VBO与PBO,DMA异步快速传递
来源:互联网 发布:图像压缩编码编程 编辑:程序博客网 时间:2024/05/21 20:26
VBO(Vertex Buffer Array): OpenGL存储顶点数据的高速缓存,可减少渲染时间,相关APIs如下(OpenGL ES 2.0以上)
1234
GLES20.glGenBuffers(1, vboId, 0);//申请GLES20.glBindBuffer(GLES30.GL_ARRAY_BUFFER, vboId[0]);//绑定GLES20.glBufferData(GLES30.GL_ARRAY_BUFFER, vertexBuffer.capacity() * 4, vertexBuffer, GLES30.GL_STATIC_DRAW); //存储 GLES20.glBindBuffer(GLES30.GL_ARRAY_BUFFER, 0); //解绑
PBO(Pixel Buffer Object):OpenGL存储像素数据的高速缓存,可实现快速的像素数据传递,减少数据的拷贝/传递时间,相关APIs如下(OpenGL ES 3.0以上)
1234567
GLES30.glReadBuffer(GLES30.GL_BACK); //set framebuffer to read fromGLES30.glBindBuffer(GLES30.GL_PIXEL_PACK_BUFFER, mPboHandleContainer[0]); // bind pboGLES30.glReadPixels(0, 0, width, height, GLES30.GL_RGBA, GLES30.GL_UNSIGNED_BYTE, pboByteBuffer); // read pixelsByteBuffer byteBuffer =((ByteBuffer) GLES30.glMapBufferRange(GLES30.GL_PIXEL_PACK_BUFFER, 0, 4 * mWidth * mHeight, GLES30.GL_MAP_READ_BIT)).order(ByteOrder.nativeOrder()); // map pbo to bbGLES30.glUnmapBuffer(GLES30.GL_PIXEL_PACK_BUFFER);// unmap pboGLES30.glBindBuffer(GLES30.GL_PIXEL_PACK_BUFFER, 0);// unbind pbo
PBO DMA异步快速传递原理及多缓存对象设计
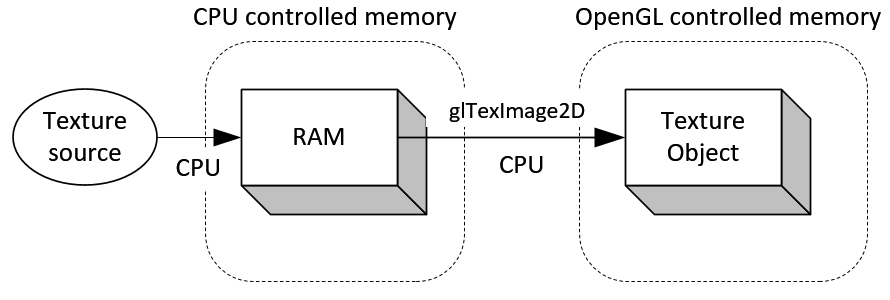
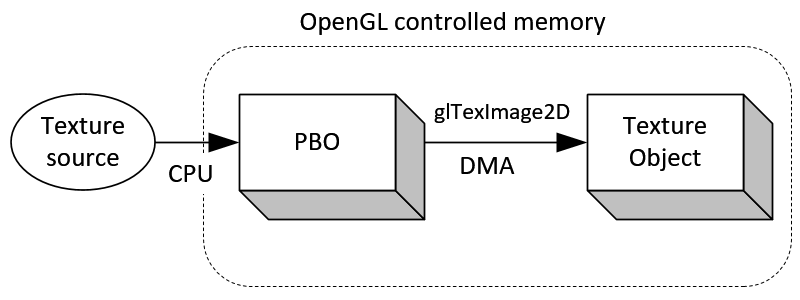
- 如下面两图所示,其中上图是传统的方法从图像源载入图像数据到纹理对象的过程,像素数据首先存到系统内存中,接着使用glTexImage2D将数据从系统内存拷贝到纹理对象,包含的两个子过程均需要有CPU执行;而下图中,像素数据是直接载入到PBO中,这个过程仍需要CPU来执行,但是从数据从PBO到纹理对象的过程则由GPU来执行DMA,不需要CPU参与。而且opengl可安排异步DMA,不必马上进行像素数据的传递。因此,相比而言,下图中的glTexImage2D立即返回而不是马上执行,这样CPU可以执行其它的操作而不需要等待像素数据传递的结束。
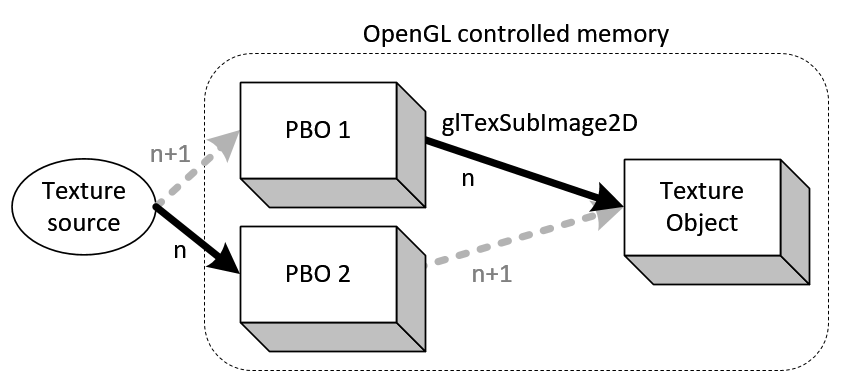
- 如下图所示表示同时使用了两个PBO。在glTexSubImage2D将像素数据从PBO拷贝出来的同时,另一份像素数据写进了另一个PBO。即在第n帧时,PBO1用于glTexSubImage2D,而PBO2用于生成一个新的纹理对象了。再到n+1帧时,两个PBO则互换了角色。由于异步DMA传递,像素数据的更新和拷贝过程可同时进行,即CPU将纹理源更新到PBO,同时GPU将从另一PBO中拷贝出纹理,从而提高处理速度。
阅读全文
0 0
- VBO与PBO,DMA异步快速传递
- VBO, PBO与FBO
- VBO, PBO与FBO
- OpenGL VBO, PBO与FBO
- OpenGL VBO, PBO与FBO
- OpenGL VBO, PBO与FBO
- 【转】VBO, PBO与FBO
- VBO, PBO与FBO(三)
- VBO, PBO与FBO(二)
- VBO, PBO与FBO(一)
- VBO, PBO与FBO(一)
- VBO, PBO与FBO(二)
- VBO, PBO与FBO(三)
- VBO,PBO,FBO
- VAO, VBO, PBO, FBO
- OPENGL VBO,FBO和PBO
- OpenGL之VBO,PBO,FBO技术
- OpenGL之VBO,PBO,FBO技术
- iOS
- android 之 service
- Android 用MultiImageSelector实现单图/多图+压缩
- Java线程同步阻塞, sleep(), suspend(), resume(), yield(), wait(), notify()
- CentOS7.3 安装 MySQL5.7.18 RPM Bundle
- VBO与PBO,DMA异步快速传递
- 【解题报告】Educational Codeforces Round 21
- python对excel文件进行操作
- 观察者模式
- 使用kernel-package编译内核imgage包
- android 之 Intent、broadcast
- Android Studio 2.3 签名打包问题
- 复习fragment的生命周期
- USACO-Section1.2 Palindromic Squares


