增强学习总结
来源:互联网 发布:cctv网络电视客户端 编辑:程序博客网 时间:2024/05/06 05:11
基本概念
- : 有限状态 state 集合,s 表示某个特定状态
- : 有限动作 action 集合,a 表示某个特定动作
- Transition Model : Transition Model, 根据当前状态 s 和动作 a 预测下一个状态 s’,这里的 表示从 s 采取行动 a 转移到 s’ 的概率
- Reward :表示 agent 采取某个动作后的即时奖励,它还有 R(s, a, s’), R(s) 等表现形式,采用不同的形式,其意义略有不同
- Policy : 根据当前 state 来产生 action,可表现为 或 ,后者表示某种状态下执行某个动作的概率
Introduction to Q-Learning
Imagine yourself in a treasure hunt in a maze . The game is as follows :
You start at a given position, the starting state . From any state you can go left, right, up or down or stay in the same place provided you don’t cross the premises of the maze. Each action will take you to a cell of the grid (a different state). Now, there is a treasure chest at one of the states (the goal state). Also, the maze has a pit of snakes in certain positions/states. Your goal is to travel from the starting state to the goal state by following a path that doesn’t have snakes in it.
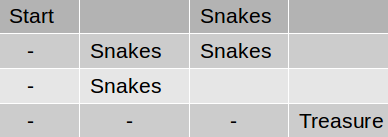
When you place an agent in the grid(we will refer to it as our environment) it will first explore. It doesn’t know what snakes are , neither does it know what or where the treasure is. So, to give it the idea of snakes and the treasure chest we will give some rewards to it after it takes each action. For every snake pit it steps onto we will give it a reward of -10. For the treasure we will give it a reward of +10. Now we want our agent to complete the task as fast as possible (to take the shortest route). For this, we will give rest of the states a reward of -1. Then we will tell it to maximise the score. Now as the agent explores , it learns that snakes are harmful for it, the treasure is good for it and it has to get the treasure as fast as possible. The ‘-’ path in the figure shows the shortest path with maximum reward.
Q-Learning attempts to learn the value of being in a given state, and taking a specific action there.
What we will do is develop a table. Where the rows will be the states and the columns are the actions it can take. So, we have a 16x5 (80 possible state-action) pairs where each state is one cell of the maze-grid.
We start by initializing the table to be uniform (all zeros), and then as we observe the rewards we obtain for various actions, we update the table accordingly. We will update the table using the Bellman Equation .
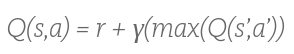
‘S’ represents the current state . ‘a’ represents the action the agent takes from the current state. ‘ S’ ’ represents the state resulting from the action. ‘r’ is the reward you get for taking the action and ‘γ’ is the discount factor. So, the Q value for the state ‘S’ taking the action ‘a’ is the sum of the instant reward and the discounted future reward (value of the resulting state). The discount factor ‘γ’ determines how much importance you want to give to future rewards. Say, you go to a state which is further away from the goal state, but from that state the chances of encountering a state with snakes is less, so, here the future reward is more even though the instant reward is less.
We will refer to each iteration(attempt made by the agent) as an episode. For each episode, the agent will try to achieve the goal state and for every transition it will keep on updating the values of the Q table.
Lets see how to calculate the Q table :
For this purpose we will take a smaller maze-grid for ease.

The initial Q-table would look like ( states along the rows and actions along the columns ) :

U — up, D — down, L — left, R — right
The reward table would look like :
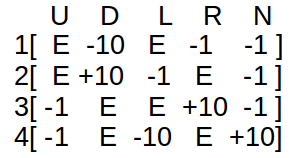
Here, E represents NULL, i.e., there can be no such transitions.
Algorithm:
- Initialise Q-matrix by all zeros. Set value for ‘γ’. Fill rewards matrix.
- For each episode. Select a random starting state (here we will restrict our starting state to state-1).
- Select one among all possible actions for the current state (S).
- Travel to the next state (S’) as a result of that action (a).
- For all possible actions from the state (S’) select the one with the highest Q value.
- Update Q-table using eqn.1 .
- Set the next state as the current state.
- If goal state reached then end.
Example : Lets say we start with state 1 . We can go either D or R. Say, we chose D . Then we will reach 3 (the snake pit). So, then we can go either U or R . So, taking γ = 0.8, we have :
Q(1,D) = R(1,D) + γ*[max(Q(3,U) & Q(3,R))]
Q(1,D) = -10 + 0.8*0 = -10
Here, max(Q(3,U) & Q(3,R)) = 0 as Q matrix not yet updated. -10 is for stepping on the snakes. So, new Q-table looks like :

