R语言_rpart包和party包的简单比较
来源:互联网 发布:g92编程 编辑:程序博客网 时间:2024/06/05 09:08
决策树模型是一种简单易用的非参数分类器。它不需要对数据有任何的先验假设,计算速度较快,结果容易解释,而且稳健性强,不怕噪声数据和缺失数据。决策树模型的基本计算步骤如下:先从n个自变量中挑选一个,寻找最佳分割点,将数据划分为两组。针对分组后数据,将上述步骤重复下去,直到满足某种条件。
在决策树建模中需要解决的重要问题有三个:
在R语言中关于决策树建模,最为常用的有两个包,一个是rpart包,另一个是party包。我们来看一下对于上述问题,这两个包分别是怎么处理的。
rpart包的处理方式:首先对所有自变量和所有分割点进行评估,最佳的选择是使分割后组内的数据更为“一致”(pure)。这里的“一致”是指组内数据的因变量取值变异较小。rpart包对这种“一致”性的默认度量是Gini值。确定停止划分的参数有很多(参见rpart.control),确定这些参数是非常重要而微妙的,因为划分越细,模型越复杂,越容易出现过度拟合的情况,而划分过粗,又会出现拟合不足。处理这个问题通常是使用“剪枝”(prune)方法。即先建立一个划分较细较为复杂的树模型,再根据交叉检验(Cross-Validation)的方法来估计不同“剪枝”条件下,各模型的误差,选择误差最小的树模型。
party包的处理方式:它的背景理论是“条件推断决策树”(conditional inference trees):它根据统计检验来确定自变量和分割点的选择。即先假设所有自变量与因变量均独立。再对它们进行卡方独立检验,检验P值小于阀值的自变量加入模型,相关性最强的自变量作为第一次分割的自变量。自变量选择好后,用置换检验来选择分割点。用party包建立的决策树不需要剪枝,因为阀值就决定了模型的复杂程度。所以如何决定阀值参数是非常重要的(参见ctree_control)。较为流行的做法是取不同的参数值进行交叉检验,选择误差最小的模型参数。
下面我们用iris数据集,分别用两个包的默认参数来建模,观察其图形结果。rpart包的内置绘图功能不强,因此使用partykit包来绘制rpart建模对象。
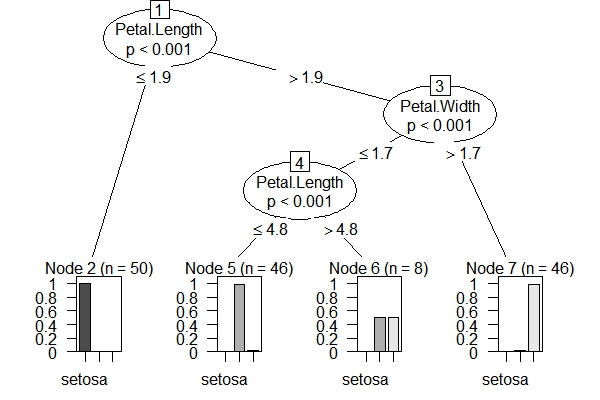
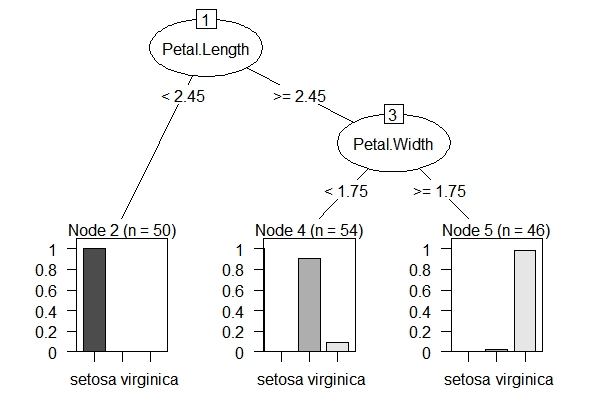 上面的图形是rpart包的结果,下图是party包的结果,两种方法的前两个划分变量都是一致的,只是在划分界值上略有不同,另外party包的结果还复杂一些。基本上两类方法的预测能力没有很大区别。
上面的图形是rpart包的结果,下图是party包的结果,两种方法的前两个划分变量都是一致的,只是在划分界值上略有不同,另外party包的结果还复杂一些。基本上两类方法的预测能力没有很大区别。
出了决策树模型之外,这两个包也分别提供了集成学习方法随机森林,基于rpart包的随机森林是randomForest包,而基于party包的随机森林即cforest函数
在决策树建模中需要解决的重要问题有三个:
- 如何选择自变量
- 如何选择分割点
- 确定停止划分的条件
在R语言中关于决策树建模,最为常用的有两个包,一个是rpart包,另一个是party包。我们来看一下对于上述问题,这两个包分别是怎么处理的。
