Keras —— 功能API入门
来源:互联网 发布:淘宝号被冻结 编辑:程序博客网 时间:2024/05/20 23:03
Keras的功能API可用来定义复杂模型,如多重输出模型,有向无环图,或有共享层的模型。
请先熟悉Sequential模型的有关内容后再继续阅读。
一个例子:紧密连接网络
对于这种网络的实现Sequential模型是更好的选择,但我们这里用这个简单的例子来说明问题。
*一个层实例可调用(作用于张量),并返回一个张量。
*输入张量和输出张量可用来定义模型Model。
*该模型可被像Keras的Sequential模型一样训练。
from keras.layers import Input, Densefrom keras.models import Model# This returns a tensorinputs = Input(shape=(784,))# a layer instance is callable on a tensor, and returns a tensorx = Dense(64, activation='relu')(inputs)x = Dense(64, activation='relu')(x)predictions = Dense(10, activation='softmax')(x)# This creates a model that includes# the Input layer and three Dense layersmodel = Model(inputs=inputs, outputs=predictions)model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy'])model.fit(data, labels) # starts training
所有模型可如同层般调用
有了功能API,重复使用训练过的模型变得简单。可以把任意模型视为一个层,在一个张量上调用它。注意,调用一个模型不仅只重复使用该模型的结构,也重复使用它的权重。
x = Input(shape=(784,))# This works, and returns the 10-way softmax we defined above.y = model(x)
这使快速搭建可处理输入序列的模型变得可能。可只用一行代码将一个图像分类模型转变为视频分类模型。
from keras.layers import TimeDistributed# Input tensor for sequences of 20 timesteps,# each containing a 784-dimensional vectorinput_sequences = Input(shape=(20, 784))# This applies our previous model to every timestep in the input sequences.# the output of the previous model was a 10-way softmax,# so the output of the layer below will be a sequence of 20 vectors of size 10.processed_sequences = TimeDistributed(model)(input_sequences)
多重输入和多重输出模型
具有多重输入和输出的模型是有效利用功能API的一个好例子。它使操作大量互相牵连的数据流变得简便。
现在让我们来考虑这个模型。我们想预测在Twitter上一个新闻标题能够得到多少retweets和likes。模型的主要输入是标题自身,一串有序文字。为了使事情变得有趣,我们的模型有一些辅助输入,接收例如何时该标题被发布等信息。两个损失函数被用来监督该模型。在模型早期使用主损失函数对于深度网络来说是一个好的正则化方法。
模型图示如下:
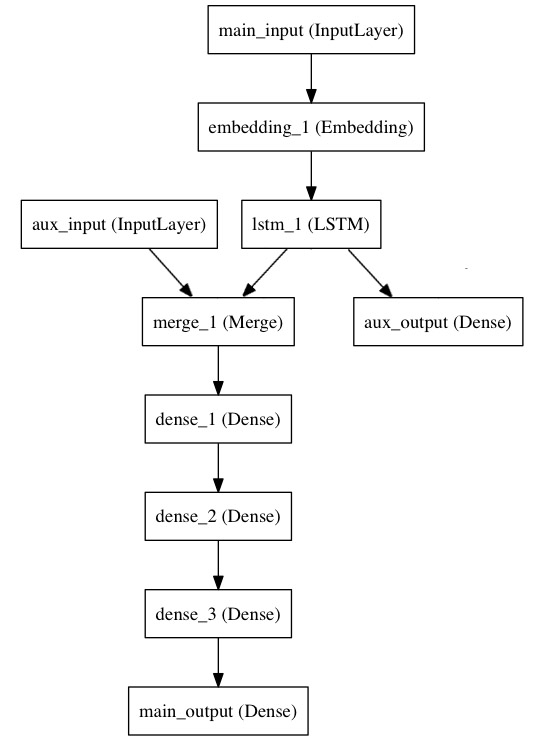
让我们用功能API来实现它。
主输入将接收标题,一个整数序列(每个整数编码一个词)。整数在1到10000之间(词汇量为10000词),序列长度为100个词。
from keras.layers import Input, Embedding, LSTM, Densefrom keras.models import Model# Headline input: meant to receive sequences of 100 integers, between 1 and 10000.# Note that we can name any layer by passing it a "name" argument.main_input = Input(shape=(100,), dtype='int32', name='main_input')# This embedding layer will encode the input sequence# into a sequence of dense 512-dimensional vectors.x = Embedding(output_dim=512, input_dim=10000, input_length=100)(main_input)# A LSTM will transform the vector sequence into a single vector,# containing information about the entire sequencelstm_out = LSTM(32)(x)
这里,我们插入辅助损失,使得LSTM和嵌入层能训练的更为平滑,尽管主损失在此模型中更高一些。
auxiliary_output = Dense(1, activation='sigmoid', name='aux_output')(lstm_out)
