Hadoop基本原理
来源:互联网 发布:ucsc数据库 编辑:程序博客网 时间:2024/06/06 02:49
Hadoop是什么?Hadoop是一个开发和运行处理大规模数据的软件平台,是Appach的一个用java语言实现开源软件框架,实现在大量计算机组成的集群中对海量数据进行分布式计算.
- 作者:kkdelta来源:Linux社区|2012-07-03 16:56
- 移动端
Hadoop是什么?Hadoop是一个开发和运行处理大规模数据的软件平台,是Appach的一个用java语言实现开源软件框架,实现在大量计算机组成的集群中对海量数据进行分布式计算.
Hadoop框架中最核心设计就是:HDFS和MapReduce.HDFS提供了海量数据的存储,MapReduce提供了对数据的计算.
数据在Hadoop中处理的流程可以简单的按照下图来理解:数据通过Haddop的集群处理后得到结果.
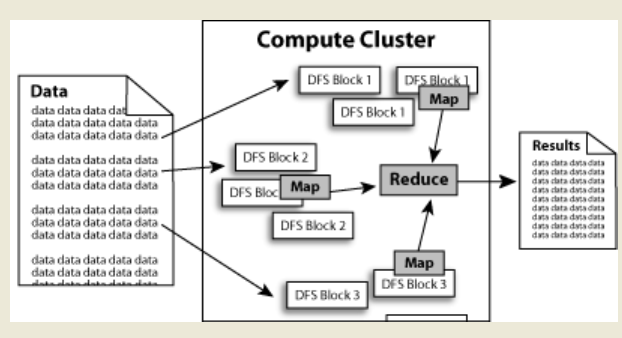
HDFS:Hadoop Distributed File System,Hadoop的分布式文件系统.
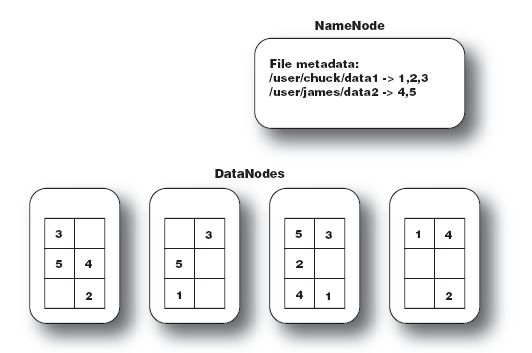
大文件被分成默认64M一块的数据块分布存储在集群机器中.
如下图中的文件 data1被分成3块,这3块以冗余镜像的方式分布在不同的机器中.
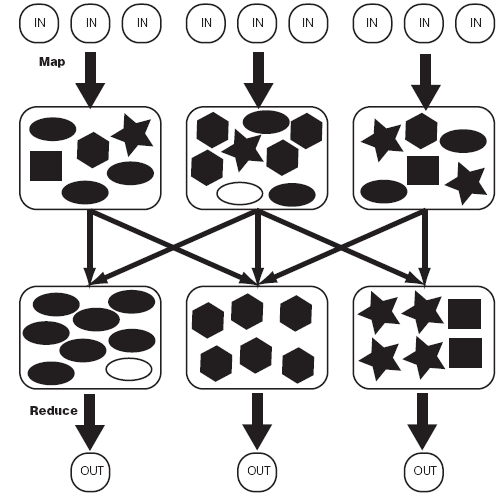
MapReduce:Hadoop为每一个input split创建一个task调用Map计算,在此task中依次处理此split中的一个个记录(record),map会将结果以key--value的形式输出,hadoop负责按key值将map的输出整理后作为Reduce的输入,Reduce Task的输出为整个job的输出,保存在HDFS上.
Hadoop的集群主要由 NameNode,DataNode,Secondary NameNode,JobTracker,TaskTracker组成.
如下图所示:
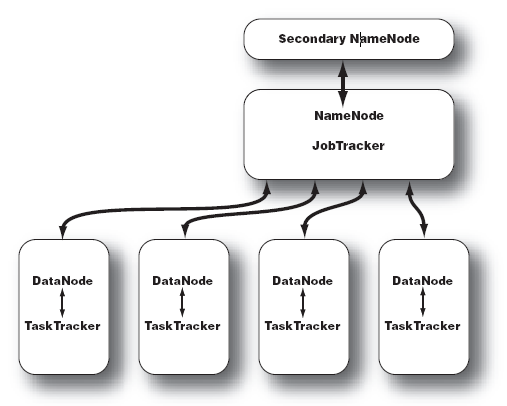
NameNode中记录了文件是如何被拆分成block以及这些block都存储到了那些DateNode节点.
NameNode同时保存了文件系统运行的状态信息.
DataNode中存储的是被拆分的blocks.
