python中常用的九种预处理方法分享
来源:互联网 发布:影音先锋替代软件 编辑:程序博客网 时间:2024/05/21 21:41
python中常用的九种预处理方法分享
本文总结的是我们大家在python中常见的数据预处理方法,以下通过sklearn的preprocessing模块来介绍;
1. 标准化(Standardization or Mean Removal and Variance Scaling)
变换后各维特征有0均值,单位方差。也叫z-score规范化(零均值规范化)。计算方式是将特征值减去均值,除以标准差。
一般会把train和test集放在一起做标准化,或者在train集上做标准化后,用同样的标准化器去标准化test集,此时可以用scaler
实际应用中,需要做特征标准化的常见情景:SVM
2. 最小-最大规范化
最小-最大规范化对原始数据进行线性变换,变换到[0,1]区间(也可以是其他固定最小最大值的区间)
3.规范化(Normalization)
规范化是将不同变化范围的值映射到相同的固定范围,常见的是[0,1],此时也称为归一化。
将每个样本变换成unit norm。
得到:
可以发现对于每一个样本都有,0.4^2+0.4^2+0.81^2=1,这就是L2 norm,变换后每个样本的各维特征的平方和为1。类似地,L1 norm则是变换后每个样本的各维特征的绝对值和为1。还有max norm,则是将每个样本的各维特征除以该样本各维特征的最大值。
在度量样本之间相似性时,如果使用的是二次型kernel,需要做Normalization
4. 特征二值化(Binarization)
给定阈值,将特征转换为0/1
5. 标签二值化(Label binarization)
6. 类别特征编码
有时候特征是类别型的,而一些算法的输入必须是数值型,此时需要对其编码。
上面这个例子,第一维特征有两种值0和1,用两位去编码。第二维用三位,第三维用四位。
另一种编码方式
7.标签编码(Label encoding)
8.特征中含异常值时
9.生成多项式特征
这个其实涉及到特征工程了,多项式特征/交叉特征。
原始特征:
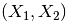
转化后:
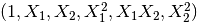
总结
以上就是为大家总结的python中常用的九种预处理方法分享,希望这篇文章对大家学习或者使用python能有一定的帮助,如果有疑问大家可以留言交流。原文地址http://www.jb51.net/article/92408.htm
- python中常用的九种预处理方法分享
- python中常用的九种预处理方法分享
- sklearn中常用的数据预处理方法
- python中常见的数据预处理方法
- 一些常用python预处理方法
- 一些常用python预处理方法
- 常用的数据预处理方法
- sklearn中常用数据预处理方法
- sklearn中常用数据预处理方法
- sklearn中常用数据预处理方法
- sklearn中常用数据预处理方法
- 文本建模常用的预处理方法
- 【Trick】数据预处理的常用方法
- 分享Jsp中Request对象常用的一些方法
- 分享iOS中常用的绘图, 截屏方法
- python中列表的常用方法
- python中字典的常用方法
- python中字符串的常用方法
- Python 发送带附件的邮件
- Android常用开源项目(七)
- PCA和协方差的理解
- Node.js搭建博客步骤(express+swig+mongoose+body-parser)
- 约瑟夫问题
- python中常用的九种预处理方法分享
- 轻音乐 钢琴曲 搜集
- 通过iptables防火墙降低cc攻击
- 使用SoapUI 测试Web Service
- 让404页面变得更加实用
- Conversion to Dalvik format failed with error 1
- k-近邻算法
- 项目中使用百度地图记录
- JavaWeb——程序开发体系结构


