果仍然非常类似于CPU实现的结果。
CPU和GeForce 8系列GPU之间的另一个重要区别是,GeForce 8系列GPU是标量处理器。因此,不需要编写向量化代码。此外,片段和顶点程序通常很短,编译器可以执行优化,对于大型C ++程序来说,这将是非常昂贵的。因此,使用高级着色语言,可以实现通过为GPU编写低级汇编代码而获得的几乎相同的性能。这里介绍的片段和顶点程序是使用OpenGL和Cg 2.0着色语言实现的[ 19 ]。
7. GPU上的实时DXT1
两台离线和实时DXT1压缩机都已经在GPU上实现了。NVIDIA纹理工具[ 10 ]提供了在CUDA中实现的高质量DXT1压缩器,与等效的CPU实现相比具有非常好的性能。然而,这种压缩机设计用于高质量的压缩 - 而不是实时压缩。
NVIDIA SDK10 [ 11 ]提供了实时DXT1压缩的示例。这里提供的实时DXT1压缩器的GPU实现基于该示例,但增加了前面部分中描述的一些质量改进。如第5节所述,颜色空间的边界框是通过边界框角部的两条等距点之间的距离插入的一半。然后将端点向外舍入,以避免将它们卡到单个点。这种小的改进没有明显的性能损失。
如第3节所述,4×4像素块中的RGB颜色倾向于通过RGB颜色空间的边界框的范围很好地映射到线上的等距点,因为该线跨越完整的动态范围,并且倾向于符合亮度分布。来自[ 9 ]和[ 11 ] 的DXT1压缩机总是通过边界区域使用该线。
在相对较小的性能成本下,可以通过选择RGB空间的边界框的最佳对角线来改善压缩质量,类似于实时YCoCg-DXT5压缩器如何选择CoCg空间的边界框的最佳对角线。然而,通过RGB空间选择最佳对角线仅影响柯达无损真彩色图像套件中所有4x4像素块的2%[ 16 ]。这与YCoCg-DXT5压缩有很大不同,其中通过CoCg空间选择最佳对角线影响了接近所有4x4像素块的50%。
对于柯达图像,峰值信噪比(PSNR)的改进,从选择最佳对角线到RGB空间,通常很小。对于图像2和23,对于图像3和14,PSNR具有大约0.7dB的改善,对于图像3和14,它是0.2到0.3dB的改进,并且对于所有其他图像,改进在0.2dB以下,并且所有柯达图像的平均改进为0.1 dB。然而,感觉质量的改善在图像的某些领域可能是重要的。特别地,在基本颜色之间具有过渡的区域中,质量可能显着改善。如果对于具有这种转变的块选择了错误的对角线,则颜色可能完全改变,这对于人眼可能是相当明显的。另一方面,DXT1压缩格式通常在这些区域中表现不佳,
最后,它是质量和性能之间的权衡。选择最佳对角线可以以相对较小(10%至20%)的性能成本提高某些图像的质量。DXT1压缩器的GPU实现可以在附录E中找到。该实现包括用于选择RGB空间边界框的最佳对角线的代码,但默认情况下不启用。附录E中的实现速度比[ 11 ] 更快。性能提升是仔细调整性能代码的结果; 消除冗余和不必要的计算,并重组代码以最小化寄存器分配。
8. GPU上的实时YCoCg-DXT5
YCoCg-DXT5压缩片段程序的实现相对简单。因此,仅描述相关细节,并突出显示与CPU实现相比的差异。片段方案的全面实施见附录E.
片段程序的第一步是读取需要压缩的4x4纹理的块。这通常使用常规纹理采样完成。然而,使用纹理提取更有效; 一个新功能,允许使用纹理地址和固定偏移量加载单个纹素,而不进行任何滤波或采样。这在Cg 2.0 [ 19 ] 中公开,并且获取4x4纹素的块被实现如下。
void ExtractColorBlock(out float3 block [16],sampler2D image,float2 tc,float2 imageSize){ int4 base = int4(tc * imageSize - 1.5,0,0); block [0] = toYCoCg(tex2Dfetch(image,base,int2(0,0)).rgb); 块[1] = toYCoCg(tex2Dfetch(image,base,int2(1,0)).rgb); block [2] = toYCoCg(tex2Dfetch(image,base,int2(2,0)).rgb); block [3] = toYCoCg(tex2Dfetch(image,base,int2(3,0)).rgb); block [4] = toYCoCg(tex2Dfetch(image,base,int2(0,1)).rgb); block [5] = toYCoCg(tex2Dfetch(image,base,int2(1,1)).rgb); block [6] = toYCoCg(tex2Dfetch(image,base,int2(2,1)).rgb); block [7] = toYCoCg(tex2Dfetch(image,base,int2(3,1)).rgb); block [8] = toYCoCg(tex2Dfetch(image,base,int2(0,2)).rgb); block [9] = toYCoCg(tex2Dfetch(image,base,int2(1,2)).rgb); block [10] = toYCoCg(tex2Dfetch(image,base,int2(2,2)).rgb); block [11] = toYCoCg(tex2Dfetch(image,base,int2(3,2)).rgb); block [12] = toYCoCg(tex2Dfetch(image,base,int2(0,3)).rgb); block [13] = toYCoCg(tex2Dfetch(image,base,int2(1,3)).rgb); block [14] = toYCoCg(tex2Dfetch(image,base,int2(2,3)).rgb); block [15] = toYCoCg(tex2Dfetch(image,base,int2(3,3)).rgb);}
取代将获取的颜色转换为整数,它们保持为浮点格式。然后,该算法以与CPU算法相同的方式继续进行,除了使用浮点值。首先,计算CoCg值的边界框,然后选择绑定框的两个对角线之一。选择其中一个对角线的最佳方法是测试CoCg值的协方差的符号。这可以在GPU上非常有效地实现,因此不需要使用符号位的协方差近似对角线选择。
void SelectYCoCgDiagonal(const float3 block [16],in out float2 minColor,in out float2 maxColor){ float2 mid =(maxColor + minColor)* 0.5; 浮点协方差= 0.0; for(int i = 0; i <16; i ++){ float2 t = block [i] .yz - mid; 协方差+ = tx * ty; } if(协方差<0.0){ swap(maxColor.y,minColor.y); }}
正如CPU实现一样,通过CoCg空间,使用比例因子来为线路的端点获得高达两位精度。然而,没有必要像在CPU中一样高调所有的CoCg值。通过CoCg空间的线的端点以浮点格式表示,因此可以在应用插入后简单地缩小端点,并且颜色已舍入并转换为5:6格式。因此,可以将每个纹素的原始CoCg值与通过CoCg空间的线上的未缩放点进行比较,以找到每个纹素的最佳匹配点。比例因子本身以与CPU实现相同的方式计算。
int GetYCoCgScale(float2 minColor,float2 maxColor){ float2 m0 = abs(minColor - offset); float2 m1 = abs(maxColor - offset); float m = max(max(m0.x,m0.y),max(m1.x,m1.y)); const float s0 = 64.0 / 255.0; const float s1 = 32.0 / 255.0; int scale = 1; if(m <s0)scale = 2; if(m <s1)scale = 4; 回报量表}
在计算比例因子后,通过CoCg空间的线路的端点如在CPU实现中进行插值,量化和位扩展。
在CPU上,计算曼哈顿距离,以便通过每个纹素的CoCg空间找到线上最佳匹配点。这可以使用用于计算绝对差的压缩和的指令非常有效地实现。然而,在GPU上,使用平方欧几里德距离更为有效,可以用单点积计算。
float colorDistance(float2 c0,float2 c1){ 返回点(c0-c1,c0-c1);}
着色器的输出是一个4分量的无符号整数向量。在片段程序中,DXT块的每个部分都被写入一个向量组件,并返回最终值。
// DXT1块中的输出CoCg。 uint4 output; output.z = EmitEndPointsYCoCgDXT5(mincol.yz,maxcol.yz,scale); output.w = EmitIndicesYCoCgDXT5(block,mincol.yz,maxcol.yz); // DXT5 alpha块中输出Y。 output.x = EmitAlphaEndPointsYCoCgDXT5(mincol.x,maxcol.x); uint2 indices = EmitAlphaIndicesYCoCgDXT5(block,mincol.x,maxcol.x); output.x | = indices.x; output.y = indices.y; 返回输出;
9.对CPU与GPU的压缩
如前面部分所示,可以在CPU和GPU上实现高性能DXT压缩。压缩是否最好在CPU或GPU上实现依赖于应用程序。
CPU上的实时DXT压缩对于在CPU上动态创建的纹理很有用。CPU上的压缩对于以不能用于渲染的格式从磁盘流式传输的纹理数据进行转码也特别有用。例如,纹理可以以JPEG格式存储在磁盘上,因此不能直接用于渲染。JPEG解压缩算法的一些部分目前可以在GPU上高效地实现。存储器可以保存在图形卡上,通过解压缩原始数据并将其重新压缩为DXT格式,可以提高渲染性能。在CPU上重新压缩纹理数据的优点是上传到图形卡的数据量很小。此外,当在CPU上执行压缩时,完整的GPU可以用于渲染工作,因为它不需要执行任何压缩。对于当今CPU上越来越多的内核的确定趋势,通常可以轻松地使用可用于纹理压缩的免费内核。
因为对于代码转换,实时压缩可能不太有用,因为用于上传未压缩纹理数据的带宽需求增加,并且因为GPU可能已经被昂贵的渲染工作所约束了。然而,GPU上的实时压缩对压缩的渲染目标非常有用。GPU上的压缩可以用于在渲染到纹理时节省内存。此外,如果来自渲染目标的数据用于进一步渲染,则这样的压缩渲染目标可以提高性能。渲染目标被压缩一次,而渲染过程中可能会多次访问生成的数据。压缩数据导致光栅化期间带宽要求降低,因此可以显着提高性能。
10.结果
使用柯达无损真彩色图像套件测试了DXT1格式和YCoCg-DXT5格式[ 16 ]。已经在未加权的RGB通道上计算了峰值信噪比(PSNR)。在所有情况下,使用定制压缩机进行离线压缩以获得最佳质量。此外,来自[ 9 ] 的实时DXT1压缩器和这里描述的实时YCoCg-DXT5压缩机的CPU实现被用于图像的实时压缩。
下表显示了压缩为两种格式的柯达图像的PSNR值。(PSNR越高越好)
PSNRDXT1
DXT1
YCoCg
DXT5
YCoCg
DXT5
下图显示了压缩为两种格式的柯达图像的PSNR。(PSNR越高越好)
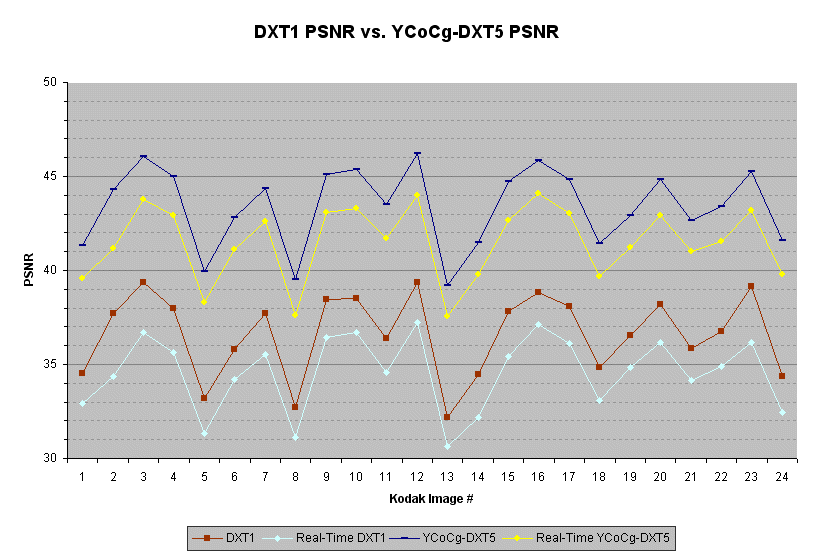
与DXT1相比,YCoCg-DXT5格式提供了6dB或更高的PSNR的一致性改进。所有PSNR值下降的图像均具有高频亮度变化的区域。从PSNR的角度来看,两种格式都不能很好地编码这些区域。然而,通常很难在具有高频亮度变化的区域中区分压缩图案与原始图案。
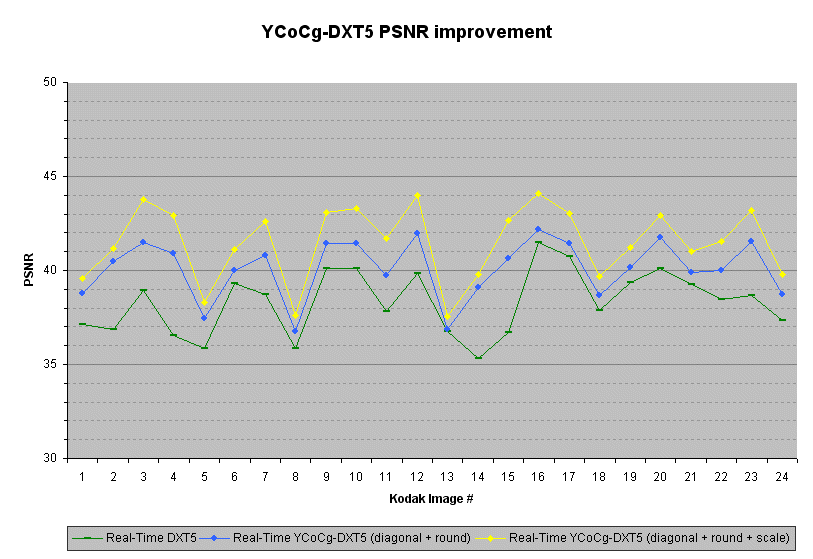
下图显示了使用以下压缩器压缩的柯达图像的PSNR改进:来自[ 9 ] 的实时DXT5编码器; 实时YCoCg-DXT5编码器,选择最佳对角线,并在插入边界时使用正确的舍入; 和实时YCoCg-DXT5编码器,这也提高了CoCg值以获得精度。(PSNR越高越好)
SIMD优化的实时DXT压缩器的性能已经在英特尔®2.8 GHz双核至强®(“Paxville”90nm NetBurst微体系结构)和英特尔®2.9 GHz Core™2 Extreme(“Conroe”65nm Core 2微架构)。这些处理器中只有一个核心用于压缩。由于纹理压缩是基于块的,所以压缩算法可以容易地使用多个线程来利用这些处理器的所有核心。当使用多个内核时,可预期的线速度随着可用内核的数量而增加。性能也在NVIDIA GeForce 8600 GTS和NVIDIA GeForce 8800 GTX上进行了测试。512x512 Lena图像已被用于所有的性能测试。
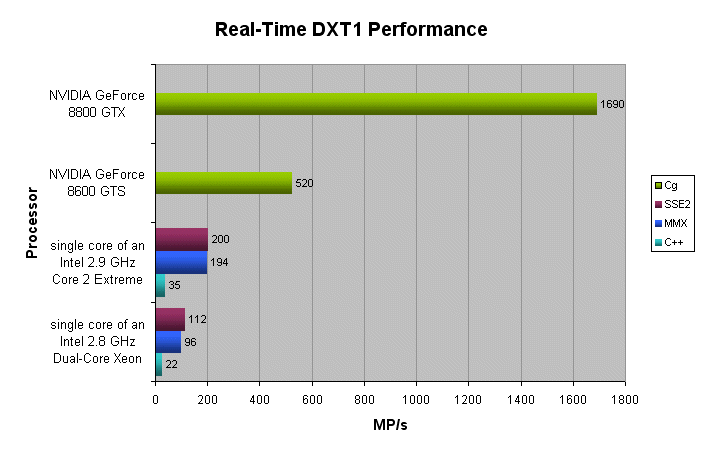
下图显示了可以每秒压缩到DXT1格式的多个像素数(更高的MP / s =更好)。
下图显示了每秒可以压缩到YCoCg-DXT5格式的兆像素的数量(更高的MP / s =更好)。
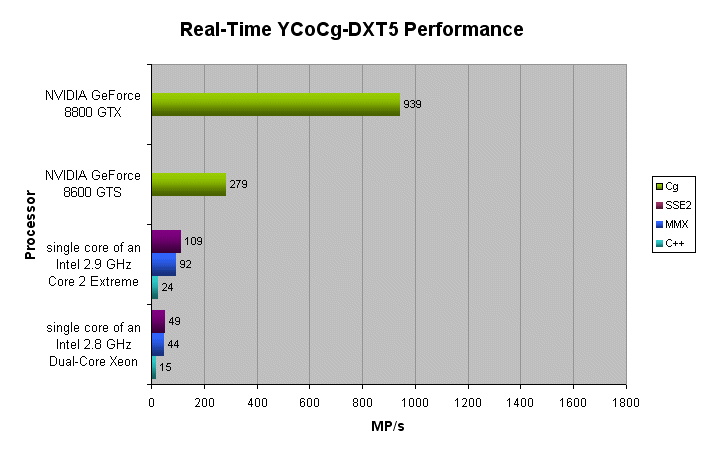
数据显示,YCoCg-DXT5的实时压缩是DXT1实时压缩的高性能替代品。此外,在高端NVIDIA GeForce 8系列GPU上,实时DXT1和YCoCg-DXT5压缩算法的运行速度比高端英特尔®酷睿™2 CPU单核的速度快8倍。换句话说,需要超过8个Intel®Core™2内核来实现类似的性能。
结论
YCoCg-DXT5格式消耗DXT1格式的两倍内存。然而,质量明显好转,对大多数图像来说,质量几乎没有明显的损失。此外,可以在CPU和GPU上实时完成对YCoCg-DXT5的高质量压缩。因此,YCoCg-DXT5格式在无压缩和实时DXT1压缩之间提供了非常好的中间位置。
参考文献
1。S3纹理压缩Pat Brown
NVIDIA Corporation,2001年11月
在线提供:http://www.opengl.org/registry/specs/EXT/texture_compression_s3tc.txt2。压缩纹理资源
Microsoft Developer Network
DirectX SDK,2006年4月
在线提供:http://msdn2.microsoft.com/en-us/library/aa915230.aspx3。使用块截断编码的图像编码
E.J. Delp,OR Mitchell
IEEE Transactions on Communications,vol。27(9),pp。1335-1342,1979年9月4。ATI Compressonator Library
Seth Sowerby,Daniel Killebrew
ATI Technologies Inc,The Compressonator版本1.27.1066,2006年3月
在线提供:http://www.ati.com/developer/compressonator.html5。NVIDIA DDS工具
NVIDIA
NVIDIA DDS工具,2006年4月
在线提供:http://developer.nvidia.com/object/nv_texture_tools.html6。NVIDIA纹理工具
NVIDIA
NVIDIA纹理工具,2007年9月
在线提供:http://developer.nvidia.com/object/texture_tools.html7。Mesa S3TC压缩库
Roland Scheidegger
libtxc_dxtn版本0.1,2006年5月
在线可用:http://homepage.hispeed.ch/rscheidegger/dri_experimental/s3tc_index.html8。Squish DXT压缩库
Simon Brown
Squish版本1.8,2006年9月
在线提供:http://sjbrown.co.uk/?code=squish9。实时DXT压缩
J.MP van Waveren
英特尔软件网络,2006年10月
在线提供:http://www.intel.com/cd/ids/developer/asmo-na/eng/324337.htm10。使用CUDA高品质的DXT压缩
伊格纳西奥·卡斯诺
NVIDIA,2007年2月
可在线获得:http://developer.download.nvidia.com/compute/cuda/sdk/website/projects/dxtc/doc/cuda_dxtc.pdf11。压缩DXT
Simon Green
NVIDIA,2007年3月
在线可用:http://developer.download.nvidia.com/SDK/10/opengl/samples.html#compress_DXT12。Bump地图压缩
Simon Green
NVIDIA技术报告,2001年10月
在线提供:http://developer.nvidia.com/object/bump_map_compression.html13。正常地图压缩
ATI Technologies Inc
ATI,2003年8月
在线提供:http://www.ati.com/developer/NormalMapCompression.pdf14。专业扩展的变换,缩放和色彩空间影响
H. S. Malvar,GJ Sullivan
ISO / IEC JTC1 / SC29 / WG11和ITU-T SG16 Q.6文件JVT-H031,日内瓦,2003年5月
在线提供:http://ftp3.itu .INT / AV-弓/ JVT网站/ 2003_05_Geneva / JVT-H031.doc15。YCoCg-R:具有RGB可逆性和低动态范围的色彩空间
H. S. Malvar,GJ Sullivan
ISO / IEC MPEG和ITU-T VCEG的联合视频组(JVT),文件号JVT-I014r3,2003年7月
可在线获取:http: //research.microsoft.com/~malvar/papers/JVT-I014r3.pdf16。柯达无损真彩色图像套件
柯达
在线可用:http://r0k.us/graphics/kodak/17。GL_EXT_texture_integer
OpenGL.org,2007年7月
在线提供:http://www.opengl.org/registry/specs/EXT/texture_integer.txt18。NV_gpu_program4
OpenGL.org,2007年2月
在线提供:http://www.opengl.org/registry/specs/NV/gpu_program4.txt19。Cg 2.0
NVIDIA,2007年7月
在线可用:http://developer.nvidia.com/page/cg_main.html
附录 A