Secondary NameNode帮助NameNode收集文件系统运行的状态信息.
JobTracker当有任务提交到Hadoop集群的时候负责Job的运行,负责调度多个TaskTracker.
TaskTracker负责某一个map或者reduce任务
Hadoop 是一个开源的可运行于大规模集群上的分布式并行编程框架,由于分布式存储对于分布式编程来说是必不可少的,这个框架中还包含了一个分布式文件系统 HDFS( Hadoop Distributed File System )。也许到目前为止,Hadoop 还不是那么广为人知,其最新的版本号也仅仅是 0.16,距离 1.0 似乎都还有很长的一段距离,但提及 Hadoop 一脉相承的另外两个开源项目 Nutch 和 Lucene ( 三者的创始人都是 Doug Cutting ),那绝对是大名鼎鼎。Lucene 是一个用 Java 开发的开源高性能全文检索工具包,它不是一个完整的应用程序,而是一套简单易用的 API 。在全世界范围内,已有无数的软件系统,Web 网站基于 Lucene 实现了全文检索功能,后来 Doug Cutting 又开创了第一个开源的 Web 搜索引擎( http://www.nutch.org ) Nutch, 它在 Lucene 的基础上增加了网络爬虫和一些和 Web 相关的功能,一些解析各类文档格式的插件等,此外,Nutch 中还包含了一个分布式文件系统用于存储数据。从 Nutch 0.8.0 版本之后,Doug Cutting 把 Nutch 中的分布式文件系统以及实现 MapReduce 算法的代码独立出来形成了一个新的开源项 Hadoop。Nutch 也演化为基于 Lucene 全文检索以及 Hadoop 分布式计算平台的一个开源搜索引擎。
基于 Hadoop,你可以轻松地编写可处理海量数据的分布式并行程序,并将其运行于由成百上千个结点组成的大规模计算机集群上。从目前的情况来看,Hadoop 注定会有一个辉煌的未来:"云计算"是目前灸手可热的技术名词,全球各大 IT 公司都在投资和推广这种新一代的计算模式,而 Hadoop 又被其中几家主要的公司用作其"云计算"环境中的重要基础软件,如:雅虎正在借助 Hadoop 开源平台的力量对抗 Google, 除了资助 Hadoop 开发团队外,还在开发基于 Hadoop 的开源项目 Pig, 这是一个专注于海量数据集分析的分布式计算程序。Amazon 公司基于 Hadoop 推出了 Amazon S3 ( Amazon Simple Storage Service ),提供可靠,快速,可扩展的网络存储服务,以及一个商用的云计算平台 Amazon EC2 ( Amazon Elastic Compute Cloud )。在 IBM 公司的云计算项目--"蓝云计划"中,Hadoop 也是其中重要的基础软件。Google 正在跟IBM合作,共同推广基于 Hadoop 的云计算。
回页首
迎接编程方式的变革
在摩尔定律的作用下,以前程序员根本不用考虑计算机的性能会跟不上软件的发展,因为约每隔 18 个月,CPU 的主频就会增加一倍,性能也将提升一倍,软件根本不用做任何改变,就可以享受免费的性能提升。然而,由于晶体管电路已经逐渐接近其物理上的性能极限,摩尔定律在 2005 年左右开始失效了,人类再也不能期待单个 CPU 的速度每隔 18 个月就翻一倍,为我们提供越来越快的计算性能。Intel, AMD, IBM 等芯片厂商开始从多核这个角度来挖掘 CPU 的性能潜力,多核时代以及互联网时代的到来,将使软件编程方式发生重大变革,基于多核的多线程并发编程以及基于大规模计算机集群的分布式并行编程是将来软件性能提升的主要途径。
许多人认为这种编程方式的重大变化将带来一次软件的并发危机,因为我们传统的软件方式基本上是单指令单数据流的顺序执行,这种顺序执行十分符合人类的思考习惯,却与并发并行编程格格不入。基于集群的分布式并行编程能够让软件与数据同时运行在连成一个网络的许多台计算机上,这里的每一台计算机均可以是一台普通的 PC 机。这样的分布式并行环境的最大优点是可以很容易的通过增加计算机来扩充新的计算结点,并由此获得不可思议的海量计算能力, 同时又具有相当强的容错能力,一批计算结点失效也不会影响计算的正常进行以及结果的正确性。Google 就是这么做的,他们使用了叫做 MapReduce 的并行编程模型进行分布式并行编程,运行在叫做 GFS ( Google File System )的分布式文件系统上,为全球亿万用户提供搜索服务。
