Q&A——图形渲染(二)
来源:互联网 发布:网络歌曲2015伤感情歌 编辑:程序博客网 时间:2024/06/04 19:31
图形渲染
Q1:以前端游时代,材质根据Pass不同、光照环境不同可以离线预编译成ShaderCache,运行时并不需要拼材质再实时编译,只要加载二进制代码就好了。那Unity有没有做这件事呢?我们是根据平台和环境预编译的Shader。
对于支持 Binary Shader 加载的设备,在首次编译某个 Shader 的时候是会生成其对应的 Binary Shader Cache ,生成的 Binary 文件位于和 Application.persistantPath 并列的Cache 目录下。
图形渲染
Q2:相同效果前提下,就性能而言,Shader 是用 V&F 还是Surface好?
Surface生成的V&F比较庞杂,分支较多,如果不注意 #pragma surface 参数的选择,容易出现不必要的开销。举例来说,如果直接用 Unity 5.x 中默认创建的 Surface Shader (默认参数为 #pragma surface surf Standard fullforwardshadows),那么 Shader 是会做 Physically based Standard Lighting 的,而这在移动端开销非常大,且并非必要。
图形渲染
Q3:Lightmap在Baked GI的等待时间比较长(Realtime GI已关闭),想请教有没有什么建议的参数或是方式,可以缩短等待的时间?
目前就我们的了解,在Unity 5.x比较影响烘焙时间的主要是大面积的面片导致Light Transport 过程过久(Enlighten 的机制所限)。可以尝试拆分面积较大的面片,来提高烘焙的速度(通常,拆分大面积的面片对渲染性能也会有所提升)。
主要原因可参考如下的帖子: http://forum.unity3d.com/threads/light-transport-problem-with-large-objects.310405
图形渲染
Q4:我看到Unity 5.3.5版本中恢复了对粒子系统的合批功能,但是我尝试下来并没有达到这个效果。是粒子系统合批有什么要求吗,实例化会不会对粒子系统的合批造成影响呢?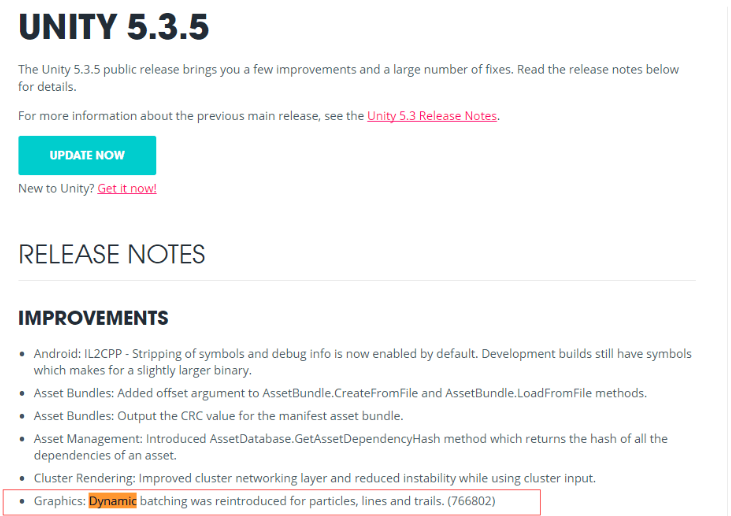
经过我们验证,Unity 5.3.5 版本中确实恢复了对粒子系统的动态合批功能(可尝试添加多个默认的粒子系统,观察Batches的数量变化)。同时我们并未发现实例化会对粒子系统的合批产生影响。
需要注意的是,粒子系统合批的前提是渲染顺序上相邻,且材质相同。默认情况下,粒子系统的渲染与一般的半透明渲染一样,必须从后向前渲染。通常一个特效可能由多个不同材质的粒子系统组成,因此在大多数情况下,当屏幕上出现多个相同的特效时,由于粒子系统的排序问题并不会生成合批。所以,目前只能通过人为指定粒子系统的渲染顺序来绕过该问题,具体做法可见该博客地址:
http://blog.csdn.net/github_32062421/article/details/49203501
但该做法的缺点也显而易见,当两个特效部分重叠时,粒子系统的排序是不正确的(会出现后方的粒子系统遮挡前方的粒子系统的现象),因此也只能酌情采用。
图形渲染
Q5:某个Shader里设置了Culling Off,会影响到后面所有Shader的渲染状态么(假设后面不再设置Culling)?
一次 Draw Call 提交所相关的 Render State 是不会影响到下一次的渲染状态的。如果不在 Shader 中显示指定 Cull 模式,则会使用默认的 Cull Back。
图形渲染
Q6:项目在发布时,Player Setting中勾选的这个选项, 对于已经打包并且放到了Streaming Assets中的AssetBundle文件有效果吗?模型资源里有个
对于已经打包并且放到了Streaming Assets中的AssetBundle文件有效果吗?模型资源里有个 选项,是否能达到同样的效果?
选项,是否能达到同样的效果?