/* RGB_ to CoCg_Y conversion and back. Copyright (C) 2007 Id Software, Inc. Written by J.M.P. van Waveren This code is free software; you can redistribute it and/or modify it under the terms of the GNU Lesser General Public License as published by the Free Software Foundation; either version 2.1 of the License, or (at your option) any later version. This code is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU Lesser General Public License for more details.*/ typedef unsigned char byte; /* RGB <-> YCoCg Y = [ 1/4 1/2 1/4] [R] Co = [ 1/2 0 -1/2] [G] CG = [-1/4 1/2 -1/4] [B] R = [ 1 1 -1] [Y] G = [ 1 0 1] [Co] B = [ 1 -1 -1] [Cg] */ byte CLAMP_BYTE( int x ) { return ( (x) < 0 ? (0) : ( (x) > 255 ? 255 : (x) ) ); } #define RGB_TO_YCOCG_Y( r, g, b ) ( ( ( r + (g<<1) + b ) + 2 ) >> 2 )#define RGB_TO_YCOCG_CO( r, g, b ) ( ( ( (r<<1) - (b<<1) ) + 2 ) >> 2 )#define RGB_TO_YCOCG_CG( r, g, b ) ( ( ( - r + (g<<1) - b ) + 2 ) >> 2 ) #define COCG_TO_R( co, cg ) ( co - cg )#define COCG_TO_G( co, cg ) ( cg )#define COCG_TO_B( co, cg ) ( - co - cg ) void ConvertRGBToCoCg_Y( byte *image, int width, int height ) { for ( int i = 0; i < width * height; i++ ) { int r = image[i*4+0]; int g = image[i*4+1]; int b = image[i*4+2]; int a = image[i*4+3]; image[i*4+0] = CLAMP_BYTE( RGB_TO_YCOCG_CO( r, g, b ) + 128 ); image[i*4+1] = CLAMP_BYTE( RGB_TO_YCOCG_CG( r, g, b ) + 128 ); image[i*4+2] = a; image[i*4+3] = CLAMP_BYTE( RGB_TO_YCOCG_Y( r, g, b ) ); }} void ConvertCoCg_YToRGB( byte *image, int width, int height ) { for ( int i = 0; i < width * height; i++ ) { int y = image[i*4+3]; int co = image[i*4+0] - 128; int cg = image[i*4+1] - 128; int a = image[i*4+2]; image[i*4+0] = CLAMP_BYTE( y + COCG_TO_R( co, cg ) ); image[i*4+1] = CLAMP_BYTE( y + COCG_TO_G( co, cg ) ); image[i*4+2] = CLAMP_BYTE( y + COCG_TO_B( co, cg ) ); image[i*4+3] = a; }}附录B
/* Real-Time YCoCg DXT Compression Copyright (C) 2007 Id Software, Inc. Written by J.M.P. van Waveren This code is free software; you can redistribute it and/or modify it under the terms of the GNU Lesser General Public License as published by the Free Software Foundation; either version 2.1 of the License, or (at your option) any later version. This code is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU Lesser General Public License for more details.*/ typedef unsigned char byte;typedef unsigned short word;typedef unsigned int dword; #define INSET_COLOR_SHIFT 4 // inset color bounding box#define INSET_ALPHA_SHIFT 5 // inset alpha bounding box #define C565_5_MASK 0xF8 // 0xFF minus last three bits#define C565_6_MASK 0xFC // 0xFF minus last two bits #define NVIDIA_G7X_HARDWARE_BUG_FIX // keep the colors sorted as: max, min byte *globalOutData; word ColorTo565( const byte *color ) { return ( ( color[ 0 ] >> 3 ) << 11 ) | ( ( color[ 1 ] >> 2 ) << 5 ) | ( color[ 2 ] >> 3 );} void EmitByte( byte b ) { globalOutData[0] = b; globalOutData += 1;} void EmitWord( word s ) { globalOutData[0] = ( s >> 0 ) & 255; globalOutData[1] = ( s >> 8 ) & 255; globalOutData += 2;} void EmitDoubleWord( dword i ) { globalOutData[0] = ( i >> 0 ) & 255; globalOutData[1] = ( i >> 8 ) & 255; globalOutData[2] = ( i >> 16 ) & 255; globalOutData[3] = ( i >> 24 ) & 255; globalOutData += 4;} void ExtractBlock( const byte *inPtr, const int width, byte *colorBlock ) { for ( int j = 0; j < 4; j++ ) { memcpy( &colorBlock[j*4*4], inPtr, 4*4 ); inPtr += width * 4; }} void GetMinMaxYCoCg( byte *colorBlock, byte *minColor, byte *maxColor ) { minColor[0] = minColor[1] = minColor[2] = minColor[3] = 255; maxColor[0] = maxColor[1] = maxColor[2] = maxColor[3] = 0; for ( int i = 0; i < 16; i++ ) { if ( colorBlock[i*4+0] < minColor[0] ) { minColor[0] = colorBlock[i*4+0]; } if ( colorBlock[i*4+1] < minColor[1] ) { minColor[1] = colorBlock[i*4+1]; } if ( colorBlock[i*4+2] < minColor[2] ) { minColor[2] = colorBlock[i*4+2]; } if ( colorBlock[i*4+3] < minColor[3] ) { minColor[3] = colorBlock[i*4+3]; } if ( colorBlock[i*4+0] > maxColor[0] ) { maxColor[0] = colorBlock[i*4+0]; } if ( colorBlock[i*4+1] > maxColor[1] ) { maxColor[1] = colorBlock[i*4+1]; } if ( colorBlock[i*4+2] > maxColor[2] ) { maxColor[2] = colorBlock[i*4+2]; } if ( colorBlock[i*4+3] > maxColor[3] ) { maxColor[3] = colorBlock[i*4+3]; } }} void ScaleYCoCg( byte *colorBlock, byte *minColor, byte *maxColor ) { int m0 = abs( minColor[0] - 128 ); int m1 = abs( minColor[1] - 128 ); int m2 = abs( maxColor[0] - 128 ); int m3 = abs( maxColor[1] - 128 ); if ( m1 > m0 ) m0 = m1; if ( m3 > m2 ) m2 = m3; if ( m2 > m0 ) m0 = m2; const int s0 = 128 / 2 - 1; const int s1 = 128 / 4 - 1; int mask0 = -( m0 <= s0 ); int mask1 = -( m0 <= s1 ); int scale = 1 + ( 1 & mask0 ) + ( 2 & mask1 ); minColor[0] = ( minColor[0] - 128 ) * scale + 128; minColor[1] = ( minColor[1] - 128 ) * scale + 128; minColor[2] = ( scale - 1 ) << 3; maxColor[0] = ( maxColor[0] - 128 ) * scale + 128; maxColor[1] = ( maxColor[1] - 128 ) * scale + 128; maxColor[2] = ( scale - 1 ) << 3; for ( int i = 0; i < 16; i++ ) { colorBlock[i*4+0] = ( colorBlock[i*4+0] - 128 ) * scale + 128; colorBlock[i*4+1] = ( colorBlock[i*4+1] - 128 ) * scale + 128; }} void InsetYCoCgBBox( byte *minColor, byte *maxColor ) { int inset[4]; int mini[4]; int maxi[4]; inset[0] = ( maxColor[0] - minColor[0] ) - ((1<<(INSET_COLOR_SHIFT-1))-1); inset[1] = ( maxColor[1] - minColor[1] ) - ((1<<(INSET_COLOR_SHIFT-1))-1); inset[3] = ( maxColor[3] - minColor[3] ) - ((1<<(INSET_ALPHA_SHIFT-1))-1); mini[0] = ( ( minColor[0] << INSET_COLOR_SHIFT ) + inset[0] ) >> INSET_COLOR_SHIFT; mini[1] = ( ( minColor[1] << INSET_COLOR_SHIFT ) + inset[1] ) >> INSET_COLOR_SHIFT; mini[3] = ( ( minColor[3] << INSET_ALPHA_SHIFT ) + inset[3] ) >> INSET_ALPHA_SHIFT; maxi[0] = ( ( maxColor[0] << INSET_COLOR_SHIFT ) - inset[0] ) >> INSET_COLOR_SHIFT; maxi[1] = ( ( maxColor[1] << INSET_COLOR_SHIFT ) - inset[1] ) >> INSET_COLOR_SHIFT; maxi[3] = ( ( maxColor[3] << INSET_ALPHA_SHIFT ) - inset[3] ) >> INSET_ALPHA_SHIFT; mini[0] = ( mini[0] >= 0 ) ? mini[0] : 0; mini[1] = ( mini[1] >= 0 ) ? mini[1] : 0; mini[3] = ( mini[3] >= 0 ) ? mini[3] : 0; maxi[0] = ( maxi[0] <= 255 ) ? maxi[0] : 255; maxi[1] = ( maxi[1] <= 255 ) ? maxi[1] : 255; maxi[3] = ( maxi[3] <= 255 ) ? maxi[3] : 255; minColor[0] = ( mini[0] & C565_5_MASK ) | ( mini[0] >> 5 ); minColor[1] = ( mini[1] & C565_6_MASK ) | ( mini[1] >> 6 ); minColor[3] = mini[3]; maxColor[0] = ( maxi[0] & C565_5_MASK ) | ( maxi[0] >> 5 ); maxColor[1] = ( maxi[1] & C565_6_MASK ) | ( maxi[1] >> 6 ); maxColor[3] = maxi[3];} void SelectYCoCgDiagonal( const byte *colorBlock, byte *minColor, byte *maxColor ) const { byte mid0 = ( (int) minColor[0] + maxColor[0] + 1 ) >> 1; byte mid1 = ( (int) minColor[1] + maxColor[1] + 1 ) >> 1; byte side = 0; for ( int i = 0; i < 16; i++ ) { byte b0 = colorBlock[i*4+0] >= mid0; byte b1 = colorBlock[i*4+1] >= mid1; side += ( b0 ^ b1 ); } byte mask = -( side > 8 ); #ifdef NVIDIA_7X_HARDWARE_BUG_FIX mask &= -( minColor[0] != maxColor[0] );#endif byte c0 = minColor[1]; byte c1 = maxColor[1]; c0 ^= c1 ^= mask &= c0 ^= c1; minColor[1] = c0; maxColor[1] = c1;} void EmitAlphaIndices( const byte *colorBlock, const byte minAlpha, const byte maxAlpha ) { assert( maxAlpha >= minAlpha ); const int ALPHA_RANGE = 7; byte mid, ab1, ab2, ab3, ab4, ab5, ab6, ab7; byte indexes[16]; mid = ( maxAlpha - minAlpha ) / ( 2 * ALPHA_RANGE ); ab1 = minAlpha + mid; ab2 = ( 6 * maxAlpha + 1 * minAlpha ) / ALPHA_RANGE + mid; ab3 = ( 5 * maxAlpha + 2 * minAlpha ) / ALPHA_RANGE + mid; ab4 = ( 4 * maxAlpha + 3 * minAlpha ) / ALPHA_RANGE + mid; ab5 = ( 3 * maxAlpha + 4 * minAlpha ) / ALPHA_RANGE + mid; ab6 = ( 2 * maxAlpha + 5 * minAlpha ) / ALPHA_RANGE + mid; ab7 = ( 1 * maxAlpha + 6 * minAlpha ) / ALPHA_RANGE + mid; for ( int i = 0; i < 16; i++ ) { byte a = colorBlock[i*4+3]; int b1 = ( a <= ab1 ); int b2 = ( a <= ab2 ); int b3 = ( a <= ab3 ); int b4 = ( a <= ab4 ); int b5 = ( a <= ab5 ); int b6 = ( a <= ab6 ); int b7 = ( a <= ab7 ); int index = ( b1 + b2 + b3 + b4 + b5 + b6 + b7 + 1 ) & 7; indexes[i] = index ^ ( 2 > index ); } EmitByte( (indexes[ 0] >> 0) | (indexes[ 1] << 3) | (indexes[ 2] << 6) ); EmitByte( (indexes[ 2] >> 2) | (indexes[ 3] << 1) | (indexes[ 4] << 4) | (indexes[ 5] << 7) ); EmitByte( (indexes[ 5] >> 1) | (indexes[ 6] << 2) | (indexes[ 7] << 5) ); EmitByte( (indexes[ 8] >> 0) | (indexes[ 9] << 3) | (indexes[10] << 6) ); EmitByte( (indexes[10] >> 2) | (indexes[11] << 1) | (indexes[12] << 4) | (indexes[13] << 7) ); EmitByte( (indexes[13] >> 1) | (indexes[14] << 2) | (indexes[15] << 5) );} void EmitColorIndices( const byte *colorBlock, const byte *minColor, const byte *maxColor ) { word colors[4][4]; unsigned int result = 0; colors[0][0] = ( maxColor[0] & C565_5_MASK ) | ( maxColor[0] >> 5 ); colors[0][1] = ( maxColor[1] & C565_6_MASK ) | ( maxColor[1] >> 6 ); colors[0][2] = ( maxColor[2] & C565_5_MASK ) | ( maxColor[2] >> 5 ); colors[0][3] = 0; colors[1][0] = ( minColor[0] & C565_5_MASK ) | ( minColor[0] >> 5 ); colors[1][1] = ( minColor[1] & C565_6_MASK ) | ( minColor[1] >> 6 ); colors[1][2] = ( minColor[2] & C565_5_MASK ) | ( minColor[2] >> 5 ); colors[1][3] = 0; colors[2][0] = ( 2 * colors[0][0] + 1 * colors[1][0] ) / 3; colors[2][1] = ( 2 * colors[0][1] + 1 * colors[1][1] ) / 3; colors[2][2] = ( 2 * colors[0][2] + 1 * colors[1][2] ) / 3; colors[2][3] = 0; colors[3][0] = ( 1 * colors[0][0] + 2 * colors[1][0] ) / 3; colors[3][1] = ( 1 * colors[0][1] + 2 * colors[1][1] ) / 3; colors[3][2] = ( 1 * colors[0][2] + 2 * colors[1][2] ) / 3; colors[3][3] = 0; for ( int i = 15; i >= 0; i-- ) { int c0, c1, d0, d1, d2, d3; c0 = colorBlock[i*4+0]; c1 = colorBlock[i*4+1]; int d0 = abs( colors[0][0] - c0 ) + abs( colors[0][1] - c1 ); int d1 = abs( colors[1][0] - c0 ) + abs( colors[1][1] - c1 ); int d2 = abs( colors[2][0] - c0 ) + abs( colors[2][1] - c1 ); int d3 = abs( colors[3][0] - c0 ) + abs( colors[3][1] - c1 ); bool b0 = d0 > d3; bool b1 = d1 > d2; bool b2 = d0 > d2; bool b3 = d1 > d3; bool b4 = d2 > d3; int x0 = b1 & b2; int x1 = b0 & b3; int x2 = b0 & b4; result |= ( x2 | ( ( x0 | x1 ) << 1 ) ) << ( i << 1 ); } EmitUInt( result );} bool CompressYCoCgDXT5( const byte *inBuf, byte *outBuf, int width, int height, int &outputBytes ) { byte block[64]; byte minColor[4]; byte maxColor[4]; globalOutData = outBuf; for ( int j = 0; j < height; j += 4, inBuf += width * 4*4 ) { for ( int i = 0; i < width; i += 4 ) { ExtractBlock( inBuf + i * 4, width, block ); GetMinMaxYCoCg( block, minColor, maxColor ); ScaleYCoCg( block, minColor, maxColor ); InsetYCoCgBBox( minColor, maxColor ); SelectYCoCgDiagonal( block, minColor, maxColor ); EmitByte( maxColor[3] ); EmitByte( minColor[3] ); EmitAlphaIndices( block, minColor[3], maxColor[3] ); EmitUShort( ColorTo565( maxColor ) ); EmitUShort( ColorTo565( minColor ) ); EmitColorIndices( block, minColor, maxColor ); } } outputBytes = globalOutData - outBuf; return true;}Appendix C
/* Real-Time YCoCg DXT Compression (MMX) Copyright (C) 2007 Id Software, Inc. Written by J.M.P. van Waveren This code is free software; you can redistribute it and/or modify it under the terms of the GNU Lesser General Public License as published by the Free Software Foundation; either version 2.1 of the License, or (at your option) any later version. This code is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU Lesser General Public License for more details.*/ #define ALIGN16( x ) __declspec(align(16)) x#define R_SHUFFLE_D( x, y, z, w ) (( (w) & 3 ) << 6 | ( (z) & 3 ) << 4 | ( (y) & 3 ) << 2 | ( (x) & 3 )) ALIGN16( static dword SIMD_MMX_dword_word_mask[2] ) = { 0x0000FFFF, 0x0000FFFF };ALIGN16( static dword SIMD_MMX_dword_alpha_bit_mask0[2] ) = { 7<<0, 0 };ALIGN16( static dword SIMD_MMX_dword_alpha_bit_mask1[2] ) = { 7<<3, 0 };ALIGN16( static dword SIMD_MMX_dword_alpha_bit_mask2[2] ) = { 7<<6, 0 };ALIGN16( static dword SIMD_MMX_dword_alpha_bit_mask3[2] ) = { 7<<9, 0 };ALIGN16( static dword SIMD_MMX_dword_alpha_bit_mask4[2] ) = { 7<<12, 0 };ALIGN16( static dword SIMD_MMX_dword_alpha_bit_mask5[2] ) = { 7<<15, 0 };ALIGN16( static dword SIMD_MMX_dword_alpha_bit_mask6[2] ) = { 7<<18, 0 };ALIGN16( static dword SIMD_MMX_dword_alpha_bit_mask7[2] ) = { 7<<21, 0 };ALIGN16( static word SIMD_MMX_word_0[4] ) = { 0x0000, 0x0000, 0x0000, 0x0000 };ALIGN16( static word SIMD_MMX_word_1[4] ) = { 0x0001, 0x0001, 0x0001, 0x0001 };ALIGN16( static word SIMD_MMX_word_2[4] ) = { 0x0002, 0x0002, 0x0002, 0x0002 };ALIGN16( static word SIMD_MMX_word_31[4] ) = { 31, 31, 31, 31 };ALIGN16( static word SIMD_MMX_word_63[4] ) = { 63, 63, 63, 63 };ALIGN16( static word SIMD_MMX_word_center_128[4] ) = { 128, 128, 0, 0 };ALIGN16( static word SIMD_MMX_word_div_by_3[4] ) = { (1<<16)/3+1, (1<<16)/3+1, (1<<16)/3+1, (1<<16)/3+1 };ALIGN16( static word SIMD_MMX_word_div_by_7[4] ) = { (1<<16)/7+1, (1<<16)/7+1, (1<<16)/7+1, (1<<16)/7+1 };ALIGN16( static word SIMD_MMX_word_div_by_14[4] ) = { (1<<16)/14+1, (1<<16)/14+1, (1<<16)/14+1, (1<<16)/14+1 };ALIGN16( static word SIMD_MMX_word_scale654[4] ) = { 6, 5, 4, 0 };ALIGN16( static word SIMD_MMX_word_scale123[4] ) = { 1, 2, 3, 0 };ALIGN16( static word SIMD_MMX_word_insetShift[4] ) = { 1 << ( 16 - INSET_COLOR_SHIFT ), 1 << ( 16 - INSET_COLOR_SHIFT ), 1 << ( 16 - INSET_COLOR_SHIFT ), 1 << ( 16 - INSET_ALPHA_SHIFT ) };ALIGN16( static word SIMD_MMX_word_insetShiftUp[4] ) = { 1 << INSET_COLOR_SHIFT, 1 << INSET_COLOR_SHIFT, 1 << INSET_COLOR_SHIFT, 1 << INSET_ALPHA_SHIFT };ALIGN16( static word SIMD_MMX_word_insetShiftDown[4] ) = { 1 << ( 16 - INSET_COLOR_SHIFT ), 1 << ( 16 - INSET_COLOR_SHIFT ), 1 << ( 16 - INSET_COLOR_SHIFT ), 1 << ( 16 - INSET_ALPHA_SHIFT ) };ALIGN16( static word SIMD_MMX_word_insetYCoCgRound[4] ) = { ((1<<(INSET_COLOR_SHIFT-1))-1), ((1<<(INSET_COLOR_SHIFT-1))-1), ((1<<(INSET_COLOR_SHIFT-1))-1), ((1<<(INSET_ALPHA_SHIFT-1))-1) };ALIGN16( static word SIMD_MMX_word_insetYCoCgMask[4] ) = { 0xFFFF, 0xFFFF, 0x0000, 0xFFFF };ALIGN16( static word SIMD_MMX_word_inset565Mask[4] ) = { C565_5_MASK, C565_6_MASK, C565_5_MASK, 0xFF };ALIGN16( static word SIMD_MMX_word_inset565Rep[4] ) = { 1 << ( 16 - 5 ), 1 << ( 16 - 6 ), 1 << ( 16 - 5 ), 0 };ALIGN16( static byte SIMD_MMX_byte_0[8] ) = { 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00 };ALIGN16( static byte SIMD_MMX_byte_1[8] ) = { 0x01, 0x01, 0x01, 0x01, 0x01, 0x01, 0x01, 0x01 };ALIGN16( static byte SIMD_MMX_byte_2[8] ) = { 0x02, 0x02, 0x02, 0x02, 0x02, 0x02, 0x02, 0x02 };ALIGN16( static byte SIMD_MMX_byte_7[8] ) = { 0x07, 0x07, 0x07, 0x07, 0x07, 0x07, 0x07, 0x07 };ALIGN16( static byte SIMD_MMX_byte_8[8] ) = { 0x08, 0x08, 0x08, 0x08, 0x08, 0x08, 0x08, 0x08 };ALIGN16( static byte SIMD_MMX_byte_not[8] ) = { 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF };ALIGN16( static byte SIMD_MMX_byte_colorMask[8] ) = { 0xFF, 0xFF, 0xFF, 0x00, 0x00, 0x00, 0x00, 0x00 };ALIGN16( static byte SIMD_MMX_byte_diagonalMask[8] ) = { 0x00, 0xFF, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00 };ALIGN16( static byte SIMD_MMX_byte_scale_mask0[8] ) = { 0x00, 0x00, 0xFF, 0xFF, 0x00, 0x00, 0xFF, 0xFF };ALIGN16( static byte SIMD_MMX_byte_scale_mask1[8] ) = { 0xFF, 0x00, 0x00, 0x00, 0xFF, 0x00, 0x00, 0x00 };ALIGN16( static byte SIMD_MMX_byte_scale_mask2[8] ) = { 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x01, 0x00 };ALIGN16( static byte SIMD_MMX_byte_scale_mask3[8] ) = { 0xFF, 0xFF, 0x00, 0xFF, 0x00, 0x00, 0x00, 0x00 };ALIGN16( static byte SIMD_MMX_byte_scale_mask4[8] ) = { 0x00, 0x00, 0xFF, 0x00, 0x00, 0x00, 0x00, 0x00 };ALIGN16( static byte SIMD_MMX_byte_minus_128_0[8] ) = { -128, -128, 0, 0, -128, -128, 0, 0 }; void ExtractBlock_MMX( const byte *inPtr, int width, byte *colorBlock ) { __asm { mov esi, inPtr mov edi, colorBlock mov eax, width shl eax, 2 movq mm0, qword ptr [esi+0] movq qword ptr [edi+ 0], mm0 movq mm1, qword ptr [esi+8] movq qword ptr [edi+ 8], mm1 movq mm2, qword ptr [esi+eax+0] movq qword ptr [edi+16], mm2 movq mm3, qword ptr [esi+eax+8] movq qword ptr [edi+24], mm3 movq mm4, qword ptr [esi+eax*2+0] movq qword ptr [edi+32], mm4 movq mm5, qword ptr [esi+eax*2+8] add esi, eax movq qword ptr [edi+40], mm5 movq mm6, qword ptr [esi+eax*2+0] movq qword ptr [edi+48], mm6 movq mm7, qword ptr [esi+eax*2+8] movq qword ptr [edi+56], mm7 emms }} void GetMinMaxYCoCg_MMX( const byte *colorBlock, byte *minColor, byte *maxColor ) { __asm { mov eax, colorBlock mov esi, minColor mov edi, maxColor pshufw mm0, qword ptr [eax+ 0], R_SHUFFLE_D( 0, 1, 2, 3 ) pshufw mm1, qword ptr [eax+ 0], R_SHUFFLE_D( 0, 1, 2, 3 ) pminub mm0, qword ptr [eax+ 8] pmaxub mm1, qword ptr [eax+ 8] pminub mm0, qword ptr [eax+16] pmaxub mm1, qword ptr [eax+16] pminub mm0, qword ptr [eax+24] pmaxub mm1, qword ptr [eax+24] pminub mm0, qword ptr [eax+32] pmaxub mm1, qword ptr [eax+32] pminub mm0, qword ptr [eax+40] pmaxub mm1, qword ptr [eax+40] pminub mm0, qword ptr [eax+48] pmaxub mm1, qword ptr [eax+48] pminub mm0, qword ptr [eax+56] pmaxub mm1, qword ptr [eax+56] pshufw mm6, mm0, R_SHUFFLE_D( 2, 3, 2, 3 ) pshufw mm7, mm1, R_SHUFFLE_D( 2, 3, 2, 3 ) pminub mm0, mm6 pmaxub mm1, mm7 movd dword ptr [esi], mm0 movd dword ptr [edi], mm1 emms }} void ScaleYCoCg_MMX( byte *colorBlock, byte *minColor, byte *maxColor ) { __asm { mov esi, colorBlock mov edx, minColor mov ecx, maxColor movd mm0, dword ptr [edx] movd mm1, dword ptr [ecx] punpcklbw mm0, SIMD_MMX_byte_0 punpcklbw mm1, SIMD_MMX_byte_0 movq mm6, SIMD_MMX_word_center_128 movq mm7, SIMD_MMX_word_center_128 psubw mm6, mm0 psubw mm7, mm1 psubw mm0, SIMD_MMX_word_center_128 psubw mm1, SIMD_MMX_word_center_128 pmaxsw mm6, mm0 pmaxsw mm7, mm1 pmaxsw mm6, mm7 pshufw mm7, mm6, R_SHUFFLE_D( 1, 0, 1, 0 ) pmaxsw mm6, mm7 pshufw mm6, mm6, R_SHUFFLE_D( 0, 1, 0, 1 ) movq mm7, mm6 pcmpgtw mm6, SIMD_MMX_word_63 pcmpgtw mm7, SIMD_MMX_word_32 pandn mm7, SIMD_MMX_byte_2 por mm7, SIMD_MMX_byte_1 pandn mm6, mm7 movq mm3, mm6 movq mm7, mm6 pxor mm7, SIMD_MMX_byte_not por mm7, SIMD_MMX_byte_scale_mask0 paddw mm6, SIMD_MMX_byte_1 pand mm6, SIMD_MMX_byte_scale_mask1 por mm6, SIMD_MMX_byte_scale_mask2 movd mm4, dword ptr [edx] movd mm5, dword ptr [ecx] pand