卷积神经网络-初学者指南 (Part 2)
来源:互联网 发布:会武术的男人 知乎 编辑:程序博客网 时间:2024/05/29 14:31
本文由机器之心编译:传送门
原文: 传送门
part1 传送门
简介
在这篇文章中,我们将更深入地介绍有关卷积神经网络(ConvNet)的详细情况。声明:我确实知道本文中一部分内容相当复杂,可以用一整篇文章进行介绍。但为了在保持全面性的同时保证简洁,我会在文章中相关位置提供一些更详细解释该相关主题的论文链接。
步长(Stride)和填充(Padding)
现在来看一下我们的卷积神经网络。还记得过滤器、感受野和卷积吗?很好。现在,要改变每一层的行为,有两个主要参数是我们可以调整的。选择了过滤器的尺寸以后,我们还需要选择步幅(stride)和填充(padding)。
步幅控制着过滤器围绕输入内容进行卷积计算的方式。在第一部分我们举的例子中,过滤器通过每次移动一个单元的方式对输入内容进行卷积。过滤器移动的距离就是步幅。在那个例子中,步幅被默认设置为1。步幅的设置通常要确保输出内容是一个整数而非分数。让我们看一个例子。想象一个 7 x 7 的输入图像,一个 3 x 3 过滤器(简单起见不考虑第三个维度),步幅为 1。这是一种惯常的情况。
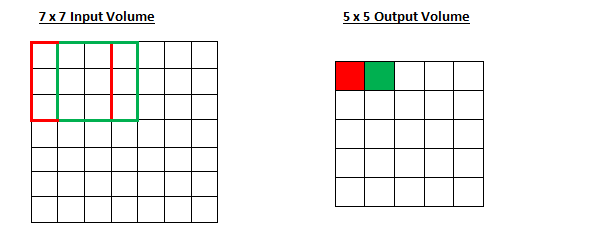
还是老一套,对吧?看你能不能试着猜出如果步幅增加到 2,输出内容会怎么样。
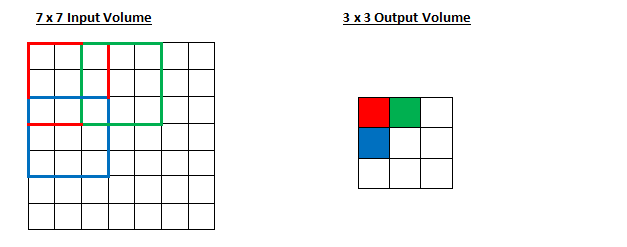
所以,正如你能想到的,感受野移动了两个单元,输出内容同样也会减小。注意,如果试图把我们的步幅设置成 3,那我们就会难以调节间距并确保感受野与输入图像匹配。正常情况下,程序员如果想让接受域重叠得更少并且想要更小的空间维度(spatial dimensions)时,他们会增加步幅。
现在让我们看一下填充(padding)。在此之前,想象一个场景:当你把 5 x 5 x 3 的过滤器用在 32 x 32 x 3 的输入上时,会发生什么?输出的大小会是 28 x 28 x 3。注意,这里空间维度减小了。如果我们继续用卷积层,尺寸减小的速度就会超过我们的期望。在网络的早期层中,我们想要尽可能多地保留原始输入内容的信息,这样我们就能提取出那些低层的特征。比如说我们想要应用同样的卷积层,但又想让输出量维持为 32 x 32 x 3 。为做到这点,我们可以对这个层应用大小为 2 的零填充(zero padding)。零填充在输入内容的边界周围补充零。如果我们用两个零填充,就会得到一个 36 x 36 x 3 的输入。
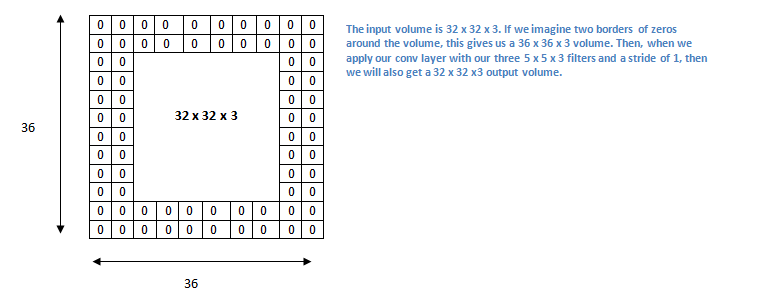
如果我们在输入内容的周围应用两次零填充,那么输入量就为 32×32×3。然后,当我们应用带有 3 个 5×5×3 的过滤器,以 1 的步幅进行处理时,我们也可以得到一个 32×32×3 的输出。
如果你的步幅为 1,而且把零填充设置为
当 K 是过滤器尺寸时,那么输入和输出内容就总能保持一致的空间维度。
计算任意给定卷积层的输出的大小的公式是
其中 O 是输出尺寸,K 是过滤器尺寸,P 是填充,S 是步幅。
选择超参数
我们怎么知道要用多少层、多少卷积层、过滤器尺寸是多少、以及步幅和填充值多大呢?这些问题很重要,但又没有一个所有研究人员都在使用的固定标准。这是因为神经网络很大程度上取决于你的数据类型。图像的大小、复杂度、图像处理任务的类型以及其他更多特征的不同都会造成数据的不同。对于你的数据集,想出如何选择超参数的一个方法是找到能创造出图像在合适尺度上抽象的正确组合。