Now, 3 is the starting state. From 3, lets say we go R. So, we go on 4 . From 4, we can go U or L .
Q(3,R) = R(3,R) + 0.8*[max(Q(4,U) & Q(4,L))]
Q(3,R) = 10 + 0.8*0 = 10

So, now we have reached the goal state 4. So, we terminate and more passes to let our agent understand the value of each state and action. Keep making passes until the values remain constant. This means that your agent has tried out all possible state-action pairs.
Implementation in python :
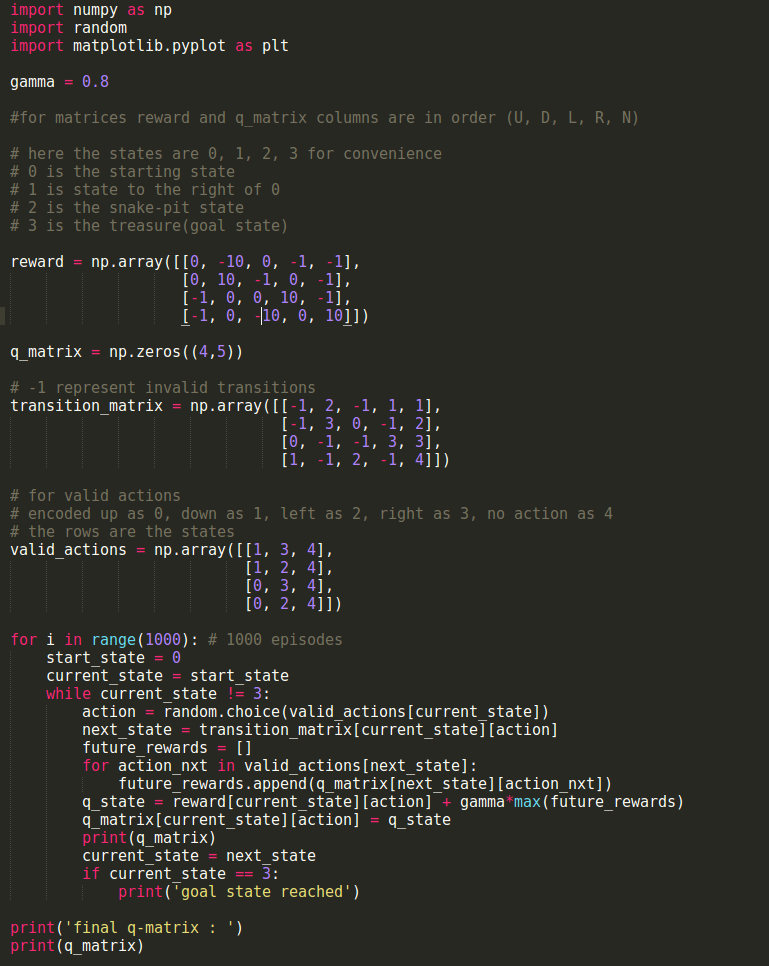
Output for the last q_matrix :

In the next article I will cover the usage of Neural Networks for Q-Learning and the short-comings of using the tabular approach. Also, we will be working on games from Open-AI gym for testing. Until then, bye.
原文链接:https://medium.com/towards-data-science/introduction-to-q-learning-88d1c4f2b49c
- 增强学习总结
- javaweb学习总结(java增强)
- 增强学习
- 增强学习
- 增强学习
- 增强学习
- 增强学习
- 增强学习
- 增强学习
- SAP增强总结-第一代增强
- [29期] 增强团队学习凝聚力! 个人知识点,总结!
- 增强方式、方法总结
- BW中的增强总结
- sap增强小总结
- 查找增强方法总结
- 图像增强方法总结
- 【成都】增强使用总结
- 语音增强算法总结
- iOS开发
- 【工具类】-条码生成类(一维码,二维码)
- Docker实践-docker + svn + maven + tomcat 一键部署Java Web项目
- 正则匹配大小写字母、汉字、特殊字符,并统计次数
- 优秀开发者的小习惯
- 增强学习总结
- Javascript之Date()
- Ajax的原理和应用
- 如何php防止XSS攻击
- bootstrap table分页,重新数据查询时页码为当前页问题
- 详解Django中Request对象的相关用法
- 使用gradle创建java项目2
- 移动web之滚动篇
- springMVC-笔记008-异常