mm4, SIMD_MMX_byte_scale_mask3 pand mm5, SIMD_MMX_byte_scale_mask3 pslld mm3, 3 pand mm3, SIMD_MMX_byte_scale_mask4 por mm4, mm3 por mm5, mm3 paddb mm4, SIMD_MMX_byte_minus_128_0 paddb mm5, SIMD_MMX_byte_minus_128_0 pmullw mm4, mm6 pmullw mm5, mm6 pand mm4, mm7 pand mm5, mm7 psubb mm4, SIMD_MMX_byte_minus_128_0 psubb mm5, SIMD_MMX_byte_minus_128_0 movd dword ptr [edx], mm4 movd dword ptr [ecx], mm5 movq mm0, qword ptr [esi+ 0*4] movq mm1, qword ptr [esi+ 2*4] movq mm2, qword ptr [esi+ 4*4] movq mm3, qword ptr [esi+ 6*4] paddb mm0, SIMD_MMX_byte_minus_128_0 paddb mm1, SIMD_MMX_byte_minus_128_0 paddb mm2, SIMD_MMX_byte_minus_128_0 paddb mm3, SIMD_MMX_byte_minus_128_0 pmullw mm0, mm6 pmullw mm1, mm6 pmullw mm2, mm6 pmullw mm3, mm6 pand mm0, mm7 pand mm1, mm7 pand mm2, mm7 pand mm3, mm7 psubb mm0, SIMD_MMX_byte_minus_128_0 psubb mm1, SIMD_MMX_byte_minus_128_0 psubb mm2, SIMD_MMX_byte_minus_128_0 psubb mm3, SIMD_MMX_byte_minus_128_0 movq qword ptr [esi+ 0*4], mm0 movq qword ptr [esi+ 2*4], mm1 movq qword ptr [esi+ 4*4], mm2 movq qword ptr [esi+ 6*4], mm3 movq mm0, qword ptr [esi+ 8*4] movq mm1, qword ptr [esi+10*4] movq mm2, qword ptr [esi+12*4] movq mm3, qword ptr [esi+14*4] paddb mm0, SIMD_MMX_byte_minus_128_0 paddb mm1, SIMD_MMX_byte_minus_128_0 paddb mm2, SIMD_MMX_byte_minus_128_0 paddb mm3, SIMD_MMX_byte_minus_128_0 pmullw mm0, mm6 pmullw mm1, mm6 pmullw mm2, mm6 pmullw mm3, mm6 pand mm0, mm7 pand mm1, mm7 pand mm2, mm7 pand mm3, mm7 psubb mm0, SIMD_MMX_byte_minus_128_0 psubb mm1, SIMD_MMX_byte_minus_128_0 psubb mm2, SIMD_MMX_byte_minus_128_0 psubb mm3, SIMD_MMX_byte_minus_128_0 movq qword ptr [esi+ 8*4], mm0 movq qword ptr [esi+10*4], mm1 movq qword ptr [esi+12*4], mm2 movq qword ptr [esi+14*4], mm3 emms }} void InsetYCoCgBBox_MMX( byte *minColor, byte *maxColor ) { __asm { mov esi, minColor mov edi, maxColor movd mm0, dword ptr [esi] movd mm1, dword ptr [edi] punpcklbw mm0, SIMD_MMX_byte_0 punpcklbw mm1, SIMD_MMX_byte_0 movq mm2, mm1 psubw mm2, mm0 psubw mm2, SIMD_MMX_word_insetYCoCgRound pand mm2, SIMD_MMX_word_insetYCoCgMask pmullw mm0, SIMD_MMX_word_insetShiftUp pmullw mm1, SIMD_MMX_word_insetShiftUp paddw mm0, mm2 psubw mm1, mm2 pmulhw mm0, SIMD_MMX_word_insetShiftDown pmulhw mm1, SIMD_MMX_word_insetShiftDown pmaxsw mm0, SIMD_MMX_word_0 pmaxsw mm1, SIMD_MMX_word_0 pand mm0, SIMD_MMX_word_inset565Mask pand mm1, SIMD_MMX_word_inset565Mask movq mm2, mm0 movq mm3, mm1 pmulhw mm2, SIMD_MMX_word_inset565Rep pmulhw mm3, SIMD_MMX_word_inset565Rep por mm0, mm2 por mm1, mm3 packuswb mm0, mm0 packuswb mm1, mm1 movd dword ptr [esi], mm0 movd dword ptr [edi], mm1 emms }} void SelectYCoCgDiagonal_MMX( const byte *colorBlock, byte *minColor, byte *maxColor ) { __asm { mov esi, colorBlock mov edx, minColor mov ecx, maxColor movq mm0, qword ptr [esi+ 0] movq mm2, qword ptr [esi+ 8] movq mm1, qword ptr [esi+16] movq mm3, qword ptr [esi+24] pand mm0, SIMD_MMX_dword_word_mask pand mm2, SIMD_MMX_dword_word_mask pand mm1, SIMD_MMX_dword_word_mask pand mm3, SIMD_MMX_dword_word_mask psllq mm0, 16 psllq mm3, 16 por mm0, mm2 por mm1, mm3 movq mm2, qword ptr [esi+32] movq mm4, qword ptr [esi+40] movq mm3, qword ptr [esi+48] movq mm5, qword ptr [esi+56] pand mm2, SIMD_MMX_dword_word_mask pand mm4, SIMD_MMX_dword_word_mask pand mm3, SIMD_MMX_dword_word_mask pand mm5, SIMD_MMX_dword_word_mask psllq mm2, 16 psllq mm5, 16 por mm2, mm4 por mm3, mm5 movd mm4, dword ptr [edx] movd mm5, dword ptr [ecx] pavgb mm4, mm5 pshufw mm4, mm4, R_SHUFFLE_D( 0, 0, 0, 0 ) movq mm5, mm4 movq mm6, mm4 movq mm7, mm4 pmaxub mm4, mm0 pmaxub mm5, mm1 pmaxub mm6, mm2 pmaxub mm7, mm3 pcmpeqb mm4, mm0 pcmpeqb mm5, mm1 pcmpeqb mm6, mm2 pcmpeqb mm7, mm3 movq mm0, mm4 movq mm1, mm5 movq mm2, mm6 movq mm3, mm7 psrlq mm0, 8 psrlq mm1, 8 psrlq mm2, 8 psrlq mm3, 8 pxor mm0, mm4 pxor mm1, mm5 pxor mm2, mm6 pxor mm3, mm7 pand mm0, SIMD_MMX_word_1 pand mm1, SIMD_MMX_word_1 pand mm2, SIMD_MMX_word_1 pand mm3, SIMD_MMX_word_1 paddw mm0, mm3 paddw mm1, mm2 movd mm6, dword ptr [edx] movd mm7, dword ptr [ecx] #ifdef NVIDIA_7X_HARDWARE_BUG_FIX paddw mm1, mm0 psadbw mm1, SIMD_MMX_byte_0 pcmpgtw mm1, SIMD_MMX_word_8 pand mm1, SIMD_MMX_byte_diagonalMask movq mm0, mm6 pcmpeqb mm0, mm7 psllq mm0, 8 pandn mm0, mm1#else paddw mm0, mm1 psadbw mm0, SIMD_MMX_byte_0 pcmpgtw mm0, SIMD_MMX_word_8 pand mm0, SIMD_MMX_byte_diagonalMask#endif pxor mm6, mm7 pand mm0, mm6 pxor mm7, mm0 pxor mm6, mm7 movd dword ptr [edx], mm6 movd dword ptr [ecx], mm7 emms }} void EmitAlphaIndices_MMX( const byte *colorBlock, const byte minAlpha, const byte maxAlpha ) { ALIGN16( byte alphaBlock[16] ); ALIGN16( byte ab1[8] ); ALIGN16( byte ab2[8] ); ALIGN16( byte ab3[8] ); ALIGN16( byte ab4[8] ); ALIGN16( byte ab5[8] ); ALIGN16( byte ab6[8] ); ALIGN16( byte ab7[8] ); __asm { mov esi, colorBlock movq mm0, qword ptr [esi+ 0] movq mm5, qword ptr [esi+ 8] psrld mm0, 24 psrld mm5, 24 packuswb mm0, mm5 movq mm6, qword ptr [esi+16] movq mm4, qword ptr [esi+24] psrld mm6, 24 psrld mm4, 24 packuswb mm6, mm4 packuswb mm0, mm6 movq alphaBlock+0, mm0 movq mm0, qword ptr [esi+32] movq mm5, qword ptr [esi+40] psrld mm0, 24 psrld mm5, 24 packuswb mm0, mm5 movq mm6, qword ptr [esi+48] movq mm4, qword ptr [esi+56] psrld mm6, 24 psrld mm4, 24 packuswb mm6, mm4 packuswb mm0, mm6 movq alphaBlock+8, mm0 movzx ecx, maxAlpha movd mm0, ecx pshufw mm0, mm0, R_SHUFFLE_D( 0, 0, 0, 0 ) movq mm1, mm0 movzx edx, minAlpha movd mm2, edx pshufw mm2, mm2, R_SHUFFLE_D( 0, 0, 0, 0 ) movq mm3, mm2 movq mm4, mm0 psubw mm4, mm2 pmulhw mm4, SIMD_MMX_word_div_by_14 movq mm5, mm2 paddw mm5, mm4 packuswb mm5, mm5 movq ab1, mm5 pmullw mm0, SIMD_MMX_word_scale654 pmullw mm1, SIMD_MMX_word_scale123 pmullw mm2, SIMD_MMX_word_scale123 pmullw mm3, SIMD_MMX_word_scale654 paddw mm0, mm2 paddw mm1, mm3 pmulhw mm0, SIMD_MMX_word_div_by_7 pmulhw mm1, SIMD_MMX_word_div_by_7 paddw mm0, mm4 paddw mm1, mm4 pshufw mm2, mm0, R_SHUFFLE_D( 0, 0, 0, 0 ) pshufw mm3, mm0, R_SHUFFLE_D( 1, 1, 1, 1 ) pshufw mm4, mm0, R_SHUFFLE_D( 2, 2, 2, 2 ) packuswb mm2, mm2 packuswb mm3, mm3 packuswb mm4, mm4 movq ab2, mm2 movq ab3, mm3 movq ab4, mm4 pshufw mm2, mm1, R_SHUFFLE_D( 2, 2, 2, 2 ) pshufw mm3, mm1, R_SHUFFLE_D( 1, 1, 1, 1 ) pshufw mm4, mm1, R_SHUFFLE_D( 0, 0, 0, 0 ) packuswb mm2, mm2 packuswb mm3, mm3 packuswb mm4, mm4 movq ab5, mm2 movq ab6, mm3 movq ab7, mm4 pshufw mm0, alphaBlock+0, R_SHUFFLE_D( 0, 1, 2, 3 ) pshufw mm1, mm0, R_SHUFFLE_D( 0, 1, 2, 3 ) pshufw mm2, mm0, R_SHUFFLE_D( 0, 1, 2, 3 ) pshufw mm3, mm0, R_SHUFFLE_D( 0, 1, 2, 3 ) pshufw mm4, mm0, R_SHUFFLE_D( 0, 1, 2, 3 ) pshufw mm5, mm0, R_SHUFFLE_D( 0, 1, 2, 3 ) pshufw mm6, mm0, R_SHUFFLE_D( 0, 1, 2, 3 ) pshufw mm7, mm0, R_SHUFFLE_D( 0, 1, 2, 3 ) pminub mm1, ab1 pminub mm2, ab2 pminub mm3, ab3 pminub mm4, ab4 pminub mm5, ab5 pminub mm6, ab6 pminub mm7, ab7 pcmpeqb mm1, mm0 pcmpeqb mm2, mm0 pcmpeqb mm3, mm0 pcmpeqb mm4, mm0 pcmpeqb mm5, mm0 pcmpeqb mm6, mm0 pcmpeqb mm7, mm0 pand mm1, SIMD_MMX_byte_1 pand mm2, SIMD_MMX_byte_1 pand mm3, SIMD_MMX_byte_1 pand mm4, SIMD_MMX_byte_1 pand mm5, SIMD_MMX_byte_1 pand mm6, SIMD_MMX_byte_1 pand mm7, SIMD_MMX_byte_1 pshufw mm0, SIMD_MMX_byte_1, R_SHUFFLE_D( 0, 1, 2, 3 ) paddusb mm0, mm1 paddusb mm0, mm2 paddusb mm0, mm3 paddusb mm0, mm4 paddusb mm0, mm5 paddusb mm0, mm6 paddusb mm0, mm7 pand mm0, SIMD_MMX_byte_7 pshufw mm1, SIMD_MMX_byte_2, R_SHUFFLE_D( 0, 1, 2, 3 ) pcmpgtb mm1, mm0 pand mm1, SIMD_MMX_byte_1 pxor mm0, mm1 pshufw mm1, mm0, R_SHUFFLE_D( 0, 1, 2, 3 ) pshufw mm2, mm0, R_SHUFFLE_D( 0, 1, 2, 3 ) pshufw mm3, mm0, R_SHUFFLE_D( 0, 1, 2, 3 ) psrlq mm1, 8- 3 psrlq mm2, 16- 6 psrlq mm3, 24- 9 pshufw mm4, mm0, R_SHUFFLE_D( 0, 1, 2, 3 ) pshufw mm5, mm0, R_SHUFFLE_D( 0, 1, 2, 3 ) pshufw mm6, mm0, R_SHUFFLE_D( 0, 1, 2, 3 ) pshufw mm7, mm0, R_SHUFFLE_D( 0, 1, 2, 3 ) psrlq mm4, 32-12 psrlq mm5, 40-15 psrlq mm6, 48-18 psrlq mm7, 56-21 pand mm0, SIMD_MMX_dword_alpha_bit_mask0 pand mm1, SIMD_MMX_dword_alpha_bit_mask1 pand mm2, SIMD_MMX_dword_alpha_bit_mask2 pand mm3, SIMD_MMX_dword_alpha_bit_mask3 pand mm4, SIMD_MMX_dword_alpha_bit_mask4 pand mm5, SIMD_MMX_dword_alpha_bit_mask5 pand mm6, SIMD_MMX_dword_alpha_bit_mask6 pand mm7, SIMD_MMX_dword_alpha_bit_mask7 por mm0, mm1 por mm2, mm3 por mm4, mm5 por mm6, mm7 por mm0, mm2 por mm4, mm6 por mm0, mm4 mov esi, globalOutData movd dword ptr [esi+0], mm0 pshufw mm0, alphaBlock+8, R_SHUFFLE_D( 0, 1, 2, 3 ) pshufw mm1, mm0, R_SHUFFLE_D( 0, 1, 2, 3 ) pshufw mm2, mm0, R_SHUFFLE_D( 0, 1, 2, 3 ) pshufw mm3, mm0, R_SHUFFLE_D( 0, 1, 2, 3 ) pshufw mm4, mm0, R_SHUFFLE_D( 0, 1, 2, 3 ) pshufw mm5, mm0, R_SHUFFLE_D( 0, 1, 2, 3 ) pshufw mm6, mm0, R_SHUFFLE_D( 0, 1, 2, 3 ) pshufw mm7, mm0, R_SHUFFLE_D( 0, 1, 2, 3 ) pminub mm1, ab1 pminub mm2, ab2 pminub mm3, ab3 pminub mm4, ab4 pminub mm5, ab5 pminub mm6, ab6 pminub mm7, ab7 pcmpeqb mm1, mm0 