理论上 Optimize Mesh Data 是 Build Player 或者 Bundle 时才生效的,所以之前打好的 Bundle 就没效果了。另外,两个选项的效果是不同的,后者是调整面片排序的。
图形渲染
Q7:MeshBaker 烘焙的Mesh可以保存到Prefab中,但是不能像FBX一样,设置Model导入设置中的Generate Lightmap UVs 等信息,请问有没有大招可以处理此情况?
首先从理论上说,一个 Mesh 只能有一个 LightmapIndex 和 LightmapOffset 属性,这就决定了 Mesh 的合并必须在 Lightmap 的烘焙之前。
而在做Mesh合并时,需要注意到UV2对于一个Mesh而言,其所有三角面的UV区域都必须是互不重叠的,所以不能简单直接地合并。
考虑到合并前每一个Mesh的UV2区域都应该是在[0,1]x[0,1]的区间中,在合并时可以给每一个UV2区域做一个缩小和平移,从而可以把每个区间在互不重叠的情况下,放到同一个[0,1]x[0,1]的区间中。
在UV2也正确拼合后,重新进行Lightmap的烘焙即可得到正确的效果。
图形渲染
Q8:我们现在采取了2种资源管理方式, 我想了解下内存占用问题。 方式A:AssetBundle加载好以后在内存中保留, 如果需要创建对象就通过Instantiate来创建。方式B:AssetBundle加载好以后立刻通过Instantiate实例化一个对象, 然后Unload(false)这个AssetBundle,如果需要,创建对象通过clone来完成。对于方式A,在Profiler中发现 WebStream中有相关AssetBundle文件存在, 我们认为这份内存是多余的, 所以就采取了方式B, 方式B又面临资源卸载不干净的情况。想确认一个问题, 如果采取方式A: 一个 xxx.assetBundle原始文件大小是 1MB, 解压到Webstream内存中是2MB, 最终实际内存占用是2MB 还是3MB 呢?
如果采取方式A:最终实际内存占用是2MB,而不是3MB,WebStream中已经包含原始AssetBundle的数据。对于没有依赖关系的AssetBundle文件,我们推荐方式B的形式对AssetBundle进行卸载,这样可以免除不必要的内存占用,对于这种方式加载出来的资源,可以通过Resources.UnloadAsset和Resources.UnloadUnusedAssets来进行卸载,如果无法卸载,则该资源一定被缓存了,研发团队可通过检测自己的缓存池/Constainer来进行检测。同时,如果是Unity 5.3以后版本,可尝试通过Memory Profiler来进一步查看。
图形渲染
Q9: 我用内建的Shader渲染场景,深度图里有内容。而用自己的Shader,取到的深度图什么都没有,都是1,什么原因导致的呢?我已经打开ZWrite了。
在Unity4.x中,Unity的_CameraDepthTexture 的生成,会根据Rendering Path的选择和设备的不同使用不同的方法实现,一种是直接从depth buffer获取,另一种是添加额外的Pass来渲染到纹理。目前在移动设备上主要是通过后者实现,而后者的实现借助了Shader Replacement的机制(批量替换为简单的Shader,并将深度渲染到纹理中)。
因此,在使用自定义的Shader时,就需要正确地设置RenderType的Tag(所有内置Shader都是设置好的),从而使得Shader Replacement正确地执行。具体可见文档:
http://docs.unity3d.com/Manual/SL-ShaderReplacement.html
而在Unity5.x中,则不再通过Shader Replacement来实现了,因此需要添加一个包含了"LightMode"="ShadowCaster"的Tags的额外Pass,用来写入深度值。
图形渲染
Q10:同一个场景,烘了两套 Lightmap,切换的时候有没有办法在这两套Lightmap之间实现平滑过渡?
可以尝试重写渲染Lightmap的相关Shader,Unity提供了DecodeLightmap函数,因此在Shader中同时Decode需要过渡的两张Lightmap,然后针对相同的采样点进行加权平均(具体的过渡方式可自行控制),从而得到Lightmap平滑过渡的效果。
- Q&A——图形渲染(二)
- Q&A——图形渲染(三)
- Q&A——图形渲染(一)
- Q&A——UI Mesh 渲染
- Q&A——渲染优化
- Q&A——资源管理(二)
- Q&A——UI输入(二)
- Q&A——性能优化(二)
- Q&A——内存管理(二)
- Q&A——UI输入(二)
- Q&A——性能优化(二)
- 实时渲染(一)——图形渲染管线
- Unity图形渲染优化(二)
- Q&A——资源管理(六)
- Q&A——资源管理(七)
- Q&A——资源管理(八)
- Q&A——资源管理(九)
- Q&A——资源管理(十)
- 用vue开发一个猫眼电影web app
- C# Jpush 极光推送消息推送教程
- FFmpeg
- Vue.js 实用技巧(二)
- 基于protobuf service使用rpc入门教程
- Q&A——图形渲染(二)
- vue获取input输入值的问题
- 1002.写出这个数(20)
- 进阶vue全家桶
- redis安装
- Q&A——资源管理(二)
- 【干货】Windows 服务器系统日志分析及安全
- 让ie支持html5标签
- ZooKeeper使用(1)- 简介