———————————————————————————————————————————————
(PS:在斯坦福的深度学习与计算机视觉公开课cs231n中有提及该如何选择超参数那就是——随机(是的,你没看错),以下是出自在cs231n课堂笔记,并不在博客原文中,不感兴趣可以跳过。)
随机搜索优于网格搜索。Bergstra和Bengio在文章Random Search for Hyper-Parameter Optimization中说“随机选择比网格化的选择更加有效”,而且在实践中也更容易实现。

在Random Search for Hyper-Parameter Optimization中的核心说明图。通常,有些超参数比其余的更重要,通过随机搜索,而不是网格化的搜索,可以让你更精确地发现那些比较重要的超参数的好数值。
(在此感谢知乎智能单元对cs231n课程笔记的翻译贡献)
———————————————————————————————————————————————
ReLU(修正线性单元)层
在每个卷积层之后,通常会立即应用一个非线性层(或激活层)。其目的是给一个在卷积层中刚经过线性计算操作(只是数组元素依次(element wise)相乘与求和)的系统引入非线性特征。过去,人们用的是像双曲正切和 S 型函数这样的非线性方程,但研究者发现 ReLU 层效果好得多,因为神经网络能够在准确度不发生明显改变的情况下把训练速度提高很多(由于计算效率增加)。它同样能帮助减轻梯度消失的问题——由于梯度以指数方式在层中消失,导致网络较底层的训练速度非常慢。(这也许超出了本文的范围,但这里和这里有更好的解释.)ReLU 层对输入内容的所有值都应用了函数 f(x) = max(0, x)。用基本术语来说,这一层把所有的负激活(negative activation)都变为零。这一层会增加模型乃至整个神经网络的非线性特征,而且不会影响卷积层的感受野。
参见 Geoffrey Hinton(即深度学习之父)的论文:Rectified Linear Units Improve Restricted Boltzmann Machines
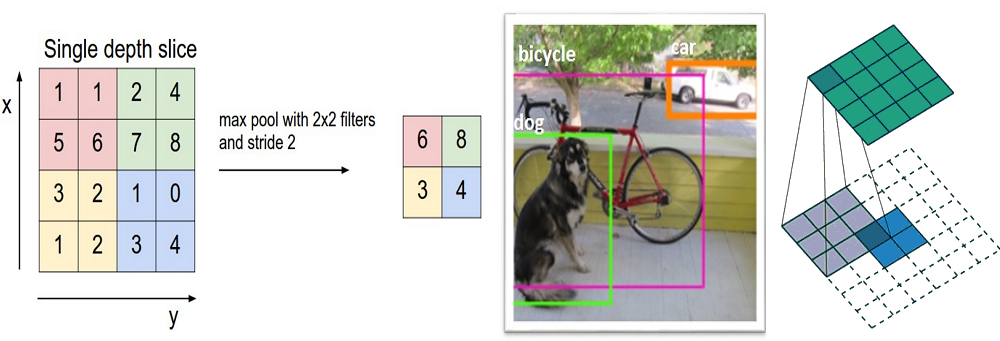
池化层
在几个 ReLU 层之后,程序员也许会选择用一个池化层(pooling layer)。它同时也被叫做下采样(downsampling)层。在这个类别中,也有几种可供选择的层,最受欢迎的就是最大池化( max-pooling)。它基本上采用了一个过滤器(通常是 2x2 的)和一个同样长度的步幅。然后把它应用到输入内容上,输出过滤器卷积计算的每个子区域中的最大数字。
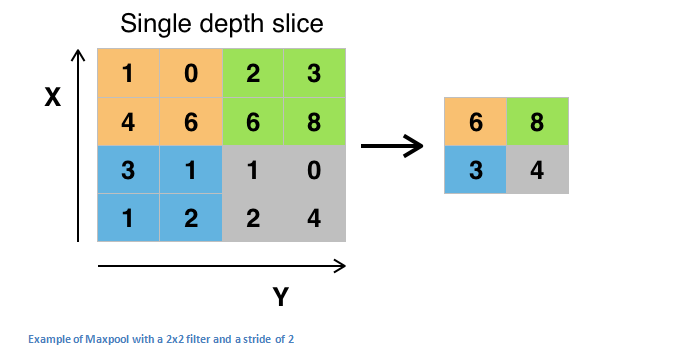
带有 2×2 和过滤器的且步幅为 2 的最大池化的例子
池化层还有其他选择,比如平均池化(average pooling)和 L2-norm 池化 。这一层背后的直观推理是:一旦我们知道了原始输入(这里会有一个高激活值)中一个特定的特征,它与其它特征的相对位置就比它的绝对位置更重要。可想而知,这一层大幅减小了输入卷的空间维度(长度和宽度改变了,但深度没变)。这到达了两个主要目的。第一个是权重参数的数目减少到了75%,因此降低了计算成本。第二是它可以控制过拟合(overfitting)。这个术语是指一个模型与训练样本太过匹配了,以至于用于验证和检测组时无法产生出好的结果。出现过拟合的表现是一个模型在训练集能达到 100% 或 99% 的准确度,而在测试数据上却只有50%。
