用Go重构WEB请求分析跟踪服务
来源:互联网 发布:js如何获取子元素内容 编辑:程序博客网 时间:2024/06/05 13:24
在Skroutz,我们严重依赖网页分析来进行关键业务和技术决策。 从网页浏览收集的数据可以用于计算商店产品转换率,提取商业智能,制定个性化建议和预测的原材料。
随着访问流量在过去几年中稳步增长,我们面临一些挑战,促使我们重新设计我们业务的关键部分:网站数据分析跟踪系统
网站数据分析跟踪系统1.0
从网站上采集数据信息通常涉及使用web beacons(信标),这是一个花哨的名字,就像为无形的图像注入html标签。
一个类似beacon的例子如下:
<img width="1" height="1" src="https://www.scrooge.co.uk/track?foo=bar"></img>将这样的片段添加到我们要跟踪的页面中, 之后每次Web浏览器都会访问这些页面,它通过向www.scrooge.co.uk/track?foo=bar发出请求来获取图像,该请求将由我们的服务器处理,服务器将从查询字符串中获取跟踪数据。
在这种情况下,查询字符串是foo = bar, 这些是原始数据,在转换为更方便处理的格式后,我们的应用程序将数据存储起来供以后使用。 这实际上是Google Analytics(分析)的工作原理,以及Skroutz的网页分析工作。
这个博客的重点是跟踪请求到达我们的服务器后,直到数据被持续进行进一步分析。
最初
传统的实现方式相当简单,主要涉及我们的Rails应用程序。
跟踪请求由我们的Rails整体运行在Unicorn上。 这是一个适用于所有常规用户流量的应用程序(例如https://www.scrooge.co.uk/c/165/mobile_phones.html)。
我们目前在三个国家运营,每个国家都有自己部署的应用实例。 希腊的www.skroutz.gr,土耳其的www.alve.com和英国的www.scrooge.co.uk。 每个实例都有自己的应用服务器,数据库和其他基础架构。
传入的查询参数将转换为JSON对象。 例如?foo = bar被转换为{“foo”:“bar”}。
