隐因子分解机Factorization Machine
来源:互联网 发布:51单片机流水灯原理图 编辑:程序博客网 时间:2024/06/05 00:09
前言
Steffen Rendle于2012年提出FM模型,旨在解决稀疏矩阵下的特征组合问题。传统机器学习问题,一般仅考虑如何对特征赋予权重,而没有考虑特征间存在相互作用,FM模型的提出较好地解决了该问题。我在百度学术上搜索了FM模型的中文论文,发现只有少数几篇,中文博客也不是很多,所以就写了这篇笔记。
Factorization Machine原理
隐因子分解机(Factorization Machine,FM)旨在解决稀疏矩阵下的特征组合问题。先来考虑特征组合问题,传统线性回归基于以下模型:

从模型方程易见,各特征分量xi和xj是相互独立,但实际应用中存在以下这种问题,该例子来自美团点评技术团队博客-深入FFM原理与实践(http://tech.meituan.com/deep-understanding-of-ffm-principles-and-practices.html):
假设一个广告分类的问题,根据用户和广告位相关的特征,预测用户是否点击了广告。源数据如下
"Clicked?"是label,Country、Day、Ad_type是特征。由于三种特征都是categorical类型的,需要经过独热编码(One-Hot Encoding)转换成数值型特征。
由上表可以看出,经过One-Hot编码之后,大部分样本数据特征是比较稀疏的。上面的样例中,每个样本有7维特征,但平均仅有3维特征具有非零值。实际上,这种情况并不是此例独有的,在真实应用场景中这种情况普遍存在。例如,CTR/CVR预测时,用户的性别、职业、教育水平、品类偏好,商品的品类 等,经过One-Hot编码转换后都会导致样本数据的稀疏性。特别是商品品类这种类型的特征,如商品的末级品类约有550个,采用One-Hot编码生成 550个数值特征,但每个样本的这550个特征,有且仅有一个是有效的(非零)。由此可见,数据稀疏性是实际问题中不可避免的挑战。
One-Hot编码的另一个特点就是导致特征空间大。例如,商品品类有550维特征,一个categorical特征转换为550维数值特征,特征空间剧增。
同时通过观察大量的样本数据可以发现,某些特征经过关联之后,与label之间的相关性就会提高。例如,“USA”与“Thanksgiving”、“China”与“Chinese New Year”这样的关联特征,对用户的点击有着正向的影响。换句话说,来自“China”的用户很可能会在“Chinese New Year”有大量的浏览、购买行为,而在“Thanksgiving”却不会有特别的消费行为。这种关联特征与label的正向相关性在实际问题中是普遍 存在的,如“化妆品”类商品与“女”性,“球类运动配件”的商品与“男”性,“电影票”的商品与“电影”品类偏好等。因此,引入两个特征的组合是非常有意义的。
这时FM就出来了,我们将模型方程改写如下:

即
最后一部分将两个互异特征分量之间的相互作用关系也考虑了进来,用factor来描述特征分量之间的关系,与LR中的交叉组合特征类似。这就是FM名字的由来。
这时还有一个问题,由于数据十分稀疏,而学习wij需要大量的<xi,xj>都非零的样本对,这时直接学习w有可能不准确。我们将方程进一步改写如下:

这种思路来源于推荐算法中的矩阵分解,类似的,我们可以得到W=VVT,通过学习隐含主题向量来间接学习W矩阵,重点在于减少了学习参数的个数,而VVT又能表达W(见主成分分析PCA),针对了训练数据不足而学习参数过多的问题,我们仅需学习|V|个参数,而不用学习|W|个参数。

FM模型学习算法
Factorization Machines 学习笔记(四)学习算法:http://blog.csdn.net/itplus/article/details/40536025。假设我们用梯度下降(SGD)算法学习FM模型,有

公式很好懂,每次更新的参数有w0,wl和vlm,分别求这三者的梯度,然后更新它们的值。假设我们损失函数取 ,则每次更新操作如下(这里用梯度下降法,θ初值设定较大):
,则每次更新操作如下(这里用梯度下降法,θ初值设定较大):
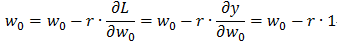


其中r 是学习率,控制每次更新步长。
FM模型与推荐系统
假设这样一个问题:

我们求Movie的标签(例如:点击量/票房),表中的数值是系统注册观众对于电影的评分(例如:豆瓣),而考虑到观众两两间对于电影的讨论可能会影响评分,我们可以上一个factor来估计这种影响。当然,FM模型还可以上升到更复杂的模型,例如:w·x1·x2·x3,来表达3个用户之间的相互影响。
libFM开源库
官网:http://www.libfm.org/
github:https://github.com/srendle/libfm
使用说明:http://www.libfm.org/libfm-1.42.manual.pdf
Reference
深入FFM原理与实践
Factorization Machines 学习笔记(四)学习算法 (应该说是一系列)
基于分布式随机优化方案的推荐模型算法 张宇
- 隐因子分解机Factorization Machine
- 隐因子分解机Factorization Machine
- 推荐系统学习笔记之四 Factorization Machines 因子分解机 + Field-aware Factorization Machine(FFM) 场感知分解机
- 简单易学的机器学习算法——因子分解机(Factorization Machine)
- 简单易学的机器学习算法——因子分解机(Factorization Machine)
- #####好######简单易学的机器学习算法——因子分解机(Factorization Machine)
- 素因子分解 Prime factorization
- LightOJ 1035 Intelligent Factorial Factorization 因子分解水题
- Factorization Machine
- 因子分解机
- 分解机(Factorization Machines)推荐算法
- LightOJ 1035 Intelligent Factorial Factorization [预处理+一半的 质因子分解]【数论】
- Factorization Machine算法
- FM(factorization machine)
- 【推荐系统】Factorization Machine
- 因子分解
- 因子分解
- 因子分解
- Android 网络通讯 socket tcp/ip udp http之间的关系
- String类中的equals方法与Object类中equals方法的区别
- Spring解决乱码问题
- 之江学院2017ACM 校赛Problem D: qwb与神奇的序列
- 清除浏览器缓存js文件的几种方法
- 隐因子分解机Factorization Machine
- 为什么虚拟DOM更胜一筹
- Android的四种启动方式
- phpstorm使用记录贴
- 密码存储中MD5的安全问题与替代方案
- Java编程热门问题总结——编程技巧篇
- FireBird C# 帮助类
- 更精确地使用浮点数
- 利用nohup来开启python文件