这时候,我们把辅助输入数据与LSTM输出结合后传入模型。
auxiliary_input = Input(shape=(5,), name='aux_input')x = keras.layers.concatenate([lstm_out, auxiliary_input])# We stack a deep densely-connected network on topx = Dense(64, activation='relu')(x)x = Dense(64, activation='relu')(x)x = Dense(64, activation='relu')(x)# And finally we add the main logistic regression layermain_output = Dense(1, activation='sigmoid', name='main_output')(x)
定义一个两个输入和两个输出的模型
model = Model(inputs=[main_input, auxiliary_input], outputs=[main_output, auxiliary_output])
编译模型并分配权重0.2给辅助损失。为每个不同的输出指明不同的loss_weights或者loss,可使用列表或字典。这里我们传递一个单一损失作为loss的申明,这样同一损失可用于所有输出。
model.compile(optimizer='rmsprop', loss='binary_crossentropy', loss_weights=[1., 0.2])
我们传入输入数组列表和目标数组训练模型
model.fit([headline_data, additional_data], [labels, labels], epochs=50, batch_size=32)
考虑到我们使用命名输入和输出,我们可以编译模型如下:
model.compile(optimizer='rmsprop', loss={'main_output': 'binary_crossentropy', 'aux_output': 'binary_crossentropy'}, loss_weights={'main_output': 1., 'aux_output': 0.2})# And trained it via:model.fit({'main_input': headline_data, 'aux_input': additional_data}, {'main_output': labels, 'aux_output': labels}, epochs=50, batch_size=32)分享层
功能API同样可用于使用共享层的模型。
现在我们考虑这样一个推特数据集。我们希望构建一个模型来判断两个tweets是否来自同一用户(这使我们可比较用户tweets的相似性)
一种方式是将2个tweets编码成2个向量,结合向量并在上层加入逻辑回归,输出两个推特来自同一用户的概率。模型然后在正向推特对和负向推特对上训练。
由于问题对称,编码第一个推特的机制应重复使用来编码第二个推特。这里我们使用共享LSTM层来编码。
我们使用功能API来构建。我们接收一个形状的二分矩阵(140,256)作为推特的输入,即规模256,序列140的向量,256维度向量里的每一个维度编码了一个字符的出现/不出现(丛256个常用字符表)。
import kerasfrom keras.layers import Input, LSTM, Densefrom keras.models import Modeltweet_a = Input(shape=(140, 256))tweet_b = Input(shape=(140, 256))
在不同输入间共享层,只需实例化层一次,然后反复调用:
# This layer can take as input a matrix# and will return a vector of size 64shared_lstm = LSTM(64)# When we reuse the same layer instance# multiple times, the weights of the layer# are also being reused# (it is effectively *the same* layer)encoded_a = shared_lstm(tweet_a)encoded_b = shared_lstm(tweet_b)# We can then concatenate the two vectors:merged_vector = keras.layers.concatenate([encoded_a, encoded_b], axis=-1)# And add a logistic regression on toppredictions = Dense(1, activation='sigmoid')(merged_vector)# We define a trainable model linking the# tweet inputs to the predictionsmodel = Model(inputs=[tweet_a, tweet_b], outputs=predictions)model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['accuracy'])model.fit([data_a, data_b], labels, epochs=10)
层节点概念
当在输入上调用层时,构建了一个新的张量(层的输出),并且在层上添加了一个节点,将输入张量和输出张量结合起来。当调用同一层多次时,层有多个节点,索引为0,1,2...
