spark优化
来源:互联网 发布:淘宝店家推广 编辑:程序博客网 时间:2024/06/03 20:30
1. 部分Executor不执行任务或task过多等待时间过长
(1) 任务partition数过少,
每个partition只会在一个task上执行任务。改变分区数,可以通过 repartition 方法,即使这样,在 repartition 前还是要从数据源读取数据,此时(读入数据时)的并发度根据不同的数据源受到不同限制,常用的大概有以下几种:
hdfs - block数就是partition数mysql - 按读入时的分区规则分partitiones - 分区数即为 es 的 分片数(shard)
那么如何增加你的 partition 的个数呢?如果你的 stage 是从 Hadoop 读取数据,你可以做以下的选项:
- 使用
repartition选项,会引发shuffle; - 配置
InputFormat,将文件分得更小; - 写入
HDFS文件时使用更小的block。
如果stage 从其他stage中获得输入,引发stage 边界的操作会接受一个 numPartitions的参数,比如
val rdd2 = rdd1.reduceByKey(_ + _, numPartitions = X) X 应该取什么值?最直接的方法就是做实验。不停的将 partition 的个数从上次实验的 partition个数乘以1.5,直到性能不再提升为止。
(2)任务partition数过多,task过多,在cores一定时Scheduler Delay时间加长
Spark使用CombineTextInputFormat缓解小文件过多导致Task数目过多的问题:http://www.cnblogs.com/yurunmiao/p/5195754.html
2. shuffle内存
Shuffle指的是从map阶段到reduce阶段转换的时候,即map的output向着reduce的input映射的时候,并非节点一一对应的,即干map工作的slave A,它的输出可能要分散跑到reduce节点A、B、C、D …… X、Y、Z去,就好像shuffle的字面意思“洗牌”一样,spark中已shuffle划分stage
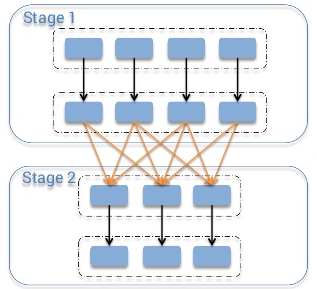
如果你的任务shuffle量特别大,同时rdd缓存比较少可以更改下面的参数进一步提高任务运行速度。
spark.storage.memoryFraction - 分配给rdd缓存的比例,默认为0.6(60%),如果缓存的数据较少可以降低该值。 spark.shuffle.memoryFraction - 分配给shuffle数据的内存比例,默认为0.2(20%)
剩下的20%内存空间则是分配给代码生成对象等。
如果任务运行缓慢,jvm进行频繁gc或者内存空间不足(20%程序运行),或者可以降低上述的两个值。 "spark.rdd.compress","true" - 默认为false,压缩序列化的RDD分区,消耗一些cpu减少空间的使用
shuffle block size limitation
http://litaotao.github.io/boost-spark-application-performance?s=inner
No Spark shuffle block can be greater than 2 GB — spark shuffle 里的 block size 不能大于 2g。

Spark 使用一个叫 ByteBuffer 的数据结构来作为 shuffle 数据的缓存,但这个 ByteBuffer 默认分配的内存是 2g,所以一旦 shuffle 的数据超过 2g 的时候,shuflle 过程会出错。影响 shuffle 数据大小的因素有以下常见的几个:
- partition 的数量,partition 越多,分布到每个 partition 上的数据越少,越不容易导致 shuffle 数据过大;
- 数据分布不均匀,一般是 groupByKey 后,存在某几个 key 包含的数据过大,导致该 key 所在的 partition 上数据过大,有可能触发后期 shuflle block 大于 2g;
一般解决这类办法都是增加 partition 的数量,
- sc.textfile 时指定一个比较大的 partition number
- spark.sql.shuffle.partitions
- rdd.repartition
- rdd.coalesce
TIPS:
在 partition 小于 2000 和大于 2000 的两种场景下,Spark 使用不同的数据结构来在 shuffle 时记录相关信息,在 partition 大于 2000 时,会有另一种更高效 [压缩] 的数据结构来存储信息。所以如果你的 partition 没到 2000,但是很接近 2000,可以放心的把 partition 设置为 2000 以上。
def apply(loc: BlockManagerId, uncompressedSizes: Array[Long]): MapStatus = { if (uncompressedSizes.length > 2000) { HighlyCompressedMapStatus(loc, uncompressedSizes) } else { new CompressedMapStatus(loc, uncompressedSizes) } }3. 并发
http://blog.csdn.net/lsshlsw/article/details/49155087
spark.default.parallelism
发生shuffle时的并行度,在standalone模式下的数量默认为core的个数,也可手动调整,数量设置太大会造成很多小任务,增加启动任务的开销,太小,运行大数据量的任务时速度缓慢。
spark.sql.shuffle.partitions
sql聚合操作(发生shuffle)时的并行度,默认为200,如果该值太小会导致OOM,executor丢失,任务执行时间过长的问题