Hadoop 实现了 Google 的 MapReduce 编程模型,提供了简单易用的编程接口,也提供了它自己的分布式文件系统 HDFS,与 Google 不同的是,Hadoop 是开源的,任何人都可以使用这个框架来进行并行编程。如果说分布式并行编程的难度足以让普通程序员望而生畏的话,开源的 Hadoop 的出现极大的降低了它的门槛,读完本文,你会发现基于 Hadoop 编程非常简单,无须任何并行开发经验,你也可以轻松的开发出分布式的并行程序,并让其令人难以置信地同时运行在数百台机器上,然后在短时间内完成海量数据的计算。你可能会觉得你不可能会拥有数百台机器来运行你的并行程序,而事实上,随着"云计算"的普及,任何人都可以轻松获得这样的海量计算能力。 例如现在 Amazon 公司的云计算平台 Amazon EC2 已经提供了这种按需计算的租用服务,有兴趣的读者可以去了解一下,这篇系列文章的第三部分将有所介绍。
掌握一点分布式并行编程的知识对将来的程序员是必不可少的,Hadoop 是如此的简便好用,何不尝试一下呢?也许你已经急不可耐的想试一下基于 Hadoop 的编程是怎么回事了,但毕竟这种编程模型与传统的顺序程序大不相同,掌握一点基础知识才能更好地理解基于 Hadoop 的分布式并行程序是如何编写和运行的。因此本文会先介绍一下 MapReduce 的计算模型,Hadoop 中的分布式文件系统 HDFS, Hadoop 是如何实现并行计算的,然后才介绍如何安装和部署 Hadoop 框架,以及如何运行 Hadoop 程序。
回页首
MapReduce 计算模型
MapReduce 是 Google 公司的核心计算模型,它将复杂的运行于大规模集群上的并行计算过程高度的抽象到了两个函数,Map 和 Reduce, 这是一个令人惊讶的简单却又威力巨大的模型。适合用 MapReduce 来处理的数据集(或任务)有一个基本要求: 待处理的数据集可以分解成许多小的数据集,而且每一个小数据集都可以完全并行地进行处理。
图 1. MapReduce 计算流程 
图一说明了用 MapReduce 来处理大数据集的过程, 这个 MapReduce 的计算过程简而言之,就是将大数据集分解为成百上千的小数据集,每个(或若干个)数据集分别由集群中的一个结点(一般就是一台普通的计算机)进行处理并生成中间结果,然后这些中间结果又由大量的结点进行合并, 形成最终结果。
计算模型的核心是 Map 和 Reduce 两个函数,这两个函数由用户负责实现,功能是按一定的映射规则将输入的 <key, value> 对转换成另一个或一批 <key, value> 对输出。
表一 Map 和 Reduce 函数
2. 每一个输入的 <k1,v1> 会输出一批 <k2,v2>。 <k2,v2> 是计算的中间结果。
以一个计算文本文件中每个单词出现的次数的程序为例,<k1,v1> 可以是 <行在文件中的偏移位置, 文件中的一行>,经 Map 函数映射之后,形成一批中间结果 <单词,出现次数>, 而 Reduce 函数则可以对中间结果进行处理,将相同单词的出现次数进行累加,得到每个单词的总的出现次数。
基于 MapReduce 计算模型编写分布式并行程序非常简单,程序员的主要编码工作就是实现 Map 和 Reduce 函数,其它的并行编程中的种种复杂问题,如分布式存储,工作调度,负载平衡,容错处理,网络通信等,均由 MapReduce 框架(比如 Hadoop )负责处理,程序员完全不用操心。
回页首
四 集群上的并行计算
MapReduce 计算模型非常适合在大量计算机组成的大规模集群上并行运行。图一中的每一个 Map 任务和每一个 Reduce 任务均可以同时运行于一个单独的计算结点上,可想而知其运算效率是很高的,那么这样的并行计算是如何做到的呢?
