简单理解Hadoop(Hadoop是什么、如何工作)
来源:互联网 发布:长城防火墙 知乎 编辑:程序博客网 时间:2024/06/06 03:12
见:http://os.51cto.com/art/201211/364374.htm#topx
见:http://blessht.iteye.com/blog/2095675
见:http://os.51cto.com/art/201207/346023.htm
一、Hadoop主要的任务部署分为3个部分,分别是:Client机器,主节点和从节点。主节点主要负责Hadoop两个关键功能模块HDFS、Map Reduce的监督。当Job Tracker使用Map Reduce进行监控和调度数据的并行处理时,名称节点则负责HDFS监视和调度。从节点负责了机器运行的绝大部分,担当所有数据储存和指令计算的苦差。每个从节点既扮演者数据节点的角色又冲当与他们主节点通信的守护进程。守护进程隶属于Job Tracker,数据节点在归属于名称节点。
二、Hadoop核心和特点
Hadoop的核心就是HDFS和MapReduce,而两者只是理论基础,不是具体可使用的高级应用
HDFS的设计特点是:
1、大数据文件,非常适合上T级别的大文件或者一堆大数据文件的存储,如果文件只有几个G甚至更小就没啥意思了。
2、文件分块存储,HDFS会将一个完整的大文件平均分块存储到不同计算器上,它的意义在于读取文件时可以同时从多个主机取不同区块的文件,多主机读取比单主机读取效率要高得多得都。
3、流式数据访问,一次写入多次读写,这种模式跟传统文件不同,它不支持动态改变文件内容,而是要求让文件一次写入就不做变化,要变化也只能在文件末添加内容。
4、廉价硬件,HDFS可以应用在普通PC机上,这种机制能够让给一些公司用几十台廉价的计算机就可以撑起一个大数据集群。
5、硬件故障,HDFS认为所有计算机都可能会出问题,为了防止某个主机失效读取不到该主机的块文件,它将同一个文件块副本分配到其它某几个主机上,如果其中一台主机失效,可以迅速找另一块副本取文件。
HDFS的关键元素:
1)Block:将一个文件进行分块,通常是64M。
2)NameNode:保存整个文件系统的目录信息、文件信息及分块信息,这是由唯一 一台主机专门保存,当然这台主机如果出错,NameNode就失效了。在 Hadoop2.* 开始支持 activity-standy 模式----如果主 NameNode 失效,启动备用主机运行 NameNode。
3)DataNode:分布在廉价的计算机上,用于存储Block块文件。
MapReduce:
我们要数图书馆中的所有书。你数1号书架,我数2号书架。这就是“Map”。我们人越多,数书就更快。
现在我们到一起,把所有人的统计数加在一起。这就是“Reduce”。
通俗说MapReduce是一套从海量源数据提取分析元素最后返回结果集的编程模型,将文件分布式存储到硬盘是第一步,而从海量数据中提取分析我们需要的内容就是MapReduce做的事了。
MapReduce的基本原理就是:将大的数据分析分成小块逐个分析,最后再将提取出来的数据汇总分析,最终获得我们想要的内容。当然怎么分块分析,怎么做Reduce操作非常复杂,Hadoop已经提供了数据分析的实现,我们只需要编写简单的需求命令即可达成我们想要的数据。
Hadoop典型应用有:搜索、日志处理、推荐系统、数据分析、视频图像分析、数据保存等。
三、
Hadoop的集群主要由 NameNode,DataNode,Secondary NameNode,JobTracker,TaskTracker组成.
如下图所示:
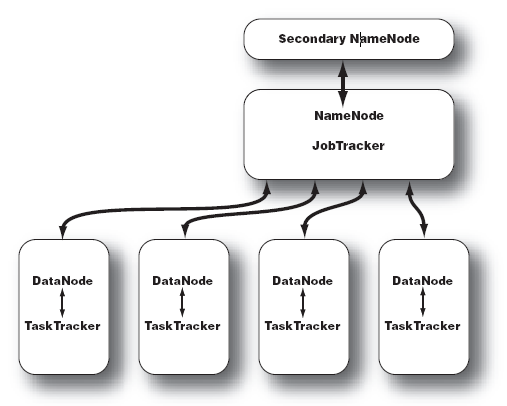
1)NameNode:记录了文件是如何被拆分成block以及这些block都存储到了那些DateNode节点 .
2)NameNode:保存了文件系统运行的状态信息 .
3)DataNode:存储被拆分的blocks .
4)Secondary NameNode:帮助 NameNode 收集文件系统运行的状态信息 .
5)JobTracker:当有任务提交到 Hadoop 集群的时候负责 Job 的运行,负责调度多个 TaskTracker .
6)TaskTracker:负责某一个 map 或者 reduce 任务 .
- 简单理解Hadoop(Hadoop是什么、如何工作)
- Hadoop是什么?一句话理解
- Hadoop是什么?一句话理解
- Hadoop:是什么,如何工作,可以用来做什么
- Hadoop系列--Hadoop介绍(Hadoop是什么)
- hadoop入门教程-hadoop是什么
- 初识Hadoop,Hadoop是什么?
- Hadoop是什么
- Hadoop是什么
- Hadoop是什么
- hadoop是什么?
- Hadoop是什么
- Hadoop是什么?
- Hadoop是什么
- Hadoop是什么
- Hadoop是什么?
- hadoop是什么
- hadoop是什么
- Python学习之旅-4
- 【centos】配置postgresql数据库。
- 滑动窗口协议
- Web基础-Uri跟Url的区别
- Android适配底部返回键等虚拟键盘的完美解决方案
- 简单理解Hadoop(Hadoop是什么、如何工作)
- iOS 异步多任务请求完成后汇总结果
- Echarts之Chrome不兼容fontSize小于12的字体大小设置&解决办法
- 实现案例新闻客户端
- OpenDaylight-Boron学习笔记: 6 VTN模块
- win 7笔记本连接wifi不能输入密码解决办法(图文教程)
- 最长上升子序列nlogn算法
- 接口芯片
- 学习笔记: shell 中的 set -e , set +e 用法


