从HashMap到ConcurrentHashMap
来源:互联网 发布:win7网络连接有个红叉 编辑:程序博客网 时间:2024/06/13 14:58
从HashMap到ConcurrentHashMap
jdk1.8的HashMap
Java为数据结构中的映射定义了一个接口java.util.Map,此接口主要有四个常用的实现类,分别是HashMap、Hashtable、LinkedHashMap和TreeMap,类继承关系如下图所示:

- HashMap:它根据键的hashCode值存储数据,大多数情况下可以直接定位到它的值,因而具有很快的访问速度,但遍历顺序却是不确定的。 HashMap最多只允许一条记录的键为null,允许多条记录的值为null。HashMap非线程安全,即任一时刻可以有多个线程同时写HashMap,可能会导致数据的不一致。如果需要满足线程安全,可以用 Collections的synchronizedMap方法使HashMap具有线程安全的能力,或者使用ConcurrentHashMap。
- Hashtable:Hashtable是遗留类,很多映射的常用功能与HashMap类似,不同的是它承自Dictionary类,并且是线程安全的,任一时间只有一个线程能写Hashtable,并发性不如ConcurrentHashMap,因为ConcurrentHashMap引入了分段锁。Hashtable不建议在新代码中使用,不需要线程安全的场合可以用HashMap替换,需要线程安全的场合可以用ConcurrentHashMap替换。
- LinkedHashMap:LinkedHashMap是HashMap的一个子类,保存了记录的插入顺序,在用Iterator遍历LinkedHashMap时,先得到的记录肯定是先插入的,也可以在构造时带参数,按照访问次序排序。
- TreeMap:TreeMap实现SortedMap接口,能够把它保存的记录根据键排序,默认是按键值的升序排序,也可以指定排序的比较器,当用Iterator遍历TreeMap时,得到的记录是排过序的。如果使用排序的映射,建议使用TreeMap。在使用TreeMap时,key必须实现Comparable接口或者在构造TreeMap传入自定义的Comparator,否则会在运行时抛出java.lang.ClassCastException类型的异常。
对于上述四种Map类型的类,要求映射中的key是不可变对象。不可变对象是该对象在创建后它的哈希值不会被改变。如果对象的哈希值发生变化,Map对象很可能就定位不到映射的位置了。
HashMap的实现
从结构实现来讲,HashMap是数组+链表+红黑树(JDK1.8增加了红黑树部分)实现的,如下如所示。

从源码可知,HashMap类中有一个非常重要的字段,就是 Node[] table,即哈希桶数组,明显它是一个Node的数组。我们来看Node[JDK1.8]是何物。
static class Node<K,V> implements Map.Entry<K,V> { final int hash; //用来定位数组索引位置 final K key; V value; Node<K,V> next; //链表的下一个node Node(int hash, K key, V value, Node<K,V> next) { ... } public final K getKey(){ ... } public final V