在keras以前版本中,可以通过layer.get_output()获得层实例的输出张量,或layer.output_shape()来获得形状。除了get_output()被output替换了之外,其他依然适用。但如果一个层被多个输入连接该如何处理?
只要一个层只和一个输入连接,毫无疑问.output会返回层的一个输出:
a = Input(shape=(140, 256))lstm = LSTM(32)encoded_a = lstm(a)assert lstm.output == encoded_a
如果层有多个输入则情况发生了变化
a = Input(shape=(140, 256))b = Input(shape=(140, 256))lstm = LSTM(32)encoded_a = lstm(a)encoded_b = lstm(b)lstm.output
>> AssertionError: Layer lstm_1 has multiple inbound nodes,hence the notion of "layer output" is ill-defined.Use `get_output_at(node_index)` instead.这时使用下列代码
assert lstm.get_output_at(0) == encoded_aassert lstm.get_output_at(1) == encoded_b
同样的属性input_shape和output_shape也是如此:只要层只有一个节点,或所有节点有相同的输入/输出形状,这个形状可以被layer.output_shape/layer.input_shape返回。但是如果例如对输入形状(3,32, 32),然后对输入形状(3,64, 64)使用一个同样的Conv2D层,该层就有多个输入/输出形状,你就需要通过指明它们所属的节点索引来获取它们。
a = Input(shape=(3, 32, 32))b = Input(shape=(3, 64, 64))conv = Conv2D(16, (3, 3), padding='same')conved_a = conv(a)# Only one input so far, the following will work:assert conv.input_shape == (None, 3, 32, 32)conved_b = conv(b)# now the `.input_shape` property wouldn't work, but this does:assert conv.get_input_shape_at(0) == (None, 3, 32, 32)assert conv.get_input_shape_at(1) == (None, 3, 64, 64)
更多地例子
Inception模块
论文详见https://arxiv.org/abs/1409.4842
from keras.layers import Conv2D, MaxPooling2D, Inputinput_img = Input(shape=(3, 256, 256))tower_1 = Conv2D(64, (1, 1), padding='same', activation='relu')(input_img)tower_1 = Conv2D(64, (3, 3), padding='same', activation='relu')(tower_1)tower_2 = Conv2D(64, (1, 1), padding='same', activation='relu')(input_img)tower_2 = Conv2D(64, (5, 5), padding='same', activation='relu')(tower_2)tower_3 = MaxPooling2D((3, 3), strides=(1, 1), padding='same')(input_img)tower_3 = Conv2D(64, (1, 1), padding='same', activation='relu')(tower_3)output = keras.layers.concatenate([tower_1, tower_2, tower_3], axis=1)
卷积层的残差连接
论文详见https://arxiv.org/abs/1512.03385
from keras.layers import Conv2D, Input# input tensor for a 3-channel 256x256 imagex = Input(shape=(3, 256, 256))# 3x3 conv with 3 output channels (same as input channels)y = Conv2D(3, (3, 3), padding='same')(x)# this returns x + y.z = keras.layers.add([x, y])
共享视觉模型
该模型重复使用了用于判断两个MNIST数字是否相同的图像处理模块
from keras.layers import Conv2D, MaxPooling2D, Input, Dense, Flattenfrom keras.models import Model# First, define the vision modulesdigit_input = Input(shape=(1, 27, 27))x = Conv2D(64, (3, 3))(digit_input)x = Conv2D(64, (3, 3))(x)x = MaxPooling2D((2, 2))(x)out = Flatten()(x)vision_model = Model(digit_input, out)# Then define the tell-digits-apart modeldigit_a = Input(shape=(1, 27, 27))digit_b = Input(shape=(1, 27, 27))# The vision model will be shared, weights and allout_a = vision_model(digit_a)out_b = vision_model(digit_b)concatenated = keras.layers.concatenate([out_a, out_b])out = Dense(1, activation='sigmoid')(concatenated)classification_model = Model([digit_a, digit_b], out)
视觉问题回答模型
当被问到一个关于图片的自然语言问题时该模型能选择正确的单词(one-word)答案。
它将问题编码成向量,将图像编码成向量,结合两个向量,在可能答案的词汇库上使用逻辑回归训练。