然后使用阻塞调用将JSON对象保存在磁盘上的文件和Kafka中。(日志是原始存储,直到Kafka被添加到混合。
这种冗余是一个中间的情况,直到我们完全过渡到Kafka。直到这两个存储是同样重要的,因为有应用程序依赖于两者之一。Memcached被用作独角兽工作者之间的共享存储,用于执行正确和错误检查。)
以上所有这些都在HTTP请求生命周期内进行:浏览器请求 "/trace?foo = bar",数据保存到日志文件和Kafka之后,响应将发送回客户端。
流程如下图所示:
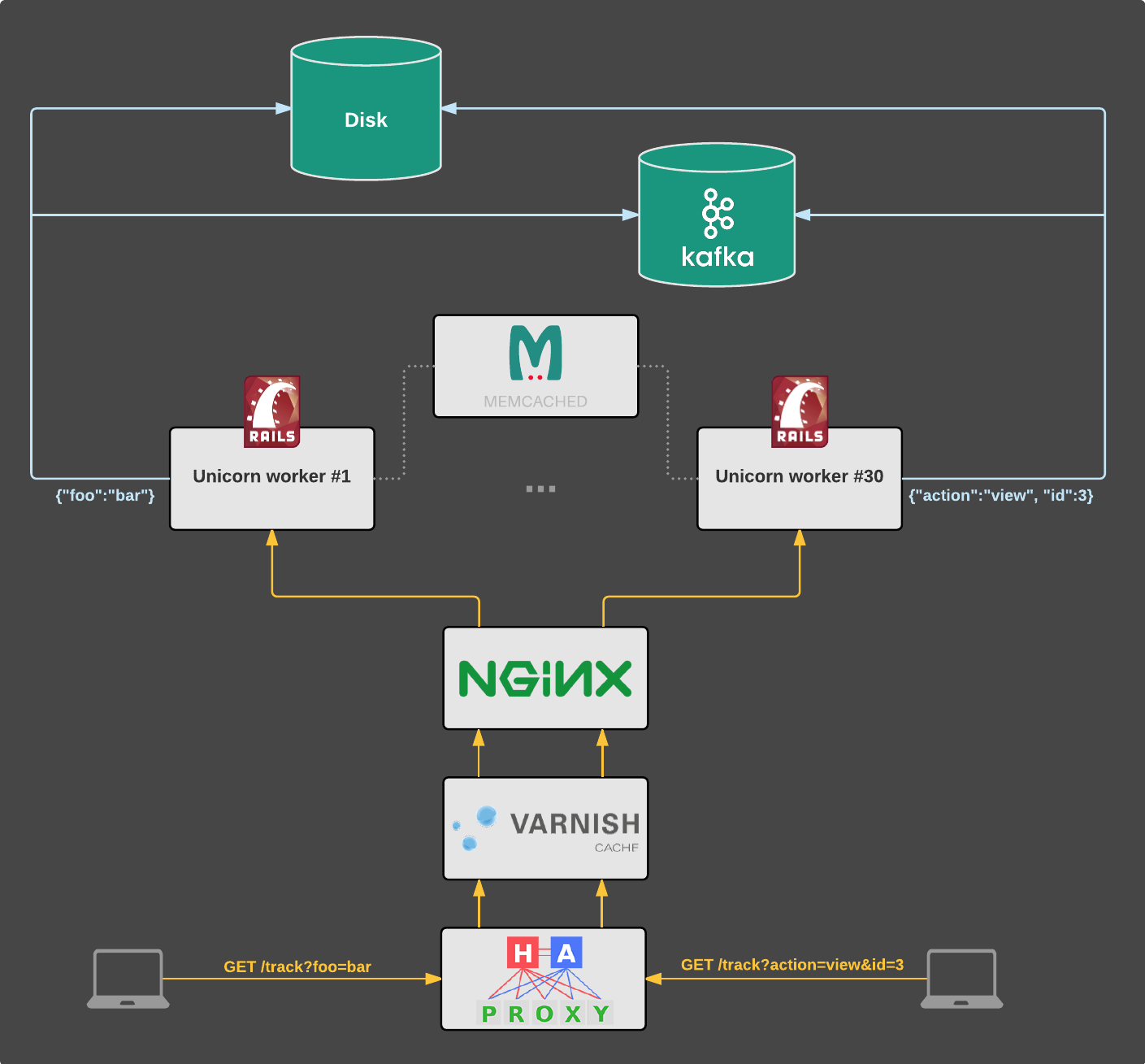
旧结构
虽然这个解决方案为我们服务好几年,但是入境流量不断增长,我们开始担心,因为我们知道有一些潜在的问题。
动机:为什么困扰?
最关键的问题是跟踪请求可能会导致应用程序挂掉不能为用户提供正常服务。 可能导致以下后果:
1.每个页面视图都会产生后续跟踪请求。
2.跟踪请求由提供常规用户流量的同一应用程序和服务器(例如,页面浏览,API调用)提供。
3.使用阻止调用,在跟踪请求生命周期内执行将数据保存到Kafka和日志文件。
4.每个独角兽工作者一次可以为一个客户服务。
这样糟糕的是,其中一个存储(即Kafka,NFS)的故障可能导致跟踪请求,迅速占据所有可用的Unicorn服务器,没有服务器为其他客户提供服务,导致停机。
这是不好的, 由于我们的网站数据分析跟踪出现问题,我们的用户体验可能会受损。
在软件架构方面,主要应用程序与可追溯性服务的耦合是不必要的。 虽然应用程序通常每天部署多次,但跟踪逻辑在几年内只会改变几次。 这导致开发人员不愿意改变可能以某种方式影响跟踪路径的内容(例如升级Kafka驱动程序)。
此外,请求没有必要通过整个Rails ,导致应用服务器中的资源和容量浪费。
除了这些问题之外,还有一个事实,就是没有强大的Ruby Kafka驱动程序存在。 我们使用了一些,但遇到了许多关键错误,而我们修复了其中一些错误,其他则需要进行重大改写。
显然是时候进行大修了。 我们决定退后一步,重新考虑问题,并提出更好的长期解决方案。
构建新系统
出现的第一个问题是“如果我们将跟踪逻辑提取到单独的服务怎么办?