pcmpeqb mm2, mm0 pcmpeqb mm3, mm0 pcmpeqb mm4, mm0 pcmpeqb mm5, mm0 pcmpeqb mm6, mm0 pcmpeqb mm7, mm0 pand mm1, SIMD_MMX_byte_1 pand mm2, SIMD_MMX_byte_1 pand mm3, SIMD_MMX_byte_1 pand mm4, SIMD_MMX_byte_1 pand mm5, SIMD_MMX_byte_1 pand mm6, SIMD_MMX_byte_1 pand mm7, SIMD_MMX_byte_1 pshufw mm0, SIMD_MMX_byte_1, R_SHUFFLE_D( 0, 1, 2, 3 ) paddusb mm0, mm1 paddusb mm0, mm2 paddusb mm0, mm3 paddusb mm0, mm4 paddusb mm0, mm5 paddusb mm0, mm6 paddusb mm0, mm7 pand mm0, SIMD_MMX_byte_7 pshufw mm1, SIMD_MMX_byte_2, R_SHUFFLE_D( 0, 1, 2, 3 ) pcmpgtb mm1, mm0 pand mm1, SIMD_MMX_byte_1 pxor mm0, mm1 pshufw mm1, mm0, R_SHUFFLE_D( 0, 1, 2, 3 ) pshufw mm2, mm0, R_SHUFFLE_D( 0, 1, 2, 3 ) pshufw mm3, mm0, R_SHUFFLE_D( 0, 1, 2, 3 ) psrlq mm1, 8- 3 psrlq mm2, 16- 6 psrlq mm3, 24- 9 pshufw mm4, mm0, R_SHUFFLE_D( 0, 1, 2, 3 ) pshufw mm5, mm0, R_SHUFFLE_D( 0, 1, 2, 3 ) pshufw mm6, mm0, R_SHUFFLE_D( 0, 1, 2, 3 ) pshufw mm7, mm0, R_SHUFFLE_D( 0, 1, 2, 3 ) psrlq mm4, 32-12 psrlq mm5, 40-15 psrlq mm6, 48-18 psrlq mm7, 56-21 pand mm0, SIMD_MMX_dword_alpha_bit_mask0 pand mm1, SIMD_MMX_dword_alpha_bit_mask1 pand mm2, SIMD_MMX_dword_alpha_bit_mask2 pand mm3, SIMD_MMX_dword_alpha_bit_mask3 pand mm4, SIMD_MMX_dword_alpha_bit_mask4 pand mm5, SIMD_MMX_dword_alpha_bit_mask5 pand mm6, SIMD_MMX_dword_alpha_bit_mask6 pand mm7, SIMD_MMX_dword_alpha_bit_mask7 por mm0, mm1 por mm2, mm3 por mm4, mm5 por mm6, mm7 por mm0, mm2 por mm4, mm6 por mm0, mm4 movd dword ptr [esi+3], mm0 emms } globalOutData += 6;} void EmitColorIndices_MMX( const byte *colorBlock, const byte *minColor, const byte *maxColor ) { ALIGN16( byte color0[8] ); ALIGN16( byte color1[8] ); ALIGN16( byte color2[8] ); ALIGN16( byte color3[8] ); ALIGN16( byte result[8] ); __asm { mov esi, maxColor mov edi, minColor pxor mm7, mm7 movq result, mm7 movd mm0, dword ptr [esi] pand mm0, SIMD_MMX_byte_colorMask movq color0, mm0 movd mm1, dword ptr [edi] pand mm1, SIMD_MMX_byte_colorMask movq color1, mm1 punpcklbw mm0, mm7 punpcklbw mm1, mm7 movq mm6, mm1 paddw mm1, mm0 paddw mm0, mm1 pmulhw mm0, SIMD_MMX_word_div_by_3 packuswb mm0, mm7 movq color2, mm0 paddw mm1, mm6 pmulhw mm1, SIMD_MMX_word_div_by_3 packuswb mm1, mm7 movq color3, mm1 mov eax, 48 mov esi, colorBlock loop1: // iterates 4 times movd mm3, dword ptr [esi+eax+0] movd mm5, dword ptr [esi+eax+4] movq mm0, mm3 movq mm6, mm5 psadbw mm0, color0 psadbw mm6, color0 packssdw mm0, mm6 movq mm1, mm3 movq mm6, mm5 psadbw mm1, color1 psadbw mm6, color1 packssdw mm1, mm6 movq mm2, mm3 movq mm6, mm5 psadbw mm2, color2 psadbw mm6, color2 packssdw mm2, mm6 psadbw mm3, color3 psadbw mm5, color3 packssdw mm3, mm5 movd mm4, dword ptr [esi+eax+8] movd mm5, dword ptr [esi+eax+12] movq mm6, mm4 movq mm7, mm5 psadbw mm6, color0 psadbw mm7, color0 packssdw mm6, mm7 packssdw mm0, mm6 movq mm6, mm4 movq mm7, mm5 psadbw mm6, color1 psadbw mm7, color1 packssdw mm6, mm7 packssdw mm1, mm6 movq mm6, mm4 movq mm7, mm5 psadbw mm6, color2 psadbw mm7, color2 packssdw mm6, mm7 packssdw mm2, mm6 psadbw mm4, color3 psadbw mm5, color3 packssdw mm4, mm5 packssdw mm3, mm4 movq mm7, result pslld mm7, 8 movq mm4, mm0 movq mm5, mm1 pcmpgtw mm0, mm3 pcmpgtw mm1, mm2 pcmpgtw mm4, mm2 pcmpgtw mm5, mm3 pcmpgtw mm2, mm3 pand mm4, mm1 pand mm5, mm0 pand mm2, mm0 por mm4, mm5 pand mm2, SIMD_MMX_word_1 pand mm4, SIMD_MMX_word_2 por mm2, mm4 pshufw mm5, mm2, R_SHUFFLE_D( 2, 3, 0, 1 ) punpcklwd mm2, SIMD_MMX_word_0 punpcklwd mm5, SIMD_MMX_word_0 pslld mm5, 4 por mm7, mm5 por mm7, mm2 movq result, mm7 sub eax, 16 jge loop1 mov esi, globalOutData movq mm6, mm7 psrlq mm6, 32-2 por mm7, mm6 movd dword ptr [esi], mm7 emms } globalOutData += 4;} bool CompressYCoCgDXT5_MMX( const byte *inBuf, byte *outBuf, int width, int height, int &outputBytes ) { ALIGN16( byte block[64] ); ALIGN16( byte minColor[4] ); ALIGN16( byte maxColor[4] ); globalOutData = outBuf; for ( int j = 0; j < height; j += 4, inBuf += width * 4*4 ) { for ( int i = 0; i < width; i += 4 ) { ExtractBlock_MMX( inBuf + i * 4, width, block ); GetMinMaxYCoCg_MMX( block, minColor, maxColor ); ScaleYCoCg_MMX( block, minColor, maxColor ); InsetYCoCgBBox_MMX( minColor, maxColor ); SelectYCoCgDiagonal_MMX( block, minColor, maxColor ); EmitByte( maxColor[3] ); EmitByte( minColor[3] ); EmitAlphaIndices_MMX( block, minColor[3], maxColor[3] ); EmitUShort( ColorTo565( maxColor ) ); EmitUShort( ColorTo565( minColor ) ); EmitColorIndices_MMX( block, minColor, maxColor ); } } outputBytes = globalOutData - outBuf; return true;}Appendix D
/* Real-Time YCoCg DXT Compression (SSE2) Copyright (C) 2007 Id Software, Inc. Written by J.M.P. van Waveren This code is free software; you can redistribute it and/or modify it under the terms of the GNU Lesser General Public License as published by the Free Software Foundation; either version 2.1 of the License, or (at your option) any later version. This code is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU Lesser General Public License for more details.*/ #define ALIGN16( x ) __declspec(align(16)) x#define R_SHUFFLE_D( x, y, z, w ) (( (w) & 3 ) << 6 | ( (z) & 3 ) << 4 | ( (y) & 3 ) << 2 | ( (x) & 3 )) ALIGN16( static dword SIMD_SSE2_dword_alpha_bit_mask0[4] ) = { 7<<0, 0, 7<<0, 0 };ALIGN16( static dword SIMD_SSE2_dword_alpha_bit_mask1[4] ) = { 7<<3, 0, 7<<3, 0 };ALIGN16( static dword SIMD_SSE2_dword_alpha_bit_mask2[4] ) = { 7<<6, 0, 7<<6, 0 };ALIGN16( static dword SIMD_SSE2_dword_alpha_bit_mask3[4] ) = { 7<<9, 0, 7<<9, 0 };ALIGN16( static dword SIMD_SSE2_dword_alpha_bit_mask4[4] ) = { 7<<12, 0, 7<<12, 0 };ALIGN16( static dword SIMD_SSE2_dword_alpha_bit_mask5[4] ) = { 7<<15, 0, 7<<15, 0 };ALIGN16( static dword SIMD_SSE2_dword_alpha_bit_mask6[4] ) = { 7<<18, 0, 7<<18, 0 };ALIGN16( static dword SIMD_SSE2_dword_alpha_bit_mask7[4] ) = { 7<<21, 0, 7<<21, 0 };ALIGN16( static word SIMD_SSE2_word_0[8] ) = { 0x0000, 0x0000, 0x0000, 0x0000, 0x0000, 0x0000, 0x0000, 0x0000 };ALIGN16( static word SIMD_SSE2_word_1[8] ) = { 0x0001, 0x0001, 0x0001, 0x0001, 0x0001, 0x0001, 0x0001, 0x0001 };ALIGN16( static word SIMD_SSE2_word_2[8] ) = { 0x0002, 0x0002, 0x0002, 0x0002, 0x0002, 0x0002, 0x0002, 0x0002 };ALIGN16( static word SIMD_SSE2_word_31[8] ) = { 31, 31, 31, 31, 31, 31, 31, 31 };ALIGN16( static word SIMD_SSE2_word_63[8] ) = { 63, 63, 63, 63, 63, 63, 63, 63 };ALIGN16( static word SIMD_SSE2_word_center_128[8] ) = { 128, 128, 0, 0, 0, 0, 0, 0 };ALIGN16( static word SIMD_SSE2_word_div_by_3[8] ) = { (1<<16)/3+1, (1<<16)/3+1, (1<<16)/3+1, (1<<16)/3+1, (1<<16)/3+1, (1<<16)/3+1, (1<<16)/3+1, (1<<16)/3+1 };ALIGN16( static word SIMD_SSE2_word_div_by_7[8] ) = { (1<<16)/7+1, (1<<16)/7+1, (1<<16)/7+1, (1<<16)/7+1, (1<<16)/7+1, (1<<16)/7+1, (1<<16)/7+1, (1<<16)/7+1 };ALIGN16( static word SIMD_SSE2_word_div_by_14[8] ) = { (1<<16)/14+1, (1<<16)/14+1, (1<<16)/14+1, (1<<16)/14+1, (1<<16)/14+1, (1<<16)/14+1, (1<<16)/14+1, (1<<16)/14+1 };ALIGN16( static word SIMD_SSE2_word_scale66554400[8] ) = { 6, 6, 5, 5, 4, 4, 0, 0 };ALIGN16( static word SIMD_SSE2_word_scale11223300[8] ) = { 1, 1, 2, 2, 3, 3, 0, 0 };ALIGN16( static word SIMD_SSE2_word_insetShiftUp[8] ) = { 1 << INSET_COLOR_SHIFT, 1 << INSET_COLOR_SHIFT, 1 << INSET_COLOR_SHIFT, 1 << INSET_ALPHA_SHIFT, 0, 0, 0, 0 };ALIGN16( static word SIMD_SSE2_word_insetShiftDown[8] ) = { 1 << ( 16 - INSET_COLOR_SHIFT ), 1 << ( 16 - INSET_COLOR_SHIFT ), 1 << ( 16 - INSET_COLOR_SHIFT ), 1 << ( 16 - INSET_ALPHA_SHIFT ), 0, 0, 0, 0 };ALIGN16( static word SIMD_SSE2_word_insetYCoCgRound[8] ) = { ((1<<(INSET_COLOR_SHIFT-1))-1), ((1<<(INSET_COLOR_SHIFT-1))-1), ((1<<(INSET_COLOR_SHIFT-1))-1), ((1<<(INSET_ALPHA_SHIFT-1))-1), 0, 0, 0, 0 };ALIGN16( static word SIMD_SSE2_word_insetYCoCgMask[8] ) = { 0xFFFF, 0xFFFF, 0x0000, 0xFFFF, 0xFFFF, 0xFFFF, 0x0000, 0xFFFF };ALIGN16( static word SIMD_SSE2_word_inset565Mask[8] ) = { C565_5_MASK, C565_6_MASK, C565_5_MASK, 0xFF, C565_5_MASK, C565_6_MASK, C565_5_MASK, 0xFF };ALIGN16( static word SIMD_SSE2_word_inset565Rep[8] ) = { 1 << ( 16 - 5 ), 1 << ( 16 - 6 ), 1 << ( 16 - 5 ), 0, 1 << ( 16 - 5 ), 1 << ( 16 - 6 ), 1 << ( 16 - 5 ), 0 };ALIGN16( static byte SIMD_SSE2_byte_0[16] ) = { 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00 };ALIGN16( static byte SIMD_SSE2_byte_1[16] ) = { 0x01, 0x01, 0x01, 0x01, 0x01, 0x01, 0x01, 0x01, 0x01, 0x01, 0x01, 0x01, 0x01, 0x01, 0x01, 0x01 };ALIGN16( static byte SIMD_SSE2_byte_2[16] ) = { 0x02, 0x02, 0x02, 0x02, 0x02, 0x02, 0x02, 0x02, 0x02, 0x02, 0x02, 0x02, 0x02, 0x02, 0x02, 0x02 };ALIGN16( static byte SIMD_SSE2_byte_7[16] ) = { 0x07, 0x07, 0x07, 0x07, 0x07, 0x07, 0x07, 0x07, 0x07, 0x07, 0x07, 0x07, 0x07, 0x07, 0x07, 0x07 };ALIGN16( static byte SIMD_SSE2_byte_8[16] ) = { 0x08, 0x08, 0x08, 0x08, 0x08, 0x08, 0x08, 0x08, 0x08, 0x08, 0x08, 0x08, 0x08, 0x08, 0x08, 0x08 };ALIGN16( static byte SIMD_SSE2_byte_colorMask[16] ) = { 