速度变快主要是大量的减少了gc的时间。但是设置过大会造成性能恶化,
过多的碎片task会造成大量无谓的启动关闭task开销,还有可能导致某些task hang住无法执行,Scheduler Delay可能过多:http://litaotao.github.io/spark-sql-parquet-optimize
- 修改map阶段并行度主要是在代码中使用
rdd.repartition(partitionNum)来操作。
5. shuffle join优化
避免使用reduceByKey、join、distinct、repartition等会进行shuffle的算子,尽量使用map类的非shuffle算子
1-spark broadcast join优化
http://blog.csdn.net/chaosj/article/details/52964436
http://www.jianshu.com/p/2c7689294a73
举例
ipTable:需要进行关联的几千条ip数据(70k)
hist:历史数据(百亿级别)
直接join将会对所有数据进行shuffle,需要大量的io操作,相同的key会在同一个partition中进行处理,任务的并发度也收到了限制。
使用broadcast将会把小表分发到每台执行节点上,因此,关联操作都在本地完成,基本就取消了shuffle的过程,运行效率大幅度提高。
例如:
例1:
//读取ip表val df = ...//如果数据小于设定的广播大小则将该表广播,默认10Mdf.cache.count//注册表df.registerTempTable("ipTable")//关联sqlContext.sql("select * from (select * from ipTable)a join (select * from hist)b on a.ip = b.ip")......注意
- cache 的表不一定会被广播到Executor,执行map side join!!!
- 有另外一个参数:spark.sql.autoBroadcastJoinThreshold 会判断是否将该表广播;
- spark.sql.autoBroadcastJoinThreshold参数官方解释:
Configures the maximum size in bytes for a table that will be broadcast to all worker nodes when performing a join. By setting this value to -1 broadcasting can be disabled. Note that currently statistics are only supported for Hive Metastore tables where the command
- spark.sql.autoBroadcastJoinThreshold参数默认值是10M,所以只有cache的表小于10M的才被广播到Executor上去执行map side join,因此要特别要注意,因此在选择cache表的时候,要注意表的大小和spark.sql.autoBroadcastJoinThreshold参数的调整。如果内存比较充足,建议调大该参数。
例2:
http://blog.csdn.net/lsshlsw/article/details/50834858
数据1(个别人口信息):
身份证 姓名 ...110 lsw 222 yyy数据2(全国学生信息):
身份证 学校名称 学号 ... 110 s1 211111 s2 222112 s3 233113 s2 244期望得到的数据 :
身份证 姓名 学校名称110 lsw s1将少量的数据转化为Map进行广播,广播会将此 Map 发送到每个节点中,如果不进行广播,每个task执行时都会去获取该Map数据,造成了性能浪费。
对大数据进行遍历,使用mapPartition而不是map,因为mapPartition是在每个partition中进行操作,因此可以减少遍历时新建broadCastMap.value对象的空间消耗,同时匹配不到的数据也不会返回()。
import org.apache.spark.{SparkContext, SparkConf}import scala.collection.mutable.ArrayBufferobject joinTest extends App{ val conf = new SparkConf().setMaster("local[2]").setAppName("test") val sc = new SparkContext(conf) /** * map-side-join * 取出小表中出现的用户与大表关联后取出所需要的信息 * */ //部分人信息(身份证,姓名) val people_info = sc.parallelize(Array(("110","lsw"),("222","yyy"))).collectAsMap() //全国的学生详细信息(身份证,学校名称,学号...) val student_all = sc.parallelize(Array(("110","s1","211"), ("111","s2","222"), ("112","s3","233"), ("113","s2","244"))) //将需要关联的小表进行关联 val people_bc = sc.broadcast(people_info) /** * 使用mapPartition而不是用map,减少创建broadCastMap.value的空间消耗 * 同时匹配不到的数据也不需要返回() * */ val res = student_all.mapPartitions(iter =>{ val stuMap = people_bc.value val arrayBuffer = ArrayBuffer[(String,String,String)]() iter.foreach{case (idCard,school,sno) =>{ if(stuMap.contains(idCard)){ arrayBuffer.+= ((idCard, stuMap.getOrElse(idCard,""),school)) } }} arrayBuffer.iterator }) /** * 使用另一种方式实现 * 使用for的守卫 * */ val res1 = student_all.mapPartitions(iter => { val stuMap = people_bc.value for{ (idCard, school, sno) <- iter if(stuMap.contains(idCard)) } yield (idCard, stuMap.getOrElse(idCard,""),school) }) res.foreach(println)