假设我们这样做,跟踪路径的故障不会伤害用户体验,因为跟踪服务的停机不会导致主应用程序的停机。
这样做是很有道理的,用于收集网站分析的代码不需要与主应用程序的代码相结合。 跟踪部分可以被视为一个独立的系统,它接收HTTP请求作为输入,并产生JSON对象作为输出。
此外,与主应用程序分离的服务意味着它可以是多租户:单个实例可以为skroutz.gr,alve.com和scrooge.co.uk提供所有流量。
新系统应该是可靠的,可维护的,能够有效地处理数千个客户,并扩展我们的流量。 考虑到这些要求,我们可以对我们应该使用哪种工具做出明智的决定。
选择正确的工具
作为Ruby的重用户,这当然是我们考虑的第一个选择。 然而,我们知道,在MRI Ruby之上编写可扩展,高度并发的系统将是一个几乎不可能的任务。 即使我们这样做,结果也不一定优化,因为运行时没有内置的并发支持(加上有一个全局的VM锁),垃圾收集器将成为主要的障碍。
下一个选项是Go。 我们一直喜欢这种语言,它的哲学对我们来说是很有意义的。 由于以下原因,它似乎是一个理想的候选人:
·内置并发支持。
·简单:任何开发人员都可以快速接收该项目。 代码库将更容易维护。
·固体标准库:我们可以使用较少的外部依赖性,开发更可靠和可维护的系统。
·优秀的工具:建立这样的生产系统时,像数据竞赛检测器,执行追踪器,pprof,go vet和gofmt这样的工具是巨大的优势。
·文档:当有良好的文档存在时,该语言更容易使用。
总的来说,Go似乎是正确的工具。
scratchd: 新的实现
名称scratchd是“scratch daemon”的缩写,因为上述日志文件历史上被称为“scratch logs”。
新实现本质上是一个HTTP服务器和两个工作队列,一个用于将数据保存到日志文件,另一个用于将数据持久化到Kafka。 我们调用队列"backends",与HTTP服务器同时运行的协程,并负责持久化数据。
在不同渠道传递的核心实体是Line:
// Line corresponds to an incoming tracking request and contains the data// to be persisted.type Line struct { // Flavor specifies the instance to which the request corresponds to // (e.g. scrooge.co.uk). Flavor *Flavor // Values are the query parameters encoded in JSON. Values []byte // Time is the flavor-aware time the request was received. Time time.Time}backend的定义如下:
每个传入的请求都会产生一个新的Line值,然后传递给backends。 流程如下图所示:
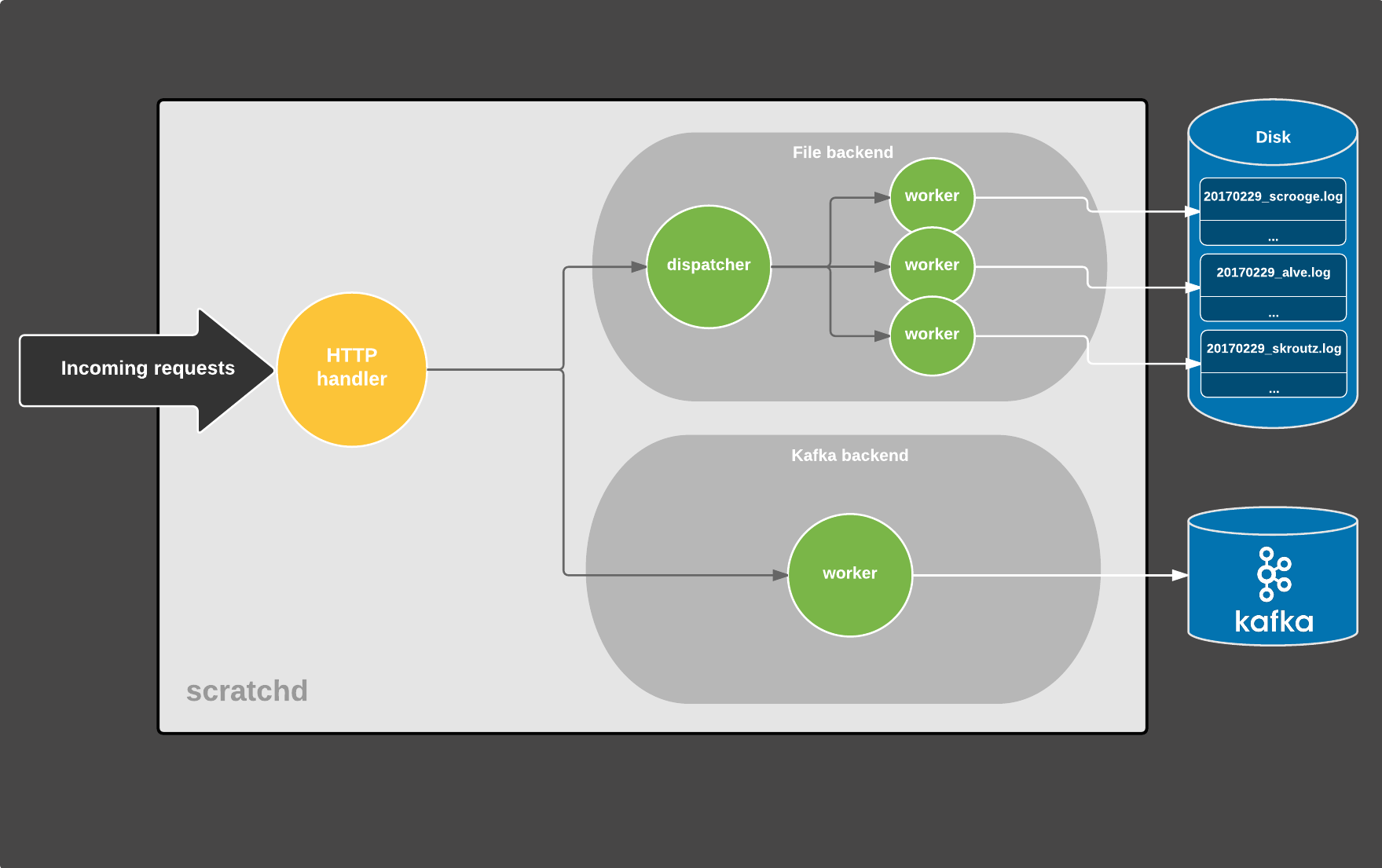
scratchd内部
每个圆是一个单独的协程,灰色箭头表示通过通道发送的Line值,而白色箭头是数据持续到某种存储。 (为了简单起见,实际上有更多的移动部件被取出)
HTTP请求生命周期的过程如下:
1.跟踪请求进入并由HTTP处理程序处理,HTTP处理程序执行以下任务:
·请求正确/错误检查,如果格式错误,请提前退出
·将查询参数转换为JSON
·创建一个Line值,并通过缓冲通道将其发送给backends进行持久化
·回应客户
2.同时,每个backend同时运行,并且由一个紧密的循环(调度程序)组成,它们从一个通道接收Line值,并相应地保持它们。
文件分派器通过单独的工作程序协程将数据写入文件。 每个worker负责写入某个文件(每天都有一个文件)。
Kafka backend由一个worker组成,他们将数据保存到Kafka。 由于它由librdkafka支持,它保留了自己的缓冲区并在引擎盖下使用了多个I / O线程,所以在Go空间中不需要进一步的并发。
在高层次上,系统由同时运行的三个主要组件和通过通道进行通信。
这种方法有很多优点:
首先,持久性backends是相互分离的。Kafka的失败不会对日志文件产生影响,反之亦然。这样做的结果是,由于失败,日志文件中的数据丢失,我们可以使用Kafka重新生成它们。
HTTP路径完全不受后端任何故障的影响:如果后台关闭,我们会收到通知,但用户不会注意到一件事情。