0xFF, 0xFF, 0xFF, 0x00, 0x00, 0x00, 0x00, 0x00, 0xFF, 0xFF, 0xFF, 0x00, 0x00, 0x00, 0x00, 0x00 };ALIGN16( static byte SIMD_SSE2_byte_diagonalMask[16] ) = { 0x00, 0xFF, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00 };ALIGN16( static byte SIMD_SSE2_byte_scale_mask0[16] ) = { 0x00, 0x00, 0xFF, 0xFF, 0x00, 0x00, 0xFF, 0xFF, 0x00, 0x00, 0xFF, 0xFF, 0x00, 0x00, 0xFF, 0xFF };ALIGN16( static byte SIMD_SSE2_byte_scale_mask1[16] ) = { 0xFF, 0x00, 0x00, 0x00, 0xFF, 0x00, 0x00, 0x00, 0xFF, 0x00, 0x00, 0x00, 0xFF, 0x00, 0x00, 0x00 };ALIGN16( static byte SIMD_SSE2_byte_scale_mask2[16] ) = { 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x01, 0x00 };ALIGN16( static byte SIMD_SSE2_byte_scale_mask3[16] ) = { 0xFF, 0xFF, 0x00, 0xFF, 0x00, 0x00, 0x00, 0x00, 0xFF, 0xFF, 0x00, 0xFF, 0x00, 0x00, 0x00, 0x00 };ALIGN16( static byte SIMD_SSE2_byte_scale_mask4[16] ) = { 0x00, 0x00, 0xFF, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0xFF, 0x00, 0x00, 0x00, 0x00, 0x00 };ALIGN16( static byte SIMD_SSE2_byte_minus_128_0[16] ) = { -128, -128, 0, 0, -128, -128, 0, 0, -128, -128, 0, 0, -128, -128, 0, 0 }; void ExtractBlock_SSE2( const byte *inPtr, int width, byte *colorBlock ) { __asm { mov esi, inPtr mov edi, colorBlock mov eax, width shl eax, 2 movdqa xmm0, [esi] movdqa xmmword ptr [edi+ 0], xmm0 movdqa xmm1, xmmword ptr [esi+eax] movdqa xmmword ptr [edi+16], xmm1 movdqa xmm2, xmmword ptr [esi+eax*2] add esi, eax movdqa xmmword ptr [edi+32], xmm2 movdqa xmm3, xmmword ptr [esi+eax*2] movdqa xmmword ptr [edi+48], xmm3 }} void GetMinMaxYCoCg_SSE2( const byte *colorBlock, byte *minColor, byte *maxColor ) { __asm { mov eax, colorBlock mov esi, minColor mov edi, maxColor movdqa xmm0, xmmword ptr [eax+ 0] movdqa xmm1, xmmword ptr [eax+ 0] pminub xmm0, xmmword ptr [eax+16] pmaxub xmm1, xmmword ptr [eax+16] pminub xmm0, xmmword ptr [eax+32] pmaxub xmm1, xmmword ptr [eax+32] pminub xmm0, xmmword ptr [eax+48] pmaxub xmm1, xmmword ptr [eax+48] pshufd xmm3, xmm0, R_SHUFFLE_D( 2, 3, 2, 3 ) pshufd xmm4, xmm1, R_SHUFFLE_D( 2, 3, 2, 3 ) pminub xmm0, xmm3 pmaxub xmm1, xmm4 pshuflw xmm6, xmm0, R_SHUFFLE_D( 2, 3, 2, 3 ) pshuflw xmm7, xmm1, R_SHUFFLE_D( 2, 3, 2, 3 ) pminub xmm0, xmm6 pmaxub xmm1, xmm7 movd dword ptr [esi], xmm0 movd dword ptr [edi], xmm1 }} void ScaleYCoCg_SSE2( byte *colorBlock, byte *minColor, byte *maxColor ) { __asm { mov esi, colorBlock mov edx, minColor mov ecx, maxColor movd xmm0, dword ptr [edx] movd xmm1, dword ptr [ecx] punpcklbw xmm0, SIMD_SSE2_byte_0 punpcklbw xmm1, SIMD_SSE2_byte_0 movdqa xmm6, SIMD_SSE2_word_center_128 movdqa xmm7, SIMD_SSE2_word_center_128 psubw xmm6, xmm0 psubw xmm7, xmm1 psubw xmm0, SIMD_SSE2_word_center_128 psubw xmm1, SIMD_SSE2_word_center_128 pmaxsw xmm6, xmm0 pmaxsw xmm7, xmm1 pmaxsw xmm6, xmm7 pshuflw xmm7, xmm6, R_SHUFFLE_D( 1, 0, 1, 0 ) pmaxsw xmm6, xmm7 pshufd xmm6, xmm6, R_SHUFFLE_D( 0, 0, 0, 0 ) movdqa xmm7, xmm6 pcmpgtw xmm6, SIMD_SSE2_word_63 pcmpgtw xmm7, SIMD_SSE2_word_31 pandn xmm7, SIMD_SSE2_byte_2 por xmm7, SIMD_SSE2_byte_1 pandn xmm6, xmm7 movdqa xmm3, xmm6 movdqa xmm7, xmm6 pxor xmm7, SIMD_SSE2_byte_not por xmm7, SIMD_SSE2_byte_scale_mask0 paddw xmm6, SIMD_SSE2_byte_1 pand xmm6, SIMD_SSE2_byte_scale_mask1 por xmm6, SIMD_SSE2_byte_scale_mask2 movd xmm4, dword ptr [edx] movd xmm5, dword ptr [ecx] pand xmm4, SIMD_SSE2_byte_scale_mask3 pand xmm5, SIMD_SSE2_byte_scale_mask3 pslld xmm3, 3 pand xmm3, SIMD_SSE2_byte_scale_mask4 por xmm4, xmm3 por xmm5, xmm3 paddb xmm4, SIMD_SSE2_byte_minus_128_0 paddb xmm5, SIMD_SSE2_byte_minus_128_0 pmullw xmm4, xmm6 pmullw xmm5, xmm6 pand xmm4, xmm7 pand xmm5, xmm7 psubb xmm4, SIMD_SSE2_byte_minus_128_0 psubb xmm5, SIMD_SSE2_byte_minus_128_0 movd dword ptr [edx], xmm4 movd dword ptr [ecx], xmm5 movdqa xmm0, xmmword ptr [esi+ 0*4] movdqa xmm1, xmmword ptr [esi+ 4*4] movdqa xmm2, xmmword ptr [esi+ 8*4] movdqa xmm3, xmmword ptr [esi+12*4] paddb xmm0, SIMD_SSE2_byte_minus_128_0 paddb xmm1, SIMD_SSE2_byte_minus_128_0 paddb xmm2, SIMD_SSE2_byte_minus_128_0 paddb xmm3, SIMD_SSE2_byte_minus_128_0 pmullw xmm0, xmm6 pmullw xmm1, xmm6 pmullw xmm2, xmm6 pmullw xmm3, xmm6 pand xmm0, xmm7 pand xmm1, xmm7 pand xmm2, xmm7 pand xmm3, xmm7 psubb xmm0, SIMD_SSE2_byte_minus_128_0 psubb xmm1, SIMD_SSE2_byte_minus_128_0 psubb xmm2, SIMD_SSE2_byte_minus_128_0 psubb xmm3, SIMD_SSE2_byte_minus_128_0 movdqa xmmword ptr [esi+ 0*4], xmm0 movdqa xmmword ptr [esi+ 4*4], xmm1 movdqa xmmword ptr [esi+ 8*4], xmm2 movdqa xmmword ptr [esi+12*4], xmm3 }} void InsetYCoCgBBox_SSE2( byte *minColor, byte *maxColor ) { __asm { mov esi, minColor mov edi, maxColor movd xmm0, dword ptr [esi] movd xmm1, dword ptr [edi] punpcklbw xmm0, SIMD_SSE2_byte_0 punpcklbw xmm1, SIMD_SSE2_byte_0 movdqa xmm2, xmm1 psubw xmm2, xmm0 psubw xmm2, SIMD_SSE2_word_insetYCoCgRound pand xmm2, SIMD_SSE2_word_insetYCoCgMask pmullw xmm0, SIMD_SSE2_word_insetShiftUp pmullw xmm1, SIMD_SSE2_word_insetShiftUp paddw xmm0, xmm2 psubw xmm1, xmm2 pmulhw xmm0, SIMD_SSE2_word_insetShiftDown pmulhw xmm1, SIMD_SSE2_word_insetShiftDown pmaxsw xmm0, SIMD_SSE2_word_0 pmaxsw xmm1, SIMD_SSE2_word_0 pand xmm0, SIMD_SSE2_word_inset565Mask pand xmm1, SIMD_SSE2_word_inset565Mask movdqa xmm2, xmm0 movdqa xmm3, xmm1 pmulhw xmm2, SIMD_SSE2_word_inset565Rep pmulhw xmm3, SIMD_SSE2_word_inset565Rep por xmm0, xmm2 por xmm1, xmm3 packuswb xmm0, xmm0 packuswb xmm1, xmm1 movd dword ptr [esi], xmm0 movd dword ptr [edi], xmm1 }} void SelectYCoCgDiagonal_SSE2( const byte *colorBlock, byte *minColor, byte *maxColor ) { __asm { mov esi, colorBlock mov edx, minColor mov ecx, maxColor movdqa xmm0, xmmword ptr [esi+ 0] movdqa xmm1, xmmword ptr [esi+16] movdqa xmm2, xmmword ptr [esi+32] movdqa xmm3, xmmword ptr [esi+48] pand xmm0, SIMD_SSE2_dword_word_mask pand xmm1, SIMD_SSE2_dword_word_mask pand xmm2, SIMD_SSE2_dword_word_mask pand xmm3, SIMD_SSE2_dword_word_mask pslldq xmm1, 2 pslldq xmm3, 2 por xmm0, xmm1 por xmm2, xmm3 movd xmm1, dword ptr [edx] movd xmm3, dword ptr [ecx] movdqa xmm6, xmm1 movdqa xmm7, xmm3 pavgb xmm1, xmm3 pshuflw xmm1, xmm1, R_SHUFFLE_D( 0, 0, 0, 0 ) pshufd xmm1, xmm1, R_SHUFFLE_D( 0, 0, 0, 0 ) movdqa xmm3, xmm1 pmaxub xmm1, xmm0 pmaxub xmm3, xmm2 pcmpeqb xmm1, xmm0 pcmpeqb xmm3, xmm2 movdqa xmm0, xmm1 movdqa xmm2, xmm3 psrldq xmm0, 1 psrldq xmm2, 1 pxor xmm0, xmm1 pxor xmm2, xmm3 pand xmm0, SIMD_SSE2_word_1 pand xmm2, SIMD_SSE2_word_1 paddw xmm0, xmm2 psadbw xmm0, SIMD_SSE2_byte_0 pshufd xmm1, xmm0, R_SHUFFLE_D( 2, 3, 0, 1 ) #ifdef NVIDIA_7X_HARDWARE_BUG_FIX paddw xmm1, xmm0 pcmpgtw xmm1, SIMD_SSE2_word_8 pand xmm1, SIMD_SSE2_byte_diagonalMask movdqa xmm0, xmm6 pcmpeqb xmm0, xmm7 pslldq xmm0, 1 pandn xmm0, xmm1#else paddw xmm0, xmm1 pcmpgtw xmm0, SIMD_SSE2_word_8 pand xmm0, SIMD_SSE2_byte_diagonalMask#endif pxor xmm6, xmm7 pand xmm0, xmm6 pxor xmm7, xmm0 pxor xmm6, xmm7 movd dword ptr [edx], xmm6 movd dword ptr [ecx], xmm7 }} void EmitAlphaIndices_SSE2( const byte *colorBlock, const byte minAlpha, const byte maxAlpha ) { __asm { mov esi, colorBlock movdqa xmm0, xmmword ptr [esi+ 0] movdqa xmm5, xmmword ptr [esi+16] psrld xmm0, 24 psrld xmm5, 24 packuswb xmm0, xmm5 movdqa xmm6, xmmword ptr [esi+32] movdqa xmm4, xmmword ptr [esi+48] psrld xmm6, 24 psrld xmm4, 24 packuswb xmm6, xmm4 movzx ecx, maxAlpha movd xmm5, ecx pshuflw xmm5, xmm5, R_SHUFFLE_D( 0, 0, 0, 0 ) pshufd xmm5, xmm5, R_SHUFFLE_D( 0, 0, 0, 0 ) movdqa xmm7, xmm5 movzx edx, minAlpha movd xmm2, edx pshuflw xmm2, xmm2, R_SHUFFLE_D( 0, 0, 0, 0 ) pshufd xmm2, xmm2, R_SHUFFLE_D( 0, 0, 0, 0 ) movdqa xmm3, xmm2 movdqa xmm4, xmm5 psubw xmm4, xmm2 pmulhw xmm4, SIMD_SSE2_word_div_by_14 movdqa xmm1, xmm2 paddw xmm1, xmm4 packuswb xmm1, xmm1 pmullw xmm5, SIMD_SSE2_word_scale66554400 pmullw xmm7, SIMD_SSE2_word_scale11223300 pmullw xmm2, SIMD_SSE2_word_scale11223300 pmullw xmm3, SIMD_SSE2_word_scale66554400 paddw xmm5, xmm2 paddw xmm7, xmm3 pmulhw xmm5, SIMD_SSE2_word_div_by_7 pmulhw xmm7, SIMD_SSE2_word_div_by_7 paddw xmm5, xmm4 paddw xmm7, xmm4 pshufd xmm2, xmm5, R_SHUFFLE_D( 0, 0, 0, 0 ) pshufd xmm3, xmm5, R_SHUFFLE_D( 1, 1, 1, 1 ) pshufd xmm4, xmm5, R_SHUFFLE_D( 2, 2, 2, 2 ) packuswb xmm2, xmm2 packuswb xmm3, xmm3 packuswb xmm4, xmm4 packuswb xmm0, xmm6 pshufd xmm5, xmm7, R_SHUFFLE_D( 2, 2, 2, 2 ) pshufd xmm6, xmm7, R_SHUFFLE_D( 1, 1, 1, 1 ) pshufd xmm7, xmm7, R_SHUFFLE_D( 0, 0, 0, 0 ) packuswb xmm5, xmm5 packuswb xmm6, xmm6 packuswb xmm7, xmm7 pminub xmm1, xmm0 pminub xmm2, xmm0 pminub xmm3, xmm0 pcmpeqb xmm1, xmm0 pcmpeqb xmm2, xmm0 pcmpeqb xmm3, xmm0 pminub xmm4, xmm0 pminub xmm5, xmm0 pminub xmm6, xmm0 pminub xmm7, xmm0 pcmpeqb xmm4, xmm0 pcmpeqb xmm5, xmm0 pcmpeqb xmm6, xmm0 pcmpeqb xmm7, xmm0 pand xmm1, SIMD_SSE2_byte_1 pand xmm2, SIMD_SSE2_byte_1 pand xmm3, SIMD_SSE2_byte_1 pand xmm4, SIMD_SSE2_byte_1 pand xmm5, SIMD_SSE2_byte_1 pand