数据分布存储
Hadoop 中的分布式文件系统 HDFS 由一个管理结点 ( NameNode )和N个数据结点 ( DataNode )组成,每个结点均是一台普通的计算机。在使用上同我们熟悉的单机上的文件系统非常类似,一样可以建目录,创建,复制,删除文件,查看文件内容等。但其底层实现上是把文件切割成 Block,然后这些 Block 分散地存储于不同的 DataNode 上,每个 Block 还可以复制数份存储于不同的 DataNode 上,达到容错容灾之目的。NameNode 则是整个 HDFS 的核心,它通过维护一些数据结构,记录了每一个文件被切割成了多少个 Block,这些 Block 可以从哪些 DataNode 中获得,各个 DataNode 的状态等重要信息。如果你想了解更多的关于 HDFS 的信息,可进一步阅读参考资料: The Hadoop Distributed File System:Architecture and Design
分布式并行计算
Hadoop 中有一个作为主控的 JobTracker,用于调度和管理其它的 TaskTracker, JobTracker 可以运行于集群中任一台计算机上。TaskTracker 负责执行任务,必须运行于 DataNode 上,即 DataNode 既是数据存储结点,也是计算结点。 JobTracker 将 Map 任务和 Reduce 任务分发给空闲的 TaskTracker, 让这些任务并行运行,并负责监控任务的运行情况。如果某一个 TaskTracker 出故障了,JobTracker 会将其负责的任务转交给另一个空闲的 TaskTracker 重新运行。
本地计算
数据存储在哪一台计算机上,就由这台计算机进行这部分数据的计算,这样可以减少数据在网络上的传输,降低对网络带宽的需求。在 Hadoop 这样的基于集群的分布式并行系统中,计算结点可以很方便地扩充,而因它所能够提供的计算能力近乎是无限的,但是由是数据需要在不同的计算机之间流动,故网络带宽变成了瓶颈,是非常宝贵的,“本地计算”是最有效的一种节约网络带宽的手段,业界把这形容为“移动计算比移动数据更经济”。
图 2. 分布存储与并行计算 
任务粒度
把原始大数据集切割成小数据集时,通常让小数据集小于或等于 HDFS 中一个 Block 的大小(缺省是 64M),这样能够保证一个小数据集位于一台计算机上,便于本地计算。有 M 个小数据集待处理,就启动 M 个 Map 任务,注意这 M 个 Map 任务分布于 N 台计算机上并行运行,Reduce 任务的数量 R 则可由用户指定。
Partition
把 Map 任务输出的中间结果按 key 的范围划分成 R 份( R 是预先定义的 Reduce 任务的个数),划分时通常使用 hash 函数如: hash(key) mod R,这样可以保证某一段范围内的 key,一定是由一个 Reduce 任务来处理,可以简化 Reduce 的过程。
Combine
在 partition 之前,还可以对中间结果先做 combine,即将中间结果中有相同 key的 <key, value> 对合并成一对。combine 的过程与 Reduce 的过程类似,很多情况下就可以直接使用 Reduce 函数,但 combine 是作为 Map 任务的一部分,在执行完 Map 函数后紧接着执行的。Combine 能够减少中间结果中 <key, value> 对的数目,从而减少网络流量。
Reduce 任务从 Map 任务结点取中间结果
Map 任务的中间结果在做完 Combine 和 Partition 之后,以文件形式存于本地磁盘。中间结果文件的位置会通知主控 JobTracker, JobTracker 再通知 Reduce 任务到哪一个 DataNode 上去取中间结果。注意所有的 Map 任务产生中间结果均按其 Key 用同一个 Hash 函数划分成了 R 份,R 个 Reduce 任务各自负责一段 Key 区间。每个 Reduce 需要向许多个 Map 任务结点取得落在其负责的 Key 区间内的中间结果,然后执行 Reduce 函数,形成一个最终的结果文件。
任务管道
有 R 个 Reduce 任务,就会有 R 个最终结果,很多情况下这 R 个最终结果并不需要合并成一个最终结果。因为这 R 个最终结果又可以做为另一个计算任务的输入,开始另一个并行计算任务。
- Hadoop基本原理
- Hadoop基本原理
- Hadoop基本原理之一:MapReduce
- Hadoop基本原理之一:MapReduce
- Hadoop基本原理介绍
- HAdoop基本原理1
- 使用ToolRunner运行Hadoop程序基本原理分析
- Hadoop集群和网络的基本原理(一)
- Hadoop集群和网络的基本原理(二)
- 使用ToolRunner运行Hadoop程序基本原理分析
- 使用ToolRunner运行Hadoop程序基本原理分析
- 使用ToolRunner运行Hadoop程序基本原理分析
- 使用ToolRunner运行Hadoop程序基本原理分析
- Mahout和Hadoop:机器学习的基本原理
- 使用ToolRunner运行Hadoop程序基本原理分析
- hadoop-2.X HA的基本原理
- 使用ToolRunner运行Hadoop程序基本原理分析
- 使用ToolRunner运行Hadoop程序基本原理分析
- Ext属性详细信息
- onActivityResult的使用(Activity界面销毁数据带回)
- 整合maven+mybatis+generator生成java自定义model实体类,dao接口和mapper映射文件
- 2.java面试复习大纲
- Jquery图片轮播插件--jcarousellite的使用
- Hadoop基本原理
- json表单序列化
- CRC循环冗余检验算法
- GET与POST比较(数据大小、数据类型、传送形式)
- IOS核心动画高级二:寄宿图
- 出国开会总结,学生,初次出国参加学术会议
- iOS 使用CoreData时该注意的问题之一
- 网页中怎么插入flash的代码
- Gradle个人笔记(未完)