getValue() { ... } public final String toString() { ... } public final int hashCode() { ... } public final V setValue(V newValue) { ... } public final boolean equals(Object o) { ... }}Node是HashMap的一个内部类,实现了Map.Entry接口,本质是就是一个映射(键值对)。上图中的每个黑色圆点就是一个Node对象。
在理解Hash和扩容流程之前,我们得先了解下HashMap的几个字段。从HashMap的默认构造函数源码可知,构造函数就是对下面几个字段进行初始化,源码如下:
int threshold; // 所能容纳的key-value对极限 final float loadFactor; // 负载因子 int modCount; int size;首先,Node[] table的初始化长度length(默认值是16),Load factor为负载因子(默认值是0.75)
modCount字段主要用来记录HashMap内部结构发生变化的次数,主要用于迭代的快速失败。强调一点,内部结构发生变化指的是结构发生变化,例如put新键值对,但是某个key对应的value值被覆盖不属于结构变化。
在JDK1.8版本中,对数据结构做了进一步的优化,引入了红黑树。而当链表长度太长(默认超过8)时,链表就转换为红黑树,利用红黑树快速增删改查的特点提高HashMap的性能。
功能实现-方法
确定哈希桶数组索引位置
不管增加、删除、查找键值对,定位到哈希桶数组的位置都是很关键的第一步。
HashMap定位数组索引位置,直接决定了hash方法的离散性能。先看看源码的实现(方法一+方法二):
方法一:static final int hash(Object key) { //jdk1.8 & jdk1.7 int h; // h = key.hashCode() 为第一步 取hashCode值 // h ^ (h >>> 16) 为第二步 高位参与运算 return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);}方法二:static int indexFor(int h, int length) { //jdk1.7的源码,jdk1.8没有这个方法,但是实现原理一样的 return h & (length-1); //第三步 取模运算}这里的Hash算法本质上就是三步:取key的hashCode值、高位运算、取模运算。
对于任意给定的对象,只要它的hashCode()返回值相同,那么程序调用方法一所计算得到的Hash码值总是相同的。我们首先想到的就是把hash值对数组长度取模运算,这样一来,元素的分布相对来说是比较均匀的。但是,模运算的消耗还是比较大的,在HashMap中是这样做的:调用方法二来计算该对象应该保存在table数组的哪个索引处。
这个方法非常巧妙,它通过h & (table.length -1)来得到该对象的保存位,而HashMap底层数组的长度总是2的n次方,这是HashMap在速度上的优化。当length总是2的n次方时,h& (length-1)运算等价于对length取模,也就是h%length,但是&比%具有更高的效率。
下面举例说明下,n为table的长度。 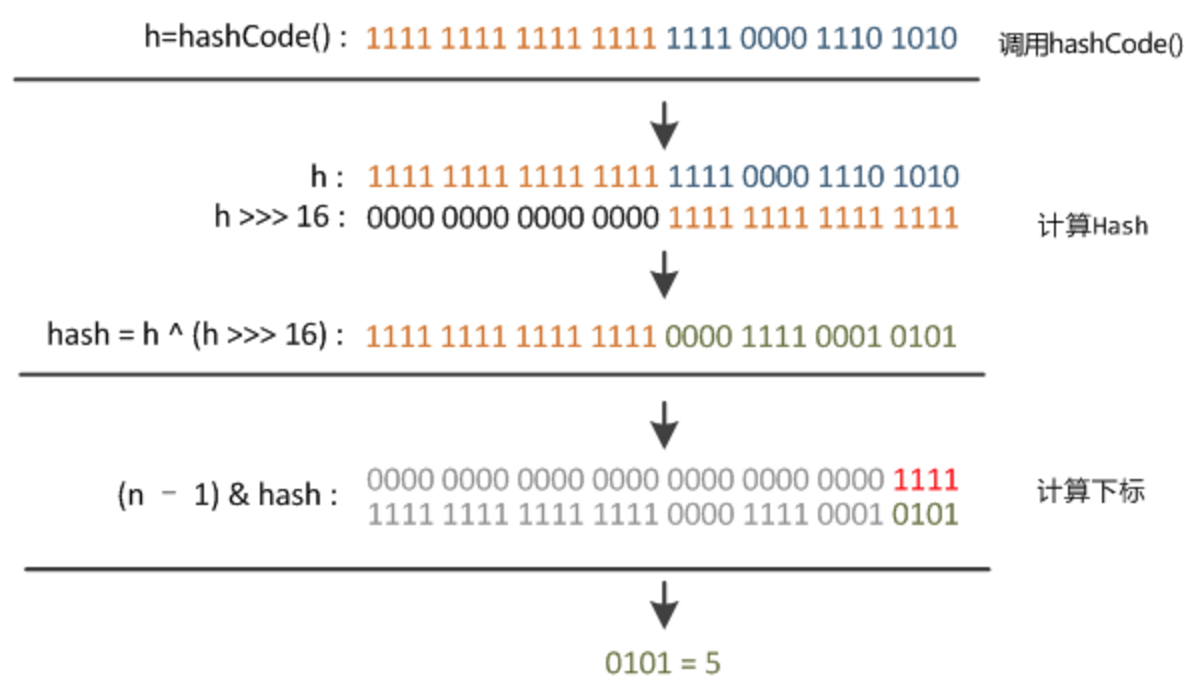