Dropout 层
如今,Dropout 层在神经网络有了非常明确的功能。上一节,我们讨论了经过训练后的过拟合问题:训练之后,神经网络的权重与训练样本太过匹配以至于在处理新样本的时候表现平平。Dropout 的概念在本质上非常简单。Dropout 层将「丢弃(drop out)」该层中一个随机的激活参数集,即在前向通过(forward pass)中将这些激活参数集设置为 0。简单如斯。既然如此,这些简单而且似乎不必要且有些反常的过程的好处是什么?在某种程度上,这种机制强制网络变得更加冗余。这里的意思是:该网络将能够为特定的样本提供合适的分类或输出,即使一些激活参数被丢弃。此机制将保证神经网络不会对训练样本「过于匹配」,这将帮助缓解过拟合问题。另外,Dropout 层只能在训练中使用,而不能用于测试过程,这是很重要的一点。
参考 Geoffrey Hinton 的论文:Dropout: A Simple Way to Prevent Neural Networks from Overfitting
网络层中的网络
网络层中的网络指的是一个使用了 1 x 1 尺寸的过滤器的卷积层。现在,匆匆一瞥,你或许会好奇为何这种感受野大于它们所映射空间的网络层竟然会有帮助。然而,我们必须谨记 1x1 的卷积层跨越了特定深度,所以我们可以设想一个1 x 1 x N 的卷积层,此处 N 代表该层应用的过滤器数量。该层有效地使用 N 维数组元素依次相乘的乘法,此时 N 代表的是该层的输入的深度。
参阅 Min Lin 的论文:Network In Network
分类、定位、检测、分割
本系列第一部分使用的案例中,我们观察了图像分类任务。这个过程是:获取输入图片,输出一套分类的类数(class number)。然而当我们执行类似目标定位的任务时,我们要做的不只是生成一个类标签,而是生成一个描述图片中物体所在位置的边界框。

我们也有目标检测的任务,这需要图片上所有目标的定位任务都已完成。
因此,你将获得多个边界框和多个类标签。
最终,我们将执行目标分割的任务:我们需要输出类标签的同时输出图片中每个目标的轮廓。

关于目标检测、定位、分割的论文有很多,这里就不一一列出了。可以参考的有:
目标检测/定位: RCNN, Fast RCNN, Faster RCNN, MultiBox, Bayesian Optimization, Multi-region, RCNN Minus R , Image Windows
分割: Semantic Seg, Unconstrained Video, Shape Guided, Object Regions, Shape Sharing
迁移学习
如今,深度学习领域一个常见的误解在于没有谷歌那样的巨量数据,你将没有希望创建一个有效的深度学习模型。尽管数据是创建网络中至关重要的部分,迁移学习的思路将帮助我们降低数据需求。迁移学习指的是利用预训练模型(神经网络的权重和参数都已经被其他人利用更大规模的数据集训练好了)并用自己的数据集将模型「微调」的过程。这种思路中预训练模型扮演着特征提取器的角色。你将移除网络的最后一层并用你自有的分类器置换(取决于你的问题空间)。然后冻结其他所有层的权重并正常训练该网络(冻结这些层意味着在梯度下降/最优化过程中保持权值不变)。