rpart包的处理方式:首先对所有自变量和所有分割点进行评估,最佳的选择是使分割后组内的数据更为“一致”(pure)。这里的“一致”是指组内数据的因变量取值变异较小。rpart包对这种“一致”性的默认度量是Gini值。确定停止划分的参数有很多(参见rpart.control),确定这些参数是非常重要而微妙的,因为划分越细,模型越复杂,越容易出现过度拟合的情况,而划分过粗,又会出现拟合不足。处理这个问题通常是使用“剪枝”(prune)方法。即先建立一个划分较细较为复杂的树模型,再根据交叉检验(Cross-Validation)的方法来估计不同“剪枝”条件下,各模型的误差,选择误差最小的树模型。
party包的处理方式:它的背景理论是“条件推断决策树”(conditional inference trees):它根据统计检验来确定自变量和分割点的选择。即先假设所有自变量与因变量均独立。再对它们进行卡方独立检验,检验P值小于阀值的自变量加入模型,相关性最强的自变量作为第一次分割的自变量。自变量选择好后,用置换检验来选择分割点。用party包建立的决策树不需要剪枝,因为阀值就决定了模型的复杂程度。所以如何决定阀值参数是非常重要的(参见ctree_control)。较为流行的做法是取不同的参数值进行交叉检验,选择误差最小的模型参数。
下面我们用iris数据集,分别用两个包的默认参数来建模,观察其图形结果。rpart包的内置绘图功能不强,因此使用partykit包来绘制rpart建模对象。
出了决策树模型之外,这两个包也分别提供了集成学习方法随机森林,基于rpart包的随机森林是randomForest包,而基于party包的随机森林即cforest函数
阅读全文
0 0
- R语言_rpart包和party包的简单比较
- R语言-决策树-party包
- R语言专题,如何使用party包构建决策树?
- [R语言] 加载和安装R包
- R语言中帮助和R包
- [R语言] 加载和安装R包
- 02R语言的包
- R语言-安装randomForest和ROCR包
- R语言安装包下载和安装
- R语言离线下载包和依赖
- knitr包 R语言
- R语言 -- 包
- R语言quantmod包
- R语言tseries包
- R语言quantstrat包
- R语言_xlsx包
- R语言plyr包和dplyr包学习
- 【R语言读书学习笔记】安装包和加载包
- 值传递和引用传递
- Java下利用Jackson进行JSON解析和序列化
- python播放器代码
- 存
- python Mac 错误信息:Intel MKL FATAL ERROR: Cannot load libmkl_avx2.so or libmkl_def.so
- R语言_rpart包和party包的简单比较
- iosAnimationDemo
- Android Studio上非常棒的插件
- 排序算法之折半插入排序
- escape()、encodeURI()、encodeURIComponent()区别详解
- JAVA集合框架中的常用集合及其特点、适用场景、实现原理简介
- vim配置C++ IDE
- 当设计一个APP UI的时候我们想什么...
- Xamarin.Android 使用timer 并更改UI


