用最简单的神经网络识别手写数字
来源:互联网 发布:软件错误代码c0000005 编辑:程序博客网 时间:2024/06/04 22:04
在上一篇文章中我们用Softmax Regression进行了手写数字的识别,精度达到了92%,非常的鼓舞人心。现在让我们进入神经网络的世界,用一个最简单的神经网络来进行手写数字的识别,数据集还是选择MNIST。因为图片的大小是28 * 28像素,所以需要784个输入神经元。输出是0~9这10个数字,所以用10个神经元作为output layer。既然是最简单的神经网络,那我们就只用1层的hidden layer,神经元的个数经过多次试验,最终选择了15个,此时精度最高。网络结构如下图所示:
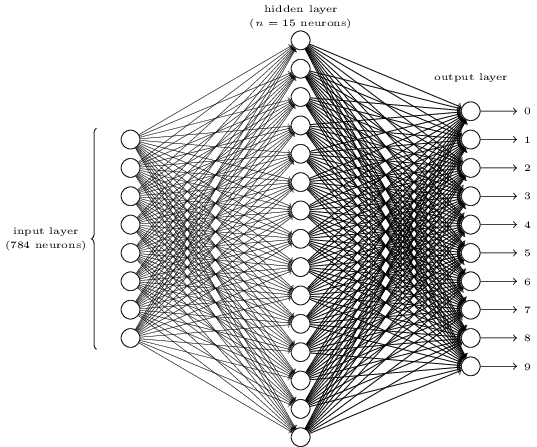
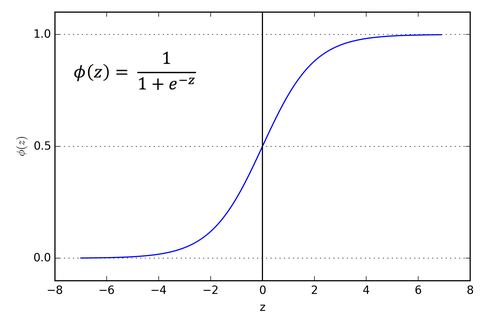
每个神经元的激活函数选择常用的sigmoid函数:

其取值范围为(0, 1),如下图所示:
对于神经网络的输出,我们利用Softmax函数将其归一化,之后计算它和真实值的交叉熵,用作成本函数,再利用随机梯度下降法训练出参数。TensorFlow代码如下:
import tensorflow as tffrom tensorflow.examples.tutorials.mnist import input_data# Import datamnist = input_data.read_data_sets('input_data', one_hot=True)# Create the modelhidden_layer_count = 15x = tf.placeholder(tf.float32, [None, 784])y = tf.placeholder(tf.float32, [None, 10])# hidden layerw1 = tf.Variable(tf.zeros([784, hidden_layer_count]))#w1 = tf.random_normal([784, hidden_layer_count], mean=0, stddev=1)b1 = tf.Variable(tf.zeros([hidden_layer_count]))a1 = tf.sigmoid(tf.matmul(x, w1) + b1)# output layerw2 = tf.Variable(tf.zeros([hidden_layer_count, 10]))b2 = tf.Variable(tf.zeros(10))a2 = tf.sigmoid(tf.matmul(a1, w2) + b2)cross_entropy = tf.reduce_mean( tf.nn.softmax_cross_entropy_with_logits(labels=y, logits=a2))train_step = tf.train.AdamOptimizer(0.01).minimize(cross_entropy)sess = tf.Session()sess.run(tf.global_variables_initializer())# Trainfor i in range(100000): batch_xs, batch_ys = mnist.train.next_batch(10)sess.run(train_step, feed_dict={x: batch_xs, y: batch_ys}) if i%100 == 0: curr_loss = sess.run([cross_entropy], {x:batch_xs, y:batch_ys}) print("i: %s loss: %s"%(i, curr_loss)) '''if i%1000 == 0: correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(a2, 1)) accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) ret = sess.run(accuracy, feed_dict={x: mnist.test.images, y: mnist.test.labels}) print("i: %s accuracy: %s"%(i, ret))'''# Test trained modelcorrect_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(a2, 1))accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))print(sess.run(accuracy, feed_dict={x: mnist.test.images, y: mnist.test.labels}))相信看过上一篇文章的人都可以看懂这些代码,这里就不逐行解释了。代码运行的结果如下:

最终的精确度在80%左右。
因为代码里面有随机因素,所以每个人运行的结果会稍有不同。代码里有一些hyper-parameters是需要人工调整的,这些参数包括:hidden layer神经元的个数、学习率、每批训练样本的个数、训练的迭代次数、w和b的初始值。经过多次实验,最终hidden layer神经元的个数选择了15,学习率选择了0.01,每批训练样本的个数选择了10,训练的迭代次数选择了100000,w和b的初始值则简单的选择了0,达到了约80%的精确度。
更多文章请关注我的公众号:机器学习交流
阅读全文
0 0
- 用最简单的神经网络识别手写数字
- 神经网络:简单手写数字识别神经网络
- 用BP人工神经网络识别手写数字
- 使用神经网络识别手写数字
- 利用神经网络识别手写数字
- 初识神经网络--识别手写数字
- 简单BP神经网络分类手写数字识别0-9
- 四、用简单神经网络识别手写数字(内含代码详解及订正)
- Tensorflow之 CNN卷积神经网络的MNIST手写数字识别
- 使用TensorFlow重构神经网络的识别手写数字
- 第一章 用神经网络识别手写数字(第一节 感知器)
- 第一章 用神经网络来识别手写数字(1)
- 识别简单的数字,字母的手写识别框架
- 神经网络用于手写数字识别更新版
- 卷积神经网络(cnn) 手写数字识别
- 卷积神经网络CNN 手写数字识别
- 卷积神经网络(cnn) 手写数字识别
- 神经网络实现手写数字识别(MNIST)
- Linux的文件系统与路径表示
- 全排列
- eclipse选择版本
- XML解析
- POJ 1701 Dissatisfying Lift 笔记
- 用最简单的神经网络识别手写数字
- SVG 矢量图和矢量动画介绍
- 前端学习笔记3-js
- Lintcode65 Median of two Sorted Arrays solution 题解
- 存储过程
- 给一个分数求小数点后第n位是多少
- Spark Runtime解密
- 军事机密
- MATLAB画圆


