实现全文机器翻译(一)
来源:互联网 发布:淘宝网用户体验报告 编辑:程序博客网 时间:2024/04/29 16:10
原作者:李松峰
原文地址
众成翻译三期计划实现全文机器翻译功能,背后的需求是把长期未被译者认领的文章,通过谷歌高级翻译API自动翻译出来,然后人工编辑、审校后发布。这样一方面可以消化累积的原文,另一方面也能增加产出。
乍一看,实现自动全文翻译,无非就是把文章以段为单位发给翻译API,拿到译文后再逐段替换回去就行了。
其实不然。
并非所有内容都要翻译,比如代码。代码有代码段和文本内的(行内)代码,都不能翻译。因此简单以段为单位翻译替换的想法行不通。
不仅如此,原文是Markdown格式,所以文本中的网址、图片地址也不能走API,但是链接文本和图片说明又必须翻译。比如[Please visit this link](http://www.very-good-domain-name.com/how-to-master-react-app-development.html)这个链接,“Please visit this link”要翻译,但“very-good-domain-name”和“how-to-master-react-app-development”不能翻译。
细思恐极。怎么办?只能借助Markdown解析和编译工具,比如marked,它能把Markdown转换成HTML。关于marked作为编译器的结构和原理,可以参考这篇文章:探究JavaScript上的编译器 —— marked。下面关于marked的架构图也摘自这篇文章:
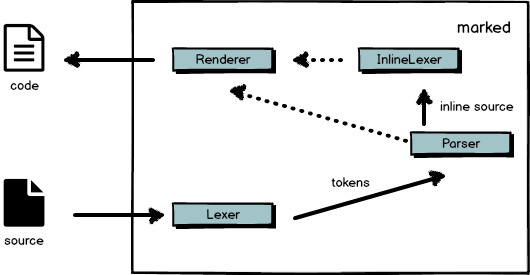
经分析,marked有两个切入点可资利用。本文先介绍利用第一个切入点的方案,而且这个切入点也正好能满足前述需求分析。
marked的第一个切入点是Renderer的text()方法:
据观察,作为“span level renderer”的text()负责处理所有文本。换句话说,需要翻译所有内容都要经过它,而且不需要翻译的内容不会经过它!简直完美,哈哈。
这么说来,只要在调用marked的时候重写text(),把它接收到的每段英文翻译成中文再返回就可以了,如下面的伪代码所示:
然而不行!marked是一个同步库,而调用API取得结果是个异步过程,这样注入的并不是异步调用的返回结果,而是“[object Promise]”这个字符串!(谷歌高级翻译支持Promise方式调用。)
怎么办?可以把marked重写为异步版,太花时间(或许以后有时间可以考虑)。一个变通方案是“用空间来换时间”:就是运行两遍marked,第一遍只收集英文text,然后在marked外部调用API完成翻译,第二遍再利用翻译结果同步替换英文text。
代码如下:
这个方案成功了,自动翻译结果如下:
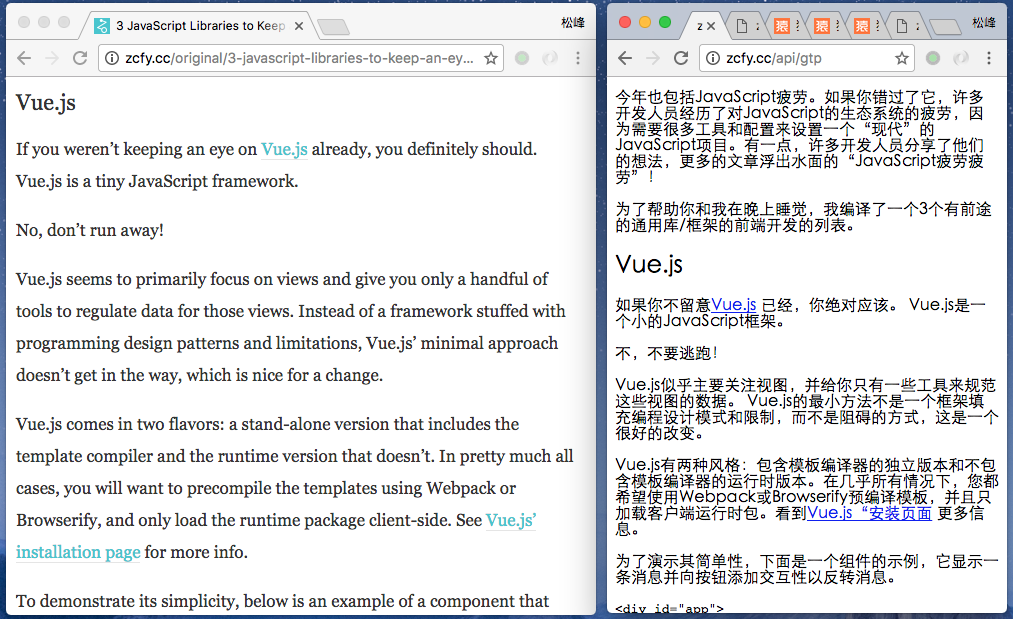
但新问题又暴露出来了。比如这句英文:
因为中间有一个链接,所以在通过text()方法时,会分三次调用,分别翻译:
- See
- Vue.js’ installation page
- for more info.
翻译结果组合起来就是:
本来是完整的一句话,硬分成三个片段分别翻译,理论上会丢失上下文,翻译结果应该不是最佳的。比如,把这句话完整地发给谷歌高级翻译,得到的结果是:
显然好多了。
为此,还要利用marked第二个可以利用的切入点,尝试解决这个问题。想知道marked的第二个切入点是什么,如何满足需求同时解决问题?敬请期待下一篇文章。
关于这个方案的代码,需要补记两个问题,请读者注意:
- 前面示例代码中的await sleep(1),并非Node.js内置的方法;
- 方案的完整实现应该包括错误补偿,即加上所谓的“指数退避”策略。
- 实现全文机器翻译(一)
- 面向机器翻译的全文检索系统
- 面向机器翻译的全文检索系统
- 实现Django的全文检索功能(一):选择Whoosh全文检索引擎
- 实现Django的全文检索功能(一):选择Whoosh全文检索引擎
- 神经网络机器翻译的实现
- 机器翻译(一):BLEU(bilingual evaluation understudy)
- 机器翻译 (NOIP2010)复赛 提高组 试题一 解题代码
- Sequence to Sequence 实现机器翻译(keras demo)
- 用compass实现站内全文搜索引擎(一)
- php + MongoDB + Sphinx 实现全文检索 (一)
- 用compass实现站内全文搜索引擎(一)
- 全文检索----新手入门(一)
- 1102: 机器翻译(translate)
- 1102: 机器翻译(translate)
- 机器翻译(待续)
- noip2010 机器翻译 (模拟)
- 机器翻译
- Git提交更新
- 零基础搭建vpn(好奇想玩玩linux)
- Unable to locate the Javac Compiler in 错误的解决办法之一
- tar 打包的时候如何去掉目录前缀
- 【leedcode】198. House Robber
- 实现全文机器翻译(一)
- linux上网设置
- python-多语言功能-读excel文件并写入json,解决json输出unicode
- Linux下Mysql安装后设置密码
- easyui datagrid 引用checkbox失效
- AppBarLayout+ToolBar+CollapsingToolbarLayout+NestedScrollView
- GreenDao中long型id
- Serizlizable
- T-SQL 查询 引用 了 指定列 的 所有 外键


