高性能Mysql笔记 (6)---查询优化
来源:互联网 发布:windows无法启动按r 编辑:程序博客网 时间:2024/06/05 00:31
为什么查询会慢
是否向db请求了不需要的数据
需要10行但查询了100行 | 多表关联返回全部列 | 每次都是取出所有列
db是否扫描了额外的行
【推荐】SQL性能优化的目标:至少要达到 range 级别,要求是ref级别,如果可以是consts最好。
说明: 1)consts 单表中最多只有一个匹配行(主键或者唯一索引),在优化阶段即可读取到数据。
2)ref 指的是使用普通的索引。(normal index)
3)range 对索引进行范围检索。
反例:explain表的结果,type=index,索引物理文件全扫描,速度非常慢,这个index级别比较range还低,与全表扫描是小巫见大巫。
查询执行的基础
执行查询的过程: 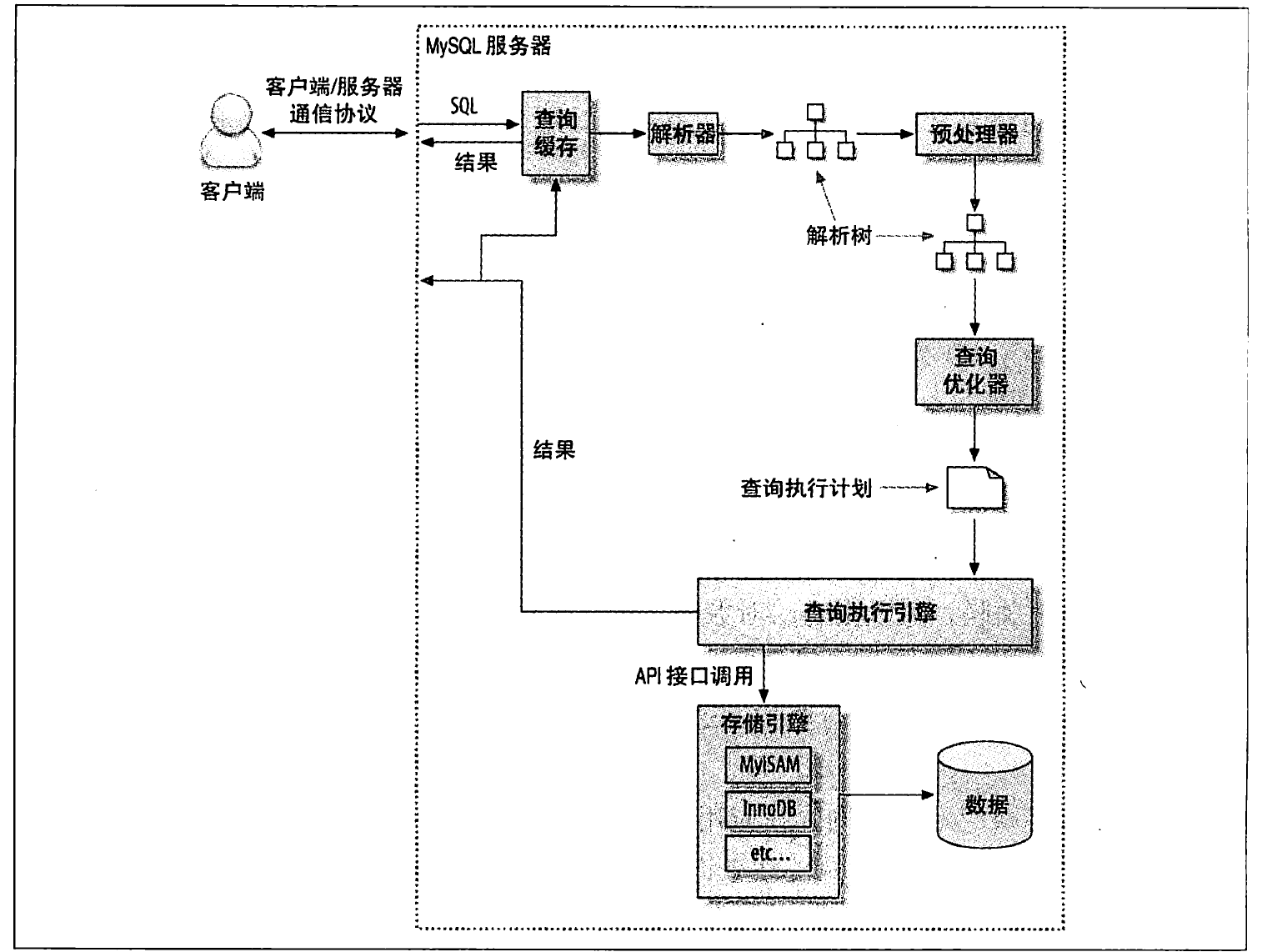
1)mysql 客户端和服务的连接是 半双工的。
2)查询优化器帮我们做的处理
语法解析&预处理 将sql语句 解析生成一颗树
最初 成本的最小单位是随机读取一个4K数据页的成本。现在已经变得很复杂了。
关联查询
mysql执行子查询时, 先将子查询的结果放到一个临时表中, 这个临时表不带任何索引, 然后将这个临时表当做普通表对待。

【推荐】in操作能避免则避免,若实在避免不了,需要仔细评估in后边的集合元素数量,控制在1000个之内。
排序优化
两次传输排序: 先读取行指针和需要排序的字段,排序完成后,再根据结果读取所需数据行
单次传输排序: 读取所有列,根据给定列直接排序。
查询优化器的局限性
重构查询的方式
在传统实现中总是强调 在db层完成尽可能多的事情。 因为之前总是认为网络通信、查询解析和优化是一件代价很高的事情。
现在mysql同时运行多个小查询已经不是什么问题啦。
用多个小查询代替大查询成为一种选择。
使用小查询的好处
缓存的效率更加高效 | 减少锁竞争 | 提升某些查询本身的效率
减小表之间的相互依赖 |减少冗余查询
我们自己需要优化的特定类型查询
1)count
count(col) 统计某个列值的数量,不会统计NULL
count(*) 忽略所有列, 直接统计所有的行数。
如果想知道结果集的行数 ,就使用count(*) ,它既清晰性能也更好。