正在缓冲的通道意味着我们对任何类型的小问题(网络,Kafka,文件系统)都具有更强的弹性,因为作业将被缓冲一段时间,并最终由相应的后端处理。
Kafka驱动的明显选择是sarama,是目前最受欢迎的选择。 然而,由于我们是优秀的librdkafka的用户,我们经历了最强大的Kafka驱动程序实现。 利用librdkafka意味着驱动程序通常会比替代方案更快地获得错误修复和新功能。
Memcached的使用被一个常驻内存中的键值存储器所替代,它在几行代码中实现,并支持简单的GET / SET操作,TTL过期,只有字符串作为键/值。 虽然有其他缓存实现可用,但它们提供了比我们需要的更多功能,因此更复杂。
就配置而言,我们考虑了YAML,TOML和JSON。 由于事实上标准库中有一个实现,所以我们选择了更简单的JSON。 我们通过源代码中的完整文档,提高代码的可读性。
对于日志记录,我们使用标准库的记录器,其前缀与每个组件(http,kafka,file)对应。 输出由journald收集,然后将其转发到syslog。 我们可能会考虑logrus在未来(Sentry integration 很好),虽然我们还没有出售它。
测试
除了单元测试,我们主要使用集成测试:轮询服务器,向其发送用户请求并验证输出是否正确。在文件backend的情况下,我们验证在测试期间生成的日志文件是否正确。同样,我们使用专用的Kafka集群,通过消费相关的topics来验证Kafka后端的输出。
使用协程和标准库的测试框架进行此操作是相当简单的:在单独的协程中调用main(),并从TestMain()发出客户端请求。
我们没有使用任何外部库进行测试,因为testing包足够我们使用。在打印测试失败时,我们大量使用reflect.DeepEqual来比较预期和实际结果。最后,表驱动测试大大简化了实际的测试代码。
为了确保我们没有引入任何回归,我们根据旧的和新的实现重现了大量的生产请求,并验证了结果是一致的。
零停机部署
部署而不会失去任何流量是一个艰巨的要求。 这是先前由Unicorn处理的,并涉及到发送信号以控制一些Unicorn进程的自定义shell脚本。 该过程与nginx使用的过程类似。
