AlexNet解析
来源:互联网 发布:ionic lab for mac 编辑:程序博客网 时间:2024/06/05 08:00
这一波的深度学习浪潮源自2012年ImageNet比赛冠军所用的深度卷积神经网络(AlexNet),这篇文章就来解读一下这个网络。

2012年,Alex Krizhevsky及其同学Ilya Sutskever在多伦多大学Geoff Hinton的实验室设计了一个深层的卷积神经网络,夺得了2012年ImageNet LSVRC的冠军,且准确率远超第二名(top5 error rate 15.3%,第二名为26.2%),这在学术界引起了很大的轰动,大家争先恐后地研究深度神经网络,带来了深度学习的大爆发。之后的ImageNet冠军都是用CNN来做的,并且层次越来越深。
他们发表的论文为:ImageNet Classification with Deep Convolutional Neural Networks
论文网址:https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf
名词解释
ILSVRC:ImageNet Large Scale Visual Recognition Competition
Activation function:神经元的激活函数
ReLU:全称是Rectified Linear Unit,是一个很简单的函数,即f(x) = max(0, x)
Hyper-parameters:超参数
Kernel map:指和卷积核相乘后得到的矩阵
数据集
实验采用的数据集是ImageNet,它有超过1500万张人工标注好的高分辨率的图片,分别属于约22000个类别。ImageNet的图片全部来自网络,并通过亚马逊的Mechanical Turk众包服务进行了人工标注。自2010年开始举办ILSVRC比赛,每年一次。ILSVRC用的是ImageNet的一个子集,总共有1000个类别,每个类别大约有1000张图片,其中训练集有约120万张图片,验证集约5万张图片,测试集约15万张图片。ImageNet比赛会给出2个错误率,top-1和top-5,top-5错误率是指你的模型预测的概率最高的5个类别中都不包含正确的类别。
ReLU Nonlinearity
神经元的激活函数通常选择sigmoid函数或tanh函数,但在AlexNet中用的却是max(0, x)函数,它的名字叫Rectified Linear Unit (ReLU)。用这个激活函数的神经网络的训练速度要比用传统激活函数的神经网络快数倍。4层的卷积神经网络在CIFAR-10数据集上训练达到25%的错误率,用ReLU(实线)比tanh(虚线)快6倍,如下图所示:

Local Response Normalization
AlexNet在激活函数之外还应用了一种局部的归一化操作,公式如下:

其中, 表示第i个卷积核在(x, y)位置产生的值再应用ReLU激活函数后的结果。n表示相邻的几个卷积核。N表示这一层总的卷积核数量。k, n, α和β是hyper-parameters,他们的值是在验证集上实验得到的,其中k = 2,n = 5,α = 0.0001,β = 0.75。
表示第i个卷积核在(x, y)位置产生的值再应用ReLU激活函数后的结果。n表示相邻的几个卷积核。N表示这一层总的卷积核数量。k, n, α和β是hyper-parameters,他们的值是在验证集上实验得到的,其中k = 2,n = 5,α = 0.0001,β = 0.75。
这种归一化操作实现了某种形式的横向抑制,这也是受真实神经元的某种行为启发。
Overlapping Pooling
通常情况下,在CNN中,pooling窗口的大小和步长是一样的,这就相当于对图片进行了采样,如下图所示:
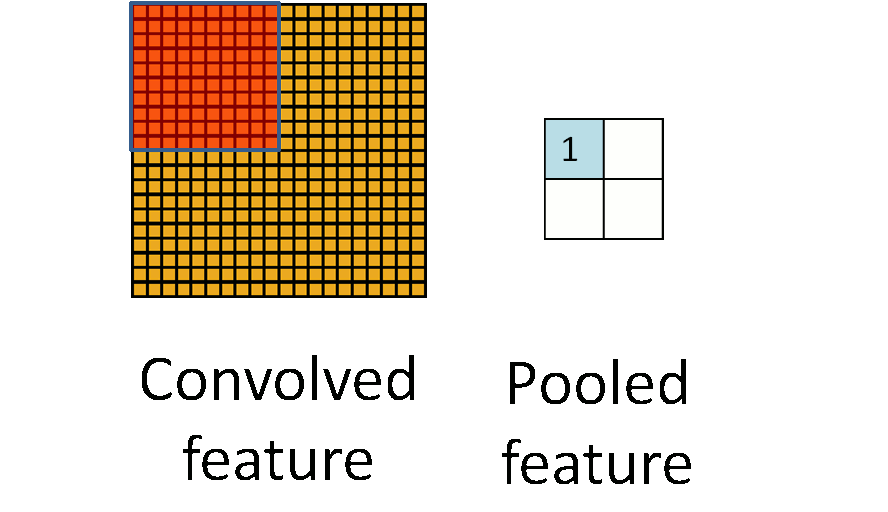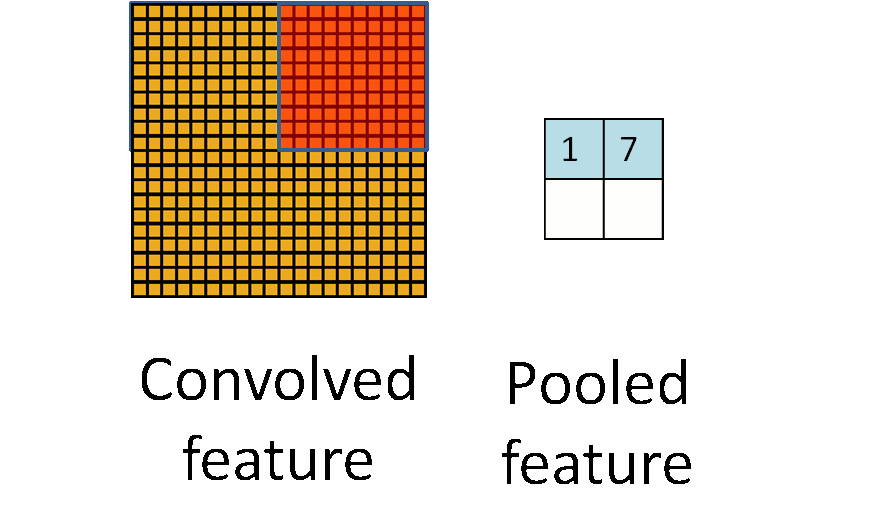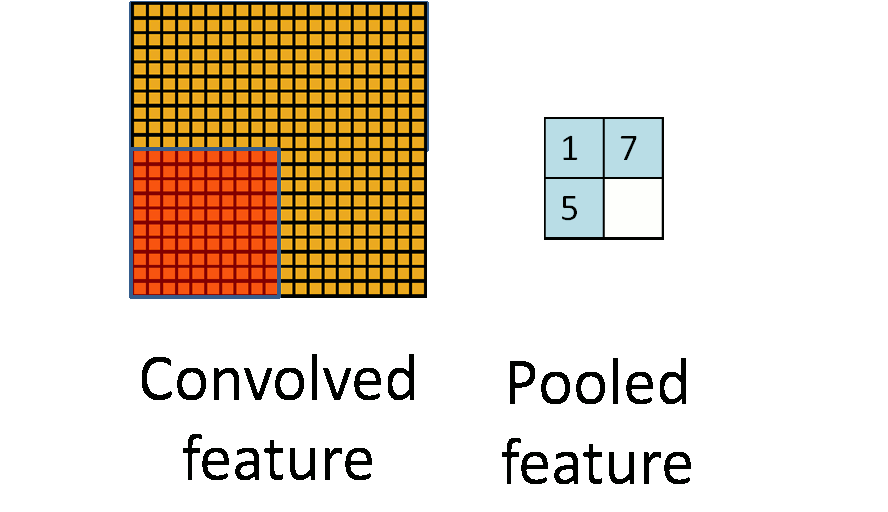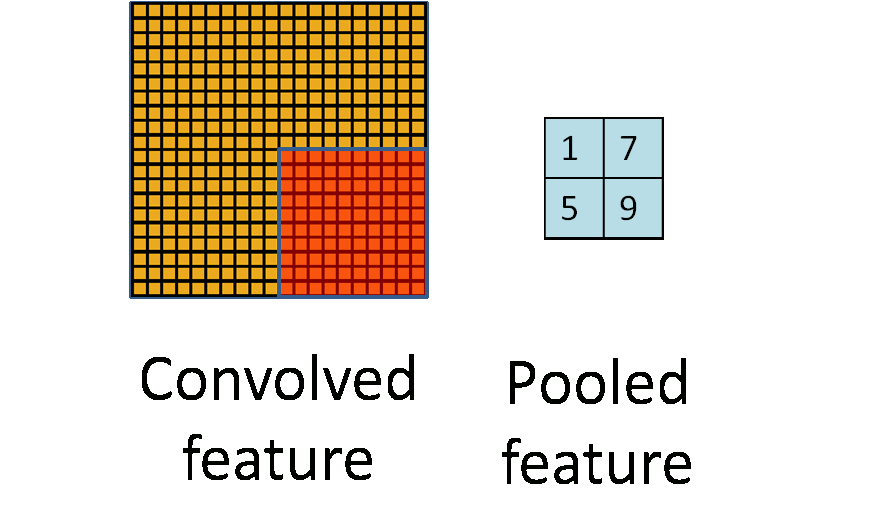
但在AlexNet中用了重叠的pooling操作,滑动窗口的大小为3 * 3,步长却为2。
网络的结构
AlexNet前面是5个卷积层,之后是3个全连接层,最后再加上一个1000-way的Softmax,对应于ILSVRC的1000个类别的概率。AlexNet的结构如下图所示:

从上图可以明显看到网络结构分为上下2层,这是表示网络分布在2个GPU上,因为一个NVIDIA GTX 580 GPU只有3GB内存,装不下这么大的网络。为了减少GPU之间的通信,第2,4,5个卷积层只连接同一个GPU上的上一层的kernel maps(见名词解释)。第3个卷积层连接第二层的所有kernel maps。全连接层的神经元连接到上一层所有的神经元。第1,2个卷积层里ReLU操作之后有response normalization操作。第1,2,5个卷积层里有max pooling操作。作为激活函数,所有的卷积层和全连接层都有ReLU操作。
输入的图片的尺寸是224 * 224 * 3,3表示RGB这3个通道。第一个卷积层共有96个卷积核,每个卷积核的尺寸是11 * 11 * 3,移动的步长是4。第二个卷积层有256个卷积核,每个卷积核的尺寸是5 * 5 * 48。因为第1个卷积层共有96个卷积核,第2层的卷积核尺寸应该是5 * 5 * 96的,但因为第一层的kernel maps分布在2个GPU上,且第2个卷积层只连接同一个GPU上的上一层网络,所以卷积核的尺寸只有5 * 5 * 48。第3个卷积层有384个卷积核,每个核的尺寸是3 * 3 * 256。第4个卷积层有384个卷积核,每个核的尺寸是3 * 3 * 192。第5个卷积层有256个卷积核,每个核的尺寸是3 * 3 * 192。第1和2个全连接层各有4096个神经元,第3个全连接层有1000个神经元。
防止过拟合
1.Data Augmentation
增强图片数据集最简单和最常用的方法是在不改变图片核心元素(即不改变图片的分类)的前提下对图片进行一定的变换,比如在垂直和水平方向进行一定的位移,翻转等。
AlexNet用到的第一种data augmentation方法为:从原图片(256 * 256)中随机的提取224 * 224的图片,以及他们水平方向的映像(即沿竖直中轴线翻转180度)。
AlexNet用到的第二种data augmentation方法是在图片每个像素的R,G,B值上分别加上一个数,用的方法为PCA (Principal Component Analysis)。将每个像素的RGB值 加上下面的值:
加上下面的值:

其中 和
和 分别是RGB值的3 * 3协方差矩阵的第i个特征向量和特征值。
分别是RGB值的3 * 3协方差矩阵的第i个特征向量和特征值。 是一个服从均值为0,标准差为0.1的高斯分布的随机变量,在训练一张图片之前生成,同一张图片多次训练会生成多次。这两个矩阵相乘,得到一个3 * 1的矩阵(向量),再与上面的RGB向量相加。
是一个服从均值为0,标准差为0.1的高斯分布的随机变量,在训练一张图片之前生成,同一张图片多次训练会生成多次。这两个矩阵相乘,得到一个3 * 1的矩阵(向量),再与上面的RGB向量相加。
这种方法将top-1的错误率减少了1%。
2.Dropout
AlexNet用了一种叫做dropout的技术来减少过拟合。dropout是指以一定的概率使神经元的输出为0,AlexNet选择的概率为0.5。这种技术打破了神经元之间固定的依赖,使得学习到的参数更加健壮。AlexNet在第1,2个全连接层用了dropout技术,这使得到收敛的迭代次数增加了一倍。
训练细节
模型的训练用了随机梯度下降 (stochastic gradient descent),每批图片有180张。权重的更新公式为:

其中,i是迭代的index,v是一个常量0.9,叫momentum, 是学习率,初始值为0.01,
是学习率,初始值为0.01, 是这一批图片对于
是这一批图片对于 的偏导数的平均值。
的偏导数的平均值。
所有的权重都是用均值为0,标准差为0.01的高斯分布来初始化。第2,4,5个卷积层和所有的全连接层的bias都初始化为1,其它层的bias被初始化为0。学习率的初始值为0.01,所有的层都用同一个学习率。在训练的过程中,当错误率不再下降时,将学习率除以10,用更小的学习率来训练。
训练的过程花了5到6天,120万张图片训练了90遍。
更多文章请关注我的公众号:机器学习交流
- AlexNet解析
- AlexNet文章解析(上)
- Alexnet详细解析
- 【深度学习】AlexNet结构解析
- alexnet
- AlexNet
- Alexnet
- Alexnet
- Alexnet
- AlexNet
- AlexNet
- AlexNet
- AlexNet
- AlexNet
- AlexNet
- AlexNet
- AlexNet
- AlexNet
- 在JDBC一次插入多个表、多条记录
- hdu 1051 Wooden Sticks
- 外部类.this.成员域
- java Executors 线程池解读
- mysql--查看mysql状态的常用命令
- AlexNet解析
- bzoj 2423: [HAOI2010]最长公共子序列 (DP)
- 第四章 使用OpenCV探测来至运动的结构——Chapter 4:Exploring Structure from Motion Using OpenCV 标签: SFM3D重建 2015-01-15
- SAS导入csv文件乱码解决办法
- [HDU-5980] [Problem J]水题
- Python-学习笔记(一)
- 共享内存
- leetcode 377. Combination Sum IV 换钱问题
- 电量的测试方法(adb shell dumpsys batterystats)