【强制】不要使用count(列名)或count(常量)来替代count(),count()就是SQL92定义的标准统计行数的语法,跟数据库无关,跟NULL和非NULL无关。
说明:count(*)会统计值为NULL的行,而count(列名)不会统计此列为NULL值的行。
2)优化关联查询
确保on子句中的列上有索引。 如果关联顺序是 B A,就需要在A上建索引, B上不建索引。
只需要在关联顺序中的第二个表的相应列上创建索引。(嵌套循环关联)
确保group by 和 order by 只涉及一个表中的列。
尽可能使用 关联查询 代替 子查询
3)优化limit分页 

- 高性能Mysql笔记 (6)---查询优化
- 【高性能MySQL】查询优化
- 《高性能MySQL》之查询性能优化
- [Mysql]SQL 高性能查询优化语句
- 高性能MySql设计之查询优化
- 高性能MYSQL(查询优化)
- 高性能Mysql笔记 (7)---查询缓存
- 高性能Mysql笔记 (5)---索引优化
- MySQL 高性能优化笔记(一)
- 查询性能优化(高性能mysql读书笔记三)
- 《高性能MySQL》读书笔记--查询性能优化
- 《高性能MySQL》读书笔记--查询性能优化
- 《高性能mysql》之查询性能优化(第六章)
- 高性能MySql设计之查询优化(limit优化)
- 【高性能MySQL】读书摘录5-第6章、查询性能优化
- MySQL高性能优化
- 【学习笔记】《高性能MYSQL》对性能优化定义
- 高性能MySql进化论(十):查询优化器的局限性
- 让MFC的控件跟随当前windows风格
- Material Design之NavigationView的用法(抽屉式侧边栏)
- iOS UITextView详解 陌生属性解释,添加展示超链接并交互
- Android技能树
- 导包和整合
- 高性能Mysql笔记 (6)---查询优化
- 关于recycleView高度获取问题
- Spark性能调优(八)之Spark Tungsten-sort Based Shuffle
- 将所有文件的tab换成4个空格
- maven导入集中仓储中没有的jar包到本地仓储
- PHP常用函数
- 32 WebGL环境光下的漫反射光的计算
- tomcat7,8 centos7 配置apr极好教程
- vue.js如何更改默认端口号8080为指定端口