xmm6, SIMD_SSE2_byte_1 pand xmm7, SIMD_SSE2_byte_1 movdqa xmm0, SIMD_SSE2_byte_1 paddusb xmm0, xmm1 paddusb xmm2, xmm3 paddusb xmm4, xmm5 paddusb xmm6, xmm7 paddusb xmm0, xmm2 paddusb xmm4, xmm6 paddusb xmm0, xmm4 pand xmm0, SIMD_SSE2_byte_7 movdqa xmm1, SIMD_SSE2_byte_2 pcmpgtb xmm1, xmm0 pand xmm1, SIMD_SSE2_byte_1 pxor xmm0, xmm1 movdqa xmm1, xmm0 movdqa xmm2, xmm0 movdqa xmm3, xmm0 movdqa xmm4, xmm0 movdqa xmm5, xmm0 movdqa xmm6, xmm0 movdqa xmm7, xmm0 psrlq xmm1, 8- 3 psrlq xmm2, 16- 6 psrlq xmm3, 24- 9 psrlq xmm4, 32-12 psrlq xmm5, 40-15 psrlq xmm6, 48-18 psrlq xmm7, 56-21 pand xmm0, SIMD_SSE2_dword_alpha_bit_mask0 pand xmm1, SIMD_SSE2_dword_alpha_bit_mask1 pand xmm2, SIMD_SSE2_dword_alpha_bit_mask2 pand xmm3, SIMD_SSE2_dword_alpha_bit_mask3 pand xmm4, SIMD_SSE2_dword_alpha_bit_mask4 pand xmm5, SIMD_SSE2_dword_alpha_bit_mask5 pand xmm6, SIMD_SSE2_dword_alpha_bit_mask6 pand xmm7, SIMD_SSE2_dword_alpha_bit_mask7 por xmm0, xmm1 por xmm2, xmm3 por xmm4, xmm5 por xmm6, xmm7 por xmm0, xmm2 por xmm4, xmm6 por xmm0, xmm4 mov esi, globalOutData movd dword ptr [esi+0], xmm0 pshufd xmm1, xmm0, R_SHUFFLE_D( 2, 3, 0, 1 ) movd dword ptr [esi+3], xmm1 } globalOutData += 6;} void EmitColorIndices_SSE2( const byte *colorBlock, const byte *minColor, const byte *maxColor ) { ALIGN16( byte color0[16] ); ALIGN16( byte color1[16] ); ALIGN16( byte color2[16] ); ALIGN16( byte color3[16] ); ALIGN16( byte result[16] ); __asm { mov esi, maxColor mov edi, minColor pxor xmm7, xmm7 movdqa result, xmm7 movd xmm0, [esi] pand xmm0, SIMD_SSE2_byte_colorMask pshufd xmm0, xmm0, R_SHUFFLE_D( 0, 1, 0, 1 ) movdqa color0, xmm0 movd xmm1, [edi] pand xmm1, SIMD_SSE2_byte_colorMask pshufd xmm1, xmm1, R_SHUFFLE_D( 0, 1, 0, 1 ) movdqa color1, xmm1 punpcklbw xmm0, xmm7 punpcklbw xmm1, xmm7 movdqa xmm6, xmm1 paddw xmm1, xmm0 paddw xmm0, xmm1 pmulhw xmm0, SIMD_SSE2_word_div_by_3 packuswb xmm0, xmm7 pshufd xmm0, xmm0, R_SHUFFLE_D( 0, 1, 0, 1 ) movdqa color2, xmm0 paddw xmm1, xmm6 pmulhw xmm1, SIMD_SSE2_word_div_by_3 packuswb xmm1, xmm7 pshufd xmm1, xmm1, R_SHUFFLE_D( 0, 1, 0, 1 ) movdqa color3, xmm1 mov eax, 32 mov esi, colorBlock loop1: // iterates 2 times movq xmm3, qword ptr [esi+eax+0] pshufd xmm3, xmm3, R_SHUFFLE_D( 0, 2, 1, 3 ) movq xmm5, qword ptr [esi+eax+8] pshufd xmm5, xmm5, R_SHUFFLE_D( 0, 2, 1, 3 ) movdqa xmm0, xmm3 movdqa xmm6, xmm5 psadbw xmm0, color0 psadbw xmm6, color0 packssdw xmm0, xmm6 movdqa xmm1, xmm3 movdqa xmm6, xmm5 psadbw xmm1, color1 psadbw xmm6, color1 packssdw xmm1, xmm6 movdqa xmm2, xmm3 movdqa xmm6, xmm5 psadbw xmm2, color2 psadbw xmm6, color2 packssdw xmm2, xmm6 psadbw xmm3, color3 psadbw xmm5, color3 packssdw xmm3, xmm5 movq xmm4, qword ptr [esi+eax+16] pshufd xmm4, xmm4, R_SHUFFLE_D( 0, 2, 1, 3 ) movq xmm5, qword ptr [esi+eax+24] pshufd xmm5, xmm5, R_SHUFFLE_D( 0, 2, 1, 3 ) movdqa xmm6, xmm4 movdqa xmm7, xmm5 psadbw xmm6, color0 psadbw xmm7, color0 packssdw xmm6, xmm7 packssdw xmm0, xmm6 movdqa xmm6, xmm4 movdqa xmm7, xmm5 psadbw xmm6, color1 psadbw xmm7, color1 packssdw xmm6, xmm7 packssdw xmm1, xmm6 movdqa xmm6, xmm4 movdqa xmm7, xmm5 psadbw xmm6, color2 psadbw xmm7, color2 packssdw xmm6, xmm7 packssdw xmm2, xmm6 psadbw xmm4, color3 psadbw xmm5, color3 packssdw xmm4, xmm5 packssdw xmm3, xmm4 movdqa xmm7, result pslld xmm7, 16 movdqa xmm4, xmm0 movdqa xmm5, xmm1 pcmpgtw xmm0, xmm3 pcmpgtw xmm1, xmm2 pcmpgtw xmm4, xmm2 pcmpgtw xmm5, xmm3 pcmpgtw xmm2, xmm3 pand xmm4, xmm1 pand xmm5, xmm0 pand xmm2, xmm0 por xmm4, xmm5 pand xmm2, SIMD_SSE2_word_1 pand xmm4, SIMD_SSE2_word_2 por xmm2, xmm4 pshufd xmm5, xmm2, R_SHUFFLE_D( 2, 3, 0, 1 ) punpcklwd xmm2, SIMD_SSE2_word_0 punpcklwd xmm5, SIMD_SSE2_word_0 pslld xmm5, 8 por xmm7, xmm5 por xmm7, xmm2 movdqa result, xmm7 sub eax, 32 jge loop1 mov esi, globalOutData pshufd xmm4, xmm7, R_SHUFFLE_D( 1, 2, 3, 0 ) pshufd xmm5, xmm7, R_SHUFFLE_D( 2, 3, 0, 1 ) pshufd xmm6, xmm7, R_SHUFFLE_D( 3, 0, 1, 2 ) pslld xmm4, 2 pslld xmm5, 4 pslld xmm6, 6 por xmm7, xmm4 por xmm7, xmm5 por xmm7, xmm6 movd dword ptr [esi], xmm7 } globalOutData += 4;} bool CompressYCoCgDXT5_SSE2( const byte *inBuf, byte *outBuf, int width, int height, int &outputBytes ) { ALIGN16( byte block[64] ); ALIGN16( byte minColor[4] ); ALIGN16( byte maxColor[4] ); globalOutData = outBuf; for ( int j = 0; j < height; j += 4, inBuf += width * 4*4 ) { for ( int i = 0; i < width; i += 4 ) { ExtractBlock_SSE2( inBuf + i * 4, width, block ); GetMinMaxYCoCg_SSE2( block, minColor, maxColor ); ScaleYCoCg_SSE2( block, minColor, maxColor ); InsetYCoCgBBox_SSE2( minColor, maxColor ); SelectYCoCgDiagonal_SSE2( block, minColor, maxColor ); EmitByte( maxColor[3] ); EmitByte( minColor[3] ); EmitAlphaIndices_SSE2( block, minColor[3], maxColor[3] ); EmitUShort( ColorTo565( maxColor ) ); EmitUShort( ColorTo565( minColor ) ); EmitColorIndices_SSE2( block, minColor, maxColor ); } } outputBytes = globalOutData - outBuf; return true;}Appendix E
/* Real-time DXT1 & YCoCg-DXT5 compression (Cg 2.0) Copyright (c) NVIDIA Corporation. Written by: Ignacio Castano Thanks to JMP van Waveren, Simon Green, Eric Werness, Simon Brown Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions: The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software. THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.*/ // vertex programvoid compress_vp(float4 pos : POSITION, float2 texcoord : TEXCOORD0, out float4 hpos : POSITION, out float2 o_texcoord : TEXCOORD0 ){ o_texcoord = texcoord; hpos = pos;} typedef unsigned int uint;typedef unsigned int2 uint2;typedef unsigned int3 uint3;typedef unsigned int4 uint4; const float offset = 128.0 / 255.0; // Use dot product to minimize RMS instead absolute distance like in the CPU compressor.float colorDistance(float3 c0, float3 c1){ return dot(c0-c1, c0-c1);} float colorDistance(float2 c0, float2 c1){ return dot(c0-c1, c0-c1);} void ExtractColorBlockRGB(out float3 col[16], sampler2D image, float2 texcoord, float2 imageSize){#if 0 float2 texelSize = (1.0f / imageSize); texcoord -= texelSize * 2; for (int i = 0; i < 4; i++) { for (int j = 0; j < 4; j++) { col[i*4+j] = tex2D(image, texcoord + float2(j, i) * texelSize).rgb; } }#else // use TXF instruction (integer coordinates with offset) // note offsets must be constant //int4 base = int4(wpos*4-2, 0, 0); int4 base = int4(texcoord * imageSize - 1.5, 0, 0); col[0] = tex2Dfetch(image, base, int2(0, 0)).rgb; col[1] = tex2Dfetch(image, base, int2(1, 0)).rgb; col[2] = tex2Dfetch(image, base, int2(2, 0)).rgb; col[3] = tex2Dfetch(image, base, int2(3, 0)).rgb; col[4] = tex2Dfetch(image, base, int2(0, 1)).rgb; col[5] = tex2Dfetch(image, base, int2(1, 1)).rgb; col[6] = tex2Dfetch(image, base, int2(2, 1)).rgb; col[7] = tex2Dfetch(image, base, int2(3, 1)).rgb; col[8] = tex2Dfetch(image, base, int2(0, 2)).rgb; col[9] = tex2Dfetch(image, base, int2(1, 2)).rgb; col[10] = tex2Dfetch(image, base, int2(2, 2)).rgb; col[11] = tex2Dfetch(image, base, int2(3, 2)).rgb; col[12] = tex2Dfetch(image, base, int2(0, 3)).rgb; col[13] = tex2Dfetch(image, base, int2(1, 3)).rgb; col[14] = tex2Dfetch(image, base, int2(2, 3)).rgb; col[15] = tex2Dfetch(image, base, int2(3, 3)).rgb;#endif} float3 toYCoCg(float3 c){ float Y = (c.r + 2 * c.g + c.b) * 0.25; float Co = ( ( 2 * c.r - 2 * c.b ) * 0.25 + offset ); float Cg = ( ( -c.r + 2 * c.g - c.b) * 0.25 + offset ); return float3(Y, Co, Cg);} void ExtractColorBlockYCoCg(out float3 col[16], sampler2D image, float2 texcoord, float2 imageSize){#if 0 float2 texelSize = (1.0f / imageSize); texcoord -= texelSize * 2; for (int i = 0; i < 4; i++) { for (int j = 0; j < 4; j++) { col[i*4+j] = toYCoCg(tex2D(image, texcoord + float2(j, i) * texelSize).rgb); } }#else // use TXF instruction (integer coordinates with offset) // note offsets must be constant //int4 base = int4(wpos*4-2, 0, 0); int4 base = int4(texcoord * imageSize - 1.5, 0, 0); col[0] = toYCoCg(tex2Dfetch(image, base, int2(0, 0)).rgb); col[1] = toYCoCg(tex2Dfetch(image, base, int2(1, 0)).rgb); col[2] = toYCoCg(tex2Dfetch(image, base, int2(2, 0)).rgb); col[3] = toYCoCg(tex2Dfetch(image, base, int2(3, 0)).rgb); col[4] = toYCoCg(tex2Dfetch(image, base, int2(0, 1)).rgb); col[5] = toYCoCg(tex2Dfetch(image, base, int2(1, 1)).rgb); col[6] = toYCoCg(tex2Dfetch(image, base, int2(2, 1)).rgb); col[7] = toYCoCg(tex2Dfetch(image, base, int2(3, 1)).rgb); col[8] = toYCoCg(tex2Dfetch(image, base, int2(0, 2)).rgb); col[9] = toYCoCg(tex2Dfetch(image, base, int2(1, 2)).rgb); col[10] = toYCoCg(tex2Dfetch(image, base, int2(2, 2)).rgb); col[11] = toYCoCg(tex2Dfetch(image, base, int2(3, 2)).rgb); col[12] = toYCoCg(tex2Dfetch(image, base, int2(0, 3)).rgb); col[13] = toYCoCg(tex2Dfetch(image, base, int2(1, 3)).rgb); col[14] = toYCoCg(tex2Dfetch(image, base, int2(2, 3)).rgb); col[15] = toYCoCg(tex2Dfetch(image, base, int2(3, 