我们利用systemd的socket激活, 这样我们就不必执行Unicorn和nginx所做的信号处理逻辑,而且我们摆脱了shell脚本。 go-systemd包使得这样做很轻松, 这个过程只是一个绑定和收听由systemd提供的socket,而不是创建一个新的socket。
我们还利用Go 1.8中添加的优雅的服务器关机功能,因为我们不希望在部署期间强制关闭使用中的连接。
零停机重新启动意味着零停机升级,因为升级是更换磁盘二进制文件并重新启动systemd服务的问题。
监控
除了强制性的Icinga和Munin监控,我们使用由Graphite支持的Grafana。 该服务提供一个HTTP统计endpoint,显示各种指标,其中一些是:
每个后端缓冲的作业数
每个后端中的持久性错误数
恶意/异常的请求数
运行时指标,通过runtime.MemStats(GC循环/暂停时间,内存分配等)
该服务维护由各种组件(比如backends, HTTP handler)同时更新的计数器的全局映射,因此我们大量使用sync/atomic,这不是理想的,但由于并发映射将被发送,所以情况会更好在Go 1.9的标准库中。
在cron中安排的脚本定期收集统计endpoint公开的指标,并将它们馈送给Graphite。
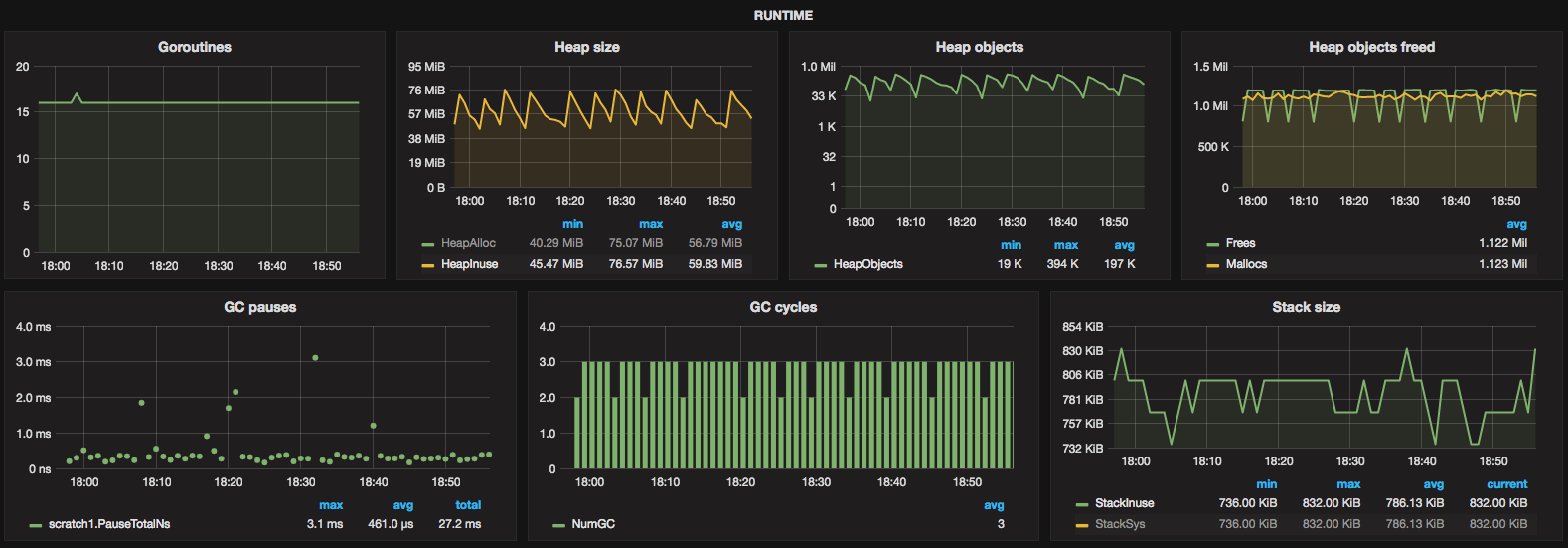
scratchd运行时指标
推出
我们是Debian的重用户,所以在我们这个案例中,所以我们做了安装服务就像运行一样简单:
$ apt-get install scratchd这样可以确保所有的依赖关系得到保护(即librdkafka),并且还提供默认配置文件和相应的systemd单元文件。 升级也很轻松:升级软件包并重新启动服务。
在初步部署过程中,我们利用了HAproxy被部署在任何backend服务之前的代理请求。 最初我们只切换了内部总部网络的流量,在验证一切正常工作后,我们代理了一小部分真正的用户流量,同时保留了旧版(Rails应用程序)服务。 我们逐渐增加新服务的流量,直到没有跟踪请求再次触发以前的实现。 这个策略帮助我们尽可能减少可能出现的潜在问题。
除此之外,没有理由使用nginx或Varnish,所以我们摆脱了它们。 新的结构现在减少到以下:
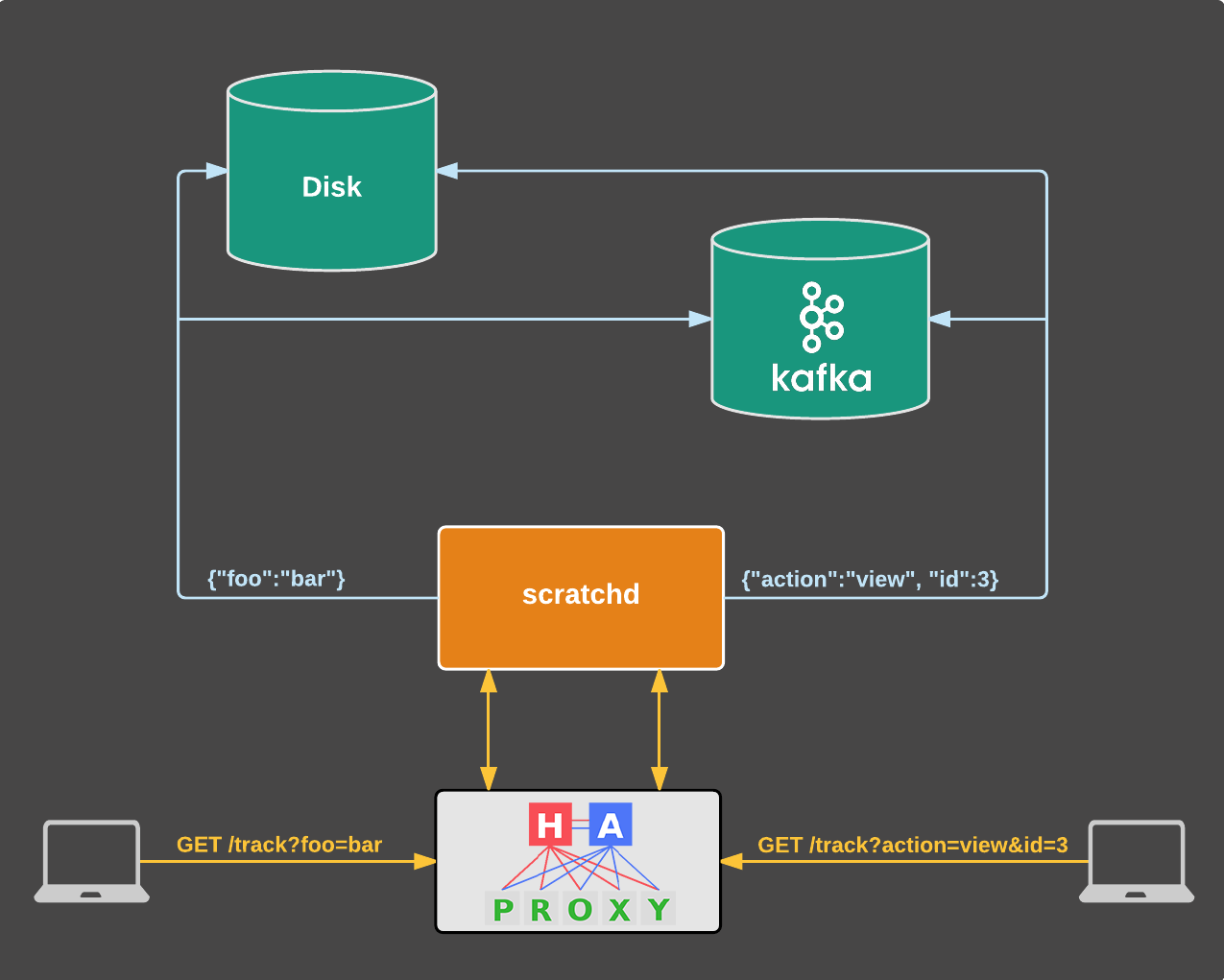