扩容机制
下面我们讲解下JDK1.8做了哪些优化。经过观测可以发现,我们使用的是2次幂的扩展(指长度扩为原来2倍),所以,元素的位置要么是在原位置,要么是在原位置再移动2次幂的位置。看下图可以明白这句话的意思,n为table的长度,图(a)表示扩容前的key1和key2两种key确定索引位置的示例,图(b)表示扩容后key1和key2两种key确定索引位置的示例,其中hash1是key1对应的哈希与高位运算结果。 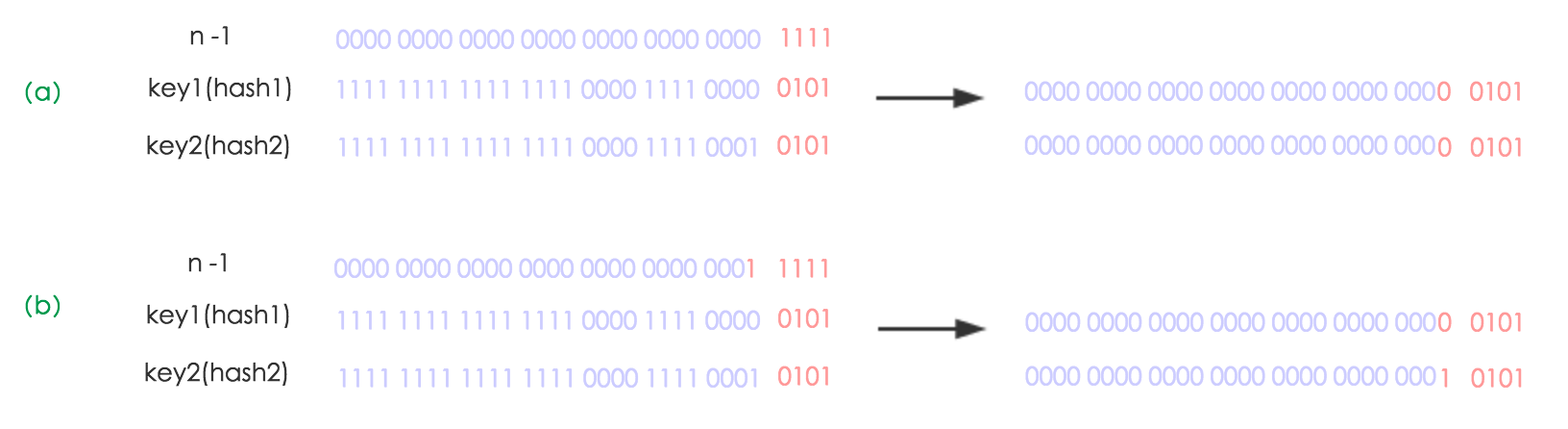
元素在重新计算hash之后,因为n变为2倍,那么n-1的mask范围在高位多1bit(红色),因此新的index就会发生这样的变化: 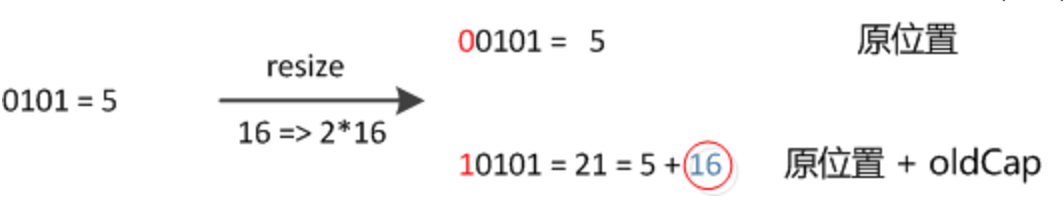
因此,我们在扩充HashMap的时候,不需要像JDK1.7的实现那样重新计算hash,只需要看看原来的hash值新增的那个bit是1还是0就好了,是0的话索引没变,是1的话索引变成“原索引+oldCap”。
总结:jdk1.8中node位置是hashcode&(length-1)获取的,扩容后length二进制高位由0变1,这时只需要检查原位置的node的hashcode,如果与length对应的高位是0的话,那么位置不变,如果是1的话那么位置为原索引+oldCap
- 从HashMap到ConcurrentHashMap
- hashmap&concurrenthashMap
- ConcurrentHashMap & HashMap
- 从源代码看TreeMap、HashMap、Hashtable、ConcurrentHashMap、LinkedHashMap特性
- HashMap——ConcurrentHashMap
- HashMap和ConcurrentHashMap浅析
- HashMap和ConcurrentHashMap浅析
- HashMap和ConcurrentHashMap
- HashMap和ConcurrentHashMap分享
- HashMap 与 ConcurrentHashMap
- HashMap,HashTable,ConcurrentHashMap,ConcurrentSkipListMap
- hashmap 和 concurrentHashMap
- HashMap与ConcurrentHashMap
- HashMap 和ConcurrentHashMap
- HashMap和ConcurrentHashMap比较
- concurrenthashmap和hashmap
- HashMap和ConcurrentHashMap分享
- HashMap和ConcurrentHashMap研究
- 排序相关算法
- META标签特效(页面过渡效果)
- 环形链表
- java应用基础
- 电话号码管理程序
- 从HashMap到ConcurrentHashMap
- mysql3与MySQL
- 基于OpenCV的harris角点检测
- [BZOJ3456] [多项式求逆] 城市规划
- 剑指offer 面试题47 不用加减乘除做加法
- Markdown添加空格效果
- 如何解决Failed to load class "org.slf4j.impl.StaticLoggerBinder".
- java线程池常见问题
- POJ 1734 Sightseeing trip 笔记