3)).rgb);#endif} // find minimum and maximum colors based on bounding box in color spacevoid FindMinMaxColorsBox(float3 block[16], out float3 mincol, out float3 maxcol){ mincol = float3(1, 1, 1); maxcol = float3(0, 0, 0); for (int i = 0; i < 16; i++) { mincol = min(mincol, block[i]); maxcol = max(maxcol, block[i]); }} void InsetBBox(in out float3 mincol, in out float3 maxcol){ float3 inset = (maxcol - mincol) / 16.0 - (8.0 / 255.0) / 16; mincol = saturate(mincol + inset); maxcol = saturate(maxcol - inset);}void InsetYBBox(in out float mincol, in out float maxcol){ float inset = (maxcol - mincol) / 32.0 - (16.0 / 255.0) / 32.0; mincol = saturate(mincol + inset); maxcol = saturate(maxcol - inset);}void InsetCoCgBBox(in out float2 mincol, in out float2 maxcol){ float inset = (maxcol - mincol) / 16.0 - (8.0 / 255.0) / 16; mincol = saturate(mincol + inset); maxcol = saturate(maxcol - inset);} void SelectDiagonal(float3 block[16], in out float3 mincol, in out float3 maxcol){ float3 center = (mincol + maxcol) * 0.5; float2 cov = 0; for (int i = 0; i < 16; i++) { float3 t = block[i] - center; cov.x += t.x * t.z; cov.y += t.y * t.z; } if (cov.x < 0) { float temp = maxcol.x; maxcol.x = mincol.x; mincol.x = temp; } if (cov.y < 0) { float temp = maxcol.y; maxcol.y = mincol.y; mincol.y = temp; }} float3 RoundAndExpand(float3 v, out uint w){ int3 c = round(v * float3(31, 63, 31)); w = (c.r << 11) | (c.g << 5) | c.b; c.rb = (c.rb << 3) | (c.rb >> 2); c.g = (c.g << 2) | (c.g >> 4); return (float3)c * (1.0 / 255.0);} uint EmitEndPointsDXT1(in out float3 mincol, in out float3 maxcol){ uint2 output; maxcol = RoundAndExpand(maxcol, output.x); mincol = RoundAndExpand(mincol, output.y); // We have to do this in case we select an alternate diagonal. if (output.x < output.y) { float3 tmp = mincol; mincol = maxcol; maxcol = tmp; return output.y | (output.x << 16); } return output.x | (output.y << 16);} uint EmitIndicesDXT1(float3 col[16], float3 mincol, float3 maxcol){ // Compute palette float3 c[4]; c[0] = maxcol; c[1] = mincol; c[2] = lerp(c[0], c[1], 1.0/3.0); c[3] = lerp(c[0], c[1], 2.0/3.0); // Compute indices uint indices = 0; for (int i = 0; i < 16; i++) { // find index of closest color float4 dist; dist.x = colorDistance(col[i], c[0]); dist.y = colorDistance(col[i], c[1]); dist.z = colorDistance(col[i], c[2]); dist.w = colorDistance(col[i], c[3]); uint4 b = dist.xyxy > dist.wzzw; uint b4 = dist.z > dist.w; uint index = (b.x & b4) | (((b.y & b.z) | (b.x & b.w)) << 1); indices |= index << (i*2); } // Output indices return indices;} int GetYCoCgScale(float2 minColor, float2 maxColor){ float2 m0 = abs(minColor - offset); float2 m1 = abs(maxColor - offset); float m = max(max(m0.x, m0.y), max(m1.x, m1.y)); const float s0 = 64.0 / 255.0; const float s1 = 32.0 / 255.0; int scale = 1; if (m < s0) scale = 2; if (m < s1) scale = 4; return scale;} void SelectYCoCgDiagonal(const float3 block[16], in out float2 minColor, in out float2 maxColor){ float2 mid = (maxColor + minColor) * 0.5; float cov = 0; for (int i = 0; i < 16; i++) { float2 t = block[i].yz - mid; cov += t.x * t.y; } if (cov < 0) { float tmp = maxColor.y; maxColor.y = minColor.y; minColor.y = tmp; }} uint EmitEndPointsYCoCgDXT5(in out float2 mincol, in out float2 maxcol, int scale){ maxcol = (maxcol - offset) * scale + offset; mincol = (mincol - offset) * scale + offset; InsetCoCgBBox(mincol, maxcol); maxcol = round(maxcol * float2(31, 63)); mincol = round(mincol * float2(31, 63)); int2 imaxcol = maxcol; int2 imincol = mincol; uint2 output; output.x = (imaxcol.r << 11) | (imaxcol.g << 5) | (scale - 1); output.y = (imincol.r << 11) | (imincol.g << 5) | (scale - 1); imaxcol.r = (imaxcol.r << 3) | (imaxcol.r >> 2); imaxcol.g = (imaxcol.g << 2) | (imaxcol.g >> 4); imincol.r = (imincol.r << 3) | (imincol.r >> 2); imincol.g = (imincol.g << 2) | (imincol.g >> 4); maxcol = (float2)imaxcol * (1.0 / 255.0); mincol = (float2)imincol * (1.0 / 255.0); // Undo rescale. maxcol = (maxcol - offset) / scale + offset; mincol = (mincol - offset) / scale + offset; return output.x | (output.y << 16);} uint EmitIndicesYCoCgDXT5(float3 block[16], float2 mincol, float2 maxcol){ // Compute palette float2 c[4]; c[0] = maxcol; c[1] = mincol; c[2] = lerp(c[0], c[1], 1.0/3.0); c[3] = lerp(c[0], c[1], 2.0/3.0); // Compute indices uint indices = 0; for (int i = 0; i < 16; i++) { // find index of closest color float4 dist; dist.x = colorDistance(block[i].yz, c[0]); dist.y = colorDistance(block[i].yz, c[1]); dist.z = colorDistance(block[i].yz, c[2]); dist.w = colorDistance(block[i].yz, c[3]); uint4 b = dist.xyxy > dist.wzzw; uint b4 = dist.z > dist.w; uint index = (b.x & b4) | (((b.y & b.z) | (b.x & b.w)) << 1); indices |= index << (i*2); } // Output indices return indices;} uint EmitAlphaEndPointsYCoCgDXT5(in out float mincol, int out float maxcol){ InsetYBBox(mincol, maxcol); uint c0 = round(mincol * 255); uint c1 = round(maxcol * 255); return (c0 << 8) | c1;} uint2 EmitAlphaIndicesYCoCgDXT5(float3 block[16], float minAlpha, float maxAlpha){ const int ALPHA_RANGE = 7; float mid = (maxAlpha - minAlpha) / (2.0 * ALPHA_RANGE); float ab1 = minAlpha + mid; float ab2 = (6 * maxAlpha + 1 * minAlpha) * (1.0 / ALPHA_RANGE) + mid; float ab3 = (5 * maxAlpha + 2 * minAlpha) * (1.0 / ALPHA_RANGE) + mid; float ab4 = (4 * maxAlpha + 3 * minAlpha) * (1.0 / ALPHA_RANGE) + mid; float ab5 = (3 * maxAlpha + 4 * minAlpha) * (1.0 / ALPHA_RANGE) + mid; float ab6 = (2 * maxAlpha + 5 * minAlpha) * (1.0 / ALPHA_RANGE) + mid; float ab7 = (1 * maxAlpha + 6 * minAlpha) * (1.0 / ALPHA_RANGE) + mid; uint2 indices = 0; uint index; for (int i = 0; i < 6; i++) { float a = block[i].x; index = 1; index += (a <= ab1); index += (a <= ab2); index += (a <= ab3); index += (a <= ab4); index += (a <= ab5); index += (a <= ab6); index += (a <= ab7); index &= 7; index ^= (2 > index); indices.x |= index << (3 * i + 16); } indices.y = index >> 1; for (int i = 6; i < 16; i++) { float a = block[i].x; index = 1; index += (a <= ab1); index += (a <= ab2); index += (a <= ab3); index += (a <= ab4); index += (a <= ab5); index += (a <= ab6); index += (a <= ab7); index &= 7; index ^= (2 > index); indices.y |= index << (3 * i - 16); } return indices;} // compress a 4x4 block to DXT1 format// integer version, renders to 2 x int32 bufferuint4 compress_DXT1_fp(float2 texcoord : TEXCOORD0, uniform sampler2D image, uniform float2 imageSize = { 512.0, 512.0 } ) : COLOR{ // read block float3 block[16]; ExtractColorBlockRGB(block, image, texcoord, imageSize); // find min and max colors float3 mincol, maxcol; FindMinMaxColorsBox(block, mincol, maxcol); // enable the diagonal selection for better quality at a small performance penalty// SelectDiagonal(block, mincol, maxcol); InsetBBox(mincol, maxcol); uint4 output; output.x = EmitEndPointsDXT1(mincol, maxcol); output.w = EmitIndicesDXT1(block, mincol, maxcol); return output;} // compress a 4x4 block to YCoCg-DXT5 format// integer version, renders to 4 x int32 bufferuint4 compress_YCoCgDXT5_fp(float2 texcoord : TEXCOORD0, uniform sampler2D image, uniform float2 imageSize = { 512.0, 512.0 } ) : COLOR{ //imageSize = tex2Dsize(image, texcoord); // read block float3 block[16]; ExtractColorBlockYCoCg(block, image, texcoord, imageSize); // find min and max colors float3 mincol, maxcol; FindMinMaxColorsBox(block, mincol, maxcol); SelectYCoCgDiagonal(block, mincol.yz, maxcol.yz); int scale = GetYCoCgScale(mincol.yz, maxcol.yz); // Output CoCg in DXT1 block. uint4 output; output.z = EmitEndPointsYCoCgDXT5(mincol.yz, maxcol.yz, scale); output.w = EmitIndicesYCoCgDXT5(block, mincol.yz, maxcol.yz); // Output Y in DXT5 alpha block. output.x = EmitAlphaEndPointsYCoCgDXT5(mincol.x, maxcol.x); uint2 indices = EmitAlphaIndicesYCoCgDXT5(block, mincol.x, maxcol.x); output.x |= indices.x; output.y = indices.y; return output;} float4 display_fp(float2 texcoord : TEXCOORD0, uniform sampler2D image : TEXUNIT0) : COLOR{ float4 rgba = tex2D(image, texcoord); float Y = rgba.a; float scale = 1.0 / ((255.0 / 8.0) * rgba.b + 1); float Co = (rgba.r - offset) * scale; float Cg = (rgba.g - offset) * scale; float R = Y + Co - Cg; float G = Y + Cg; float B = Y - Co - Cg; return float4(R, G, B, 1);}
- 实时的YcoCg-DXT压缩
- 实时DXT压缩
- Real-Time YCoCg-DXT Compression
- 实时法线贴图dxt压缩算法
- DXT 图片压缩
- DXT纹理压缩
- DXT纹理压缩
- DXT纹理压缩
- DXT纹理压缩
- DXT纹理压缩
- DXT纹理压缩
- DXT纹理压缩格式解析
- 飞速文件安全同步软件的实时压缩技术
- 石墨文档的云端表格实时压缩策略
- 基于压缩的实时目标追踪(CT)
- gulp的实时刷新、代码压缩、代码排错
- 实时数据库的历史数据是否需要进行压缩?可用什么方法压缩?
- The Compact YCoCg Frame Buffer
- 为什么旗舰智能手机屏幕越来越大
- mybatis resultMap鉴别器使用
- 从 0 到 1 走进 Kaggle
- 可提高Java调试功能的5款工具
- 考研逻辑整理
- 实时的YcoCg-DXT压缩
- View的事件传递源码解析
- •适配器模式(Adapter Pattern)-结构型模式
- Linux下入门shell编程
- 第11课: 彻底解密WordCount运行原理
- 第十届省赛-A-谍报分析
- 了解这23种设计模式
- 布局优化方案
- 第十届省赛-C-最小秘钥


