如何做到优化引擎搜索SEO之第二篇:爬虫友好的页面
来源:互联网 发布:mysql数据管理软件 编辑:程序博客网 时间:2024/05/21 09:07
前文:《如何做到优化引擎搜索SEO(有HTML,关键字,Ajax,url,内容顺序等)》
英文原文来源:clickhelp博客
英文原文:Online Documentation and SEO. Part 2 - Crawler-Friendly Pages
下文均为翻译+自己的注解和想法
(所有ClickHelp打广告部分用浅灰色注解)
翻译:
首先是,爬虫。网络爬虫被搜索引擎用于网页通过URL进行请求的应用。因此,大多数搜索引擎在加载页面时不运行任何脚本…
怎么理解呢。就像是当你在浏览器中禁用脚本,和浏览页面(比如谷歌浏览器有可以设置禁止运行javascript的),如果一些严重依赖页面脚本呈现其内容的(如果用js来控制页面某些内容的显示),网络爬虫就会不完整或不正确的地显示页面。这样就算你做了搜索引擎优化,但是因为爬虫又不运行脚本,你的页面显示不全,做了优化和没做优化的结果差别并不大。
一个标准的网络爬虫的架构的样子: 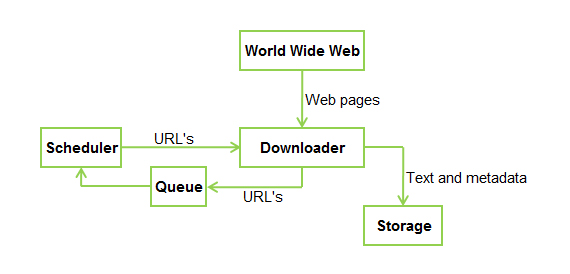
但这又不意味着你不能在你的在线文档中使用脚本。脚本可能会给一些不错的功能和视觉效果的帮助主题内容。在这一点上,对于搜索引擎来说,有一个禁止脚本的页面可以正确索引内容。
(然后就在ClickHelp,我们会注意这些细节,并确保网络爬虫获取主题内容正确。只要使用ClickHelp创建在线文档,你不需要担心网络爬虫不运行脚本啦~)【毕竟翻译人家的,顺便打个广告好做人嘛,但是就不放链接了】
另一个重要的注意——不要忘记metadata与robots name。这个meta标签的值可以显著改变web爬虫程序的行为。例如,<meta name = "googlebot" content = " noindex " / >可以防止页面被谷歌爬虫索引。
更重要的是注意有关robots的txt文件。(在第七篇)
自己的想法:
对于这一篇嘛。。爬虫没有接触过,也不了解它的机制是怎样的,根据图片,翻译下来是这样的 
不了解爬虫,这篇无法解释,还请各位自己去看原博加以理解。
- 如何做到优化引擎搜索SEO之第二篇:爬虫友好的页面
- 如何做到优化引擎搜索SEO之第三篇:meta标签的关键字(keywords)
- 如何做到优化引擎搜索SEO之第一篇:人类可读的url
- 如何做到优化引擎搜索SEO之第四篇:谷歌分析(Google Analytics)
- 如何做到优化引擎搜索SEO之第五篇:AJAX导航 & Hashbang
- 如何做到优化引擎搜索SEO之第六篇:内容顺序
- 如何做到优化引擎搜索SEO之第七篇:robots.txt
- 如何做到优化引擎搜索SEO之第八篇:懒加载图片(调整翻译)
- 如何做到优化引擎搜索SEO(有HTML,关键字,Ajax,url,内容顺序等)
- 搜索引擎优化(SEO)之对搜索引擎友好的网页设计
- ajax怎么做到seo友好
- 搜索优化之友好的网页设计制作
- 搜索可用性分析之三 如何让你的网站搜索最优化(SEO)?
- 如何开发一个SEO友好的网站
- SEO优化(增加搜索爬虫)
- SEO专题页面如何优化
- 移动SEO之页面优化
- web的Seo搜索优化
- android 内部打开微信
- Server:sffe是什么?
- IOS 38
- 说一说promise
- Spring框架中ModelAndView、Model、ModelMap的区别
- 如何做到优化引擎搜索SEO之第二篇:爬虫友好的页面
- IOS 39
- 线程的run和start
- Spark 性能相关参数配置详解
- Android 调用系统相机进行拍照 使用自带的图片选择器和裁剪工具
- sort的用法
- android 微信支付Demo遇到的问题,org.apache.http.legacy Library 的导入
- Linux下普通用户和超级用户的切换
- CC1310开发笔记-CY15B104Q