2-mapValues代替map
明确key不会变的map,就用mapValues来替代,确保不调用shuffle:
A.map{case (A, ((B, C), (D, E))) => (A, (B, C, E))}
A.mapValues{case ((B, C), (D, E)) => (B, C, E)}6.代码
1. repartition和coalesce
这两个方法都可以用在对数据的重新分区中,其中repartition是一个代价很大的操作,它会将所有的数据进行一次shuffle,然后重新分区。
如果你仅仅只是想减少分区数,从而达到减少碎片任务或者碎片数据的目的。使用coalesce就可以实现,该操作默认不会进行shuffle。其实repartition只是coalesce的shuffle版本。
一般我们会在filter算子过滤了大量数据后使用它。比如将 partition 数从1000减少到100。这可以减少碎片任务,降低启动task的开销。
note1: 如果想查看当前rdd的分区数,在Java/Scala中可以使用rdd.partitions.size()
note2: 如果要增加分区数,只能使用repartition,或者把partition缩减为一个非常小的值,比如说“1”,也建议使用repartition。
2. mapPartitions和foreachPartitions
适当使用mapPartitions和foreachPartitions代替map和foreach可以提高程序运行速度。这类操作一次会处理一个partition中的所有数据,而不是一条数据。
mapPartition - 因为每次操作是针对partition的,那么操作中的很多对象和变量都将可以复用,比如说在方法中使用广播变量等。
foreachPartition - 在和外部数据库交互操作时使用,比如 Redis , MySQL 等。通过该方法可以避免频繁的创建和销毁链接,每个partition使用一个数据库链接,对效率的提升还是非常明显的。
note: 此类方法也存在缺陷,因为一次处理一个partition中的所有数据,在内存不足的时候,将会遇到OOM的问题。
3.reduceByKey和aggregateByKey
使用reduceByKey/aggregateByKey代替groupByKey。
reduceByKey/aggregateByKey会先在map端对本地数据按照用户定义的规则进行一次聚合,之后再将计算的结果进行shuffle,而groupByKey则会将所以的计算放在reduce阶段进行(全量数据在各个节点中进行了分发和传输)。所以前者的操作大量的减少shuffle的数据,减少了网络IO,提高运行效率。
4. mapValues
针对k,v结构的rdd,mapValues直接对value进行操作,不对Key造成影响,可以减少不必要的分区操作。
5. 当输入和输入的类型不一致时避免使用reduceByKey
举个例子,将(K,V)中相同K的value聚合在一起。一个方法是利用map 把每个元素的转换成一个 Set,再使用 reduceByKey将这些 Set 合并起来,这段代码生成了无数的非必须的对象,因为需要为每个 record 新建一个Set。
rdd.map(kv => (kv._1, new Set[String]() + kv._2)) .reduceByKey(_ ++ _)这里使用 aggregateByKey 更加适合,因为这个操作是在 map 阶段做聚合。
val zero = new collection.mutable.Set[String]()rdd.aggregateByKey(zero)( (set, v) => set += v, (set1, set2) => set1 ++= set2)6.在spark使用hbase的时候,spark和hbase搭建在同一个集群:
- Spark优化
- spark优化
- spark优化
- spark 优化
- Spark 优化
- spark优化
- Spark优化-优化原则
- Spark优化-优化数据结构
- 【Spark系列3】Spark优化
- [spark优化]如何优化数据结构
- Spark+Cassandra优化
- spark join broadcast优化
- Spark性能优化(1)
- Spark性能优化(1)
- Spark性能优化(2)
- Spark性能优化(3)
- spark配置优化
- Spark作业优化总结
- “GIS讲堂”第十课—WEBGIS中的地图图例
- 如何在有道云的markdown编辑器中高效的插入截图的外链
- Word2013正面页码显示在右侧,反面页码左侧显
- Linux 防火墙iptables命令详解
- Linux虚席笔记 --Samba
- spark优化
- Instantiating beans
- 虚拟机使用rememberedSet来避免全堆扫描
- git上传到github,从github上下载已存在的项目
- A. Snacktower
- 作为前端人员,css的这3个新特性你掌握了吗?
- 程序猿职业生涯的迷惘与野望
- Spark性能优化指南——基础篇
- 单片机外设LCD1602液晶屏的介绍