新结构
如果主要实例出现故障,HAproxy还会自动重定向所有流量。
结果一目了然
新的解决方案无缝地解决了我们以前的问题,并带来了额外的好处:
Web分析跟踪路径对主应用程序没有任何影响。Kafka或文件系统故障不会导致浏览www.skroutz.gr,www.alve.com或www.scrooge.co.uk的用户停机。
持久性backend彼此分离,这意味着Kafka的故障不会影响日志文件,反之亦然。
弹性:容错性更高。偶然的网络延迟或Kafka重新平衡意味着写入将被缓冲一段时间,最终将被刷新。这同样适用于日志文件。
效率:新服务的一个实例部署在一个虚拟机上,负责处理所有流量(目前来自三个国家),拥有60MB的内存占用空间,CPU利用率可忽略不计。我们的独角兽工人现在有更多的资源来提供网页请求。此外,对Kafka和磁盘的写入现在已经被缓存,因此总体压力较小。
多租户:这大大降低了运营成本,因为我们部署单个实例,监控单个服务,执行单个部署,在一个地方更新配置。
维护:新的结构比以前更简单,其中包括Unicorn,Rack,中间件,Rails,nginx,Varnish&Memcached。现在只有标准的库,两个简答的外部包和HAproxy。新结构中的更少层次意味着调试也变得更加容易。
该服务可以从其他前端(即与主Rails应用程序完全不同的应用程序)重用。
当我们部署抓捕时,我们注意到主要应用程序响应时间有所增加:
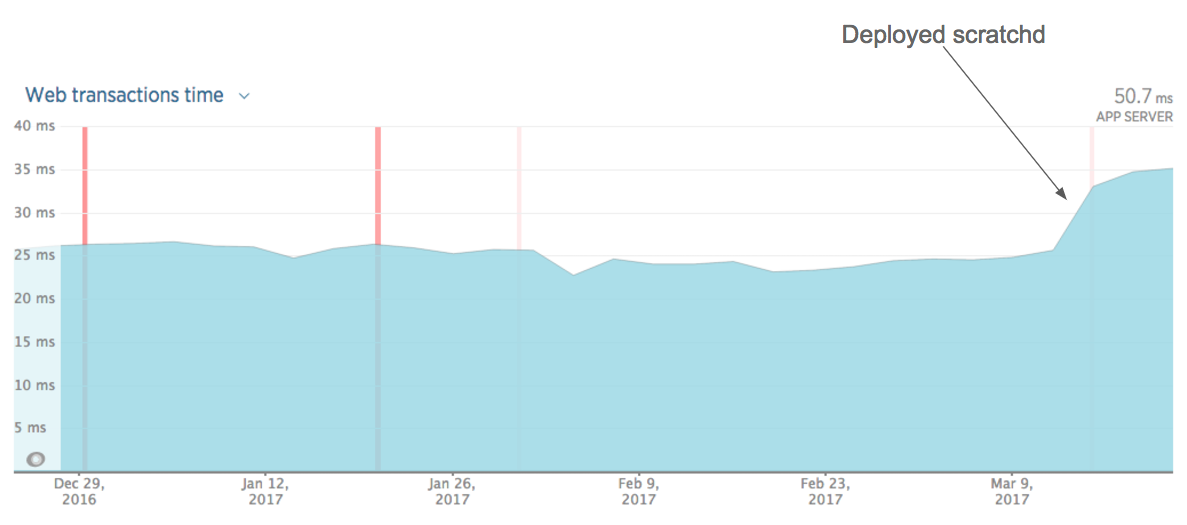
Rails应用程序响应时间
这是预料之中。 与常规网页请求相比,跟踪请求非常快。 与多个数据库查询,ElasticSearch查询,渲染Rails模板等相比,对Kafka和文件系统的写入工作很少,因此我们的NewRelic图形更能代表用户的实际体验。
最后,一些性能指标(假设一个单一的scratchd实例):
平均。 响应时间:1ms
当前传输:7k请求/分
估计容量:〜60k请求/分钟
内存占用:61MB
GC:470μs平均 暂停时间,1.2ms累计时间超过5min
CPU使用量可忽略
下一步是什么?