让我们探讨一下为什么做这项工作。比如说我们正在讨论的这个预训练模型是在 ImageNet (一个包含一千多个分类,一千四百万张图像的数据集)上训练的 。当我们思考神经网络的较低层时,我们知道它们将检测类似曲线和边缘这样的特征。现在,除非你有一个极为独特的问题空间和数据集,你的神经网络也会检测曲线和边缘这些特征。相比通过随机初始化权重训练整个网络,我们可以利用预训练模型的权重(并冻结)聚焦于更重要的层(更高层)进行训练。如果你的数据集不同于 ImageNet 这样的数据集,你必须训练更多的层级而只冻结一些低层的网络。
Yoshua Bengio (另外一个深度学习先驱 )论文:How transferable are features in deep neural networks?
Ali Sharif Razavian 论文:CNN Features off-the-shelf: an Astounding Baseline for Recognition
Jeff Donahue 论文:DeCAF: A Deep Convolutional Activation Feature for Generic Visual Recognition
数据增强技术
现在我们对卷积网络中数据的重要性可能已经感到有些麻木了,所以我们来谈下如何利用一些简单的转换方法将你现有的数据集变得更大。正如我们之前所提及的,当计算机将图片当作输入时,它将用一个包含一列像素值的数组描述(这幅图)。若是图片左移一个像素。对你和我来说,这种变化是微不可察的。然而对计算机而已,这种变化非常显著:这幅图的类别和标签保持不变,数组却变化了。这种改变训练数据的数组表征而保持标签不变的方法被称作数据增强技术。这是一种人工扩展数据集的方法。人们经常使用的增强方法包括灰度变化、水平翻转、垂直翻转、随机编组、色值跳变、翻译、旋转等其他多种方法。通过利用这些训练数据的转换方法,你将获得两倍甚至三倍于原数据的训练样本。
code:
根据caffe自带的mnist examples模型进行编写的mnist模型。但采用很粗糙的卷积方法,loss确实会降低但很慢。不过适合初学者是理解内部实现过程。
https://github.com/JimLee4530/Toys-Box
- 卷积神经网络-初学者指南 (Part 2)
- 卷积神经网络-初学者指南 (Part 1)
- 卷积神经网络初学者指南
- 你需要知道的一些深度学习的论文(卷积神经网络-初学者指南 (Part 3))
- 卷积神经网络新手指南 2
- 从入门到精通:卷积神经网络初学者指南
- 从入门到精通:卷积神经网络初学者指南
- 从入门到精通:卷积神经网络初学者指南
- 从入门到精通:卷积神经网络初学者指南
- 卷积神经网络(CNN)新手指南
- 卷积神经网络(CNN)新手指南
- 卷积神经网络(CNN)新手指南 1
- 卷积神经网络(CNN)新手指南
- 卷积神经网络(CNN)新手指南
- 卷积神经网络(CNN)新手指南
- 十五、卷积神经网络(2):卷积神经网络的结构
- 卷积求导(卷积神经网络)
- 卷积神经网络新手入门2
- arm版本及其指令集
- 十进制转八进制
- redis 3.2.9集群安装
- 修改jenkins默认端口
- 高性能Server---Reactor模型
- 卷积神经网络-初学者指南 (Part 2)
- 密集立体匹配20年论文整理
- 超键、候选键和主键
- iOS 开发学习资料整理(持续更新)
- 有n个台阶,一次1步、2步或3步的上台阶。试对给出的任意一个n(n〉0),求出上台阶的总上法的递推公式。
- 解决sublime text3安装Package Control问题
- bzoj 1879 [Sdoi2009]Bill的挑战
- 算法学习【动态规划】----最长回文子串&最长回文子序列
- TestNG 入门教程