from keras.layers import Conv2D, MaxPooling2D, Flattenfrom keras.layers import Input, LSTM, Embedding, Densefrom keras.models import Model, Sequential# First, let's define a vision model using a Sequential model.# This model will encode an image into a vector.vision_model = Sequential()vision_model.add(Conv2D(64, (3, 3) activation='relu', padding='same', input_shape=(3, 224, 224)))vision_model.add(Conv2D(64, (3, 3), activation='relu'))vision_model.add(MaxPooling2D((2, 2)))vision_model.add(Conv2D(128, (3, 3), activation='relu', padding='same'))vision_model.add(Conv2D(128, (3, 3), activation='relu'))vision_model.add(MaxPooling2D((2, 2)))vision_model.add(Conv2D(256, (3, 3), activation='relu', padding='same'))vision_model.add(Conv2D(256, (3, 3), activation='relu'))vision_model.add(Conv2D(256, (3, 3), activation='relu'))vision_model.add(MaxPooling2D((2, 2)))vision_model.add(Flatten())# Now let's get a tensor with the output of our vision model:image_input = Input(shape=(3, 224, 224))encoded_image = vision_model(image_input)# Next, let's define a language model to encode the question into a vector.# Each question will be at most 100 word long,# and we will index words as integers from 1 to 9999.question_input = Input(shape=(100,), dtype='int32')embedded_question = Embedding(input_dim=10000, output_dim=256, input_length=100)(question_input)encoded_question = LSTM(256)(embedded_question)# Let's concatenate the question vector and the image vector:merged = keras.layers.concatenate([encoded_question, encoded_image])# And let's train a logistic regression over 1000 words on top:output = Dense(1000, activation='softmax')(merged)# This is our final model:vqa_model = Model(inputs=[image_input, question_input], outputs=output)# The next stage would be training this model on actual data.
视频问题答案模型
我们上面已经训练了图像QA模型,我们可以迅速将它转化为视频QA模型。训练得当,可让它看段视频(如100帧人的动作)然后问关于视频的自然语言问题(如,男孩在做什么运动? —— 足球(football))
from keras.layers import TimeDistributedvideo_input = Input(shape=(100, 3, 224, 224))# This is our video encoded via the previously trained vision_model (weights are reused)encoded_frame_sequence = TimeDistributed(vision_model)(video_input) # the output will be a sequence of vectorsencoded_video = LSTM(256)(encoded_frame_sequence) # the output will be a vector# This is a model-level representation of the question encoder, reusing the same weights as before:question_encoder = Model(inputs=question_input, outputs=encoded_question)# Let's use it to encode the question:video_question_input = Input(shape=(100,), dtype='int32')encoded_video_question = question_encoder(video_question_input)# And this is our video question answering model:merged = keras.layers.concatenate([encoded_video, encoded_video_question])output = Dense(1000, activation='softmax')(merged)video_qa_model = Model(inputs=[video_input, video_question_input], outputs=output)
- Keras —— 功能API入门
- Keras入门(3)——磨刀不误砍柴工
- Keras入门(2)——麻雀虽小,五脏俱全
- keras入门
- keras入门
- Keras——Tensorflow
- lstm——keras
- 基于keras的深度学习基本概念讲解——深度学习之从小白到入门
- 基于keras的深度学习基本概念讲解——深度学习之从小白到入门
- keras学习笔记2——Keras模块概述
- keras学习随笔03——常用keras layers
- keras中文文档笔记9——关于keras层
- keras中文文档笔记12——协助使用Keras
- Keras的入门
- Keras入门mnist_mlp.py
- keras入门(一)
- keras深度学习入门
- Keras——环境配置
- 测试环境部署环境安装篇jdk ,jmeter,tomcat,mysql
- JAVA8新特性
- java I/O系统
- 获奖公布 | 征文——从高考到程序员
- Duilib设置字体类型大小等属性
- Keras —— 功能API入门
- ElasticSearch5.4搭建
- 【html-css】杂记
- Oracle SQL语句执行过程
- java集合之Map家族
- JavaMelody应用监控
- git 删除文件操作
- [Leetcode] 172. Factorial Trailing Zeroes 解题报告
- Eclipse-自动补全提示