新方法解决了我们在过去实施中遇到的问题,并带来了额外的好处。这些不是免费的,当然,因为我们支付了新服务所需的仪器的成本(即监控,配置,部署)。这是我们高兴地采取的权衡,因为我们现在拥有一个更可靠,可维护和高效的系统。
也就是说,还有待完成的工作。我们计划添加基准测试,集成依赖管理工具,提高性能,指定部署过程,并建立组织中任何Go服务应达到的一些标准。
我们非常高兴能够在生产中运行。这是我们在生产中使用Go的第一步,揭示了这样一个系统的样子。我们探索了各种方法,并获得了在Go生态系统中如何访问日志记录,配置,测试和代码架构的经验,这使我们有信心使用该语言来解决其他问题。
- 用Go重构WEB请求分析跟踪服务
- go web服务(1)
- go web服务(2)
- Go web 服务简单使用
- web服务动态重配置
- web 页面请求分析
- go 运维,检测 web 服务状态
- GO实现简单的web服务功能
- Docker之搭建Go Web服务~~
- Go语言:REST Web服务调用
- Go 开发WEB服务之hello world
- Spring跨重定向请求传递数据跟踪实现
- Web服务请求异步化
- Web服务请求异步化
- Web服务安全性分析
- Go Web服务开发入门(一) -- 搭建简单web服务器
- Go web之旅(Request分析)
- Go Web编程:http包分析
- dp——洛谷P1136 迎接仪式
- java 异常分类
- Android RecyclerView嵌套RecyclerView并使用SwipeRefreshLayout导致未到顶部就触发下拉刷新
- eclips内存调整
- 初级web前端必备
- 用Go重构WEB请求分析跟踪服务
- Broadcast的使用以及在通知栏显示消息
- Maven学习 (三) 使用m2eclipse创建web项目
- iOS 关于自定义转场动画,以UITabBarController为例
- 奥威软件亮相“南方信息大会2017”----共道“融合、转型、夯实”
- Spring Boot 实现定时任务
- listview的item长按事件无效
- PHP学习笔记——二维数组(数组的数组)的声明与应用
- Essential Studio for ASP.NET MVC发布2017 v2,增加日期范围选择器功能


