caffe2 二 : Models and Datasets 模型和数据集
来源:互联网 发布:还珠格格3知画结婚 编辑:程序博客网 时间:2024/05/12 07:16
New to Caffe and Deep Learning? Start here and find out more about the different models and datasets available to you.
这里介绍一些可用的模型和数据集。
Caffe2, Models, and Datasets Overview#
In this tutorial we will experiment with an existing Caffe model. In other tutorials you can learn how to modify a model or create your own. You can also learn how to generate or modify a dataset. Here you will learn how to find a model, what required files are involved, and how to test the model with a dataset.
这篇教程,我们基于训练好的Caffe模型进行试验。其他一些教程里有生成或修改模型的介绍。你也可以了解到如何生成或者修改数据集,了解到涉及哪些文件,了解到怎么使用数据集来对模型进行测试。
Models vs Datasets#
Let’s make sure you understand what is a model versus a dataset. Let’s start with the dataset. This is a collection of data, any data, but generally has some kind of theme to it, such as a collection of images of flowers. To accompany this collection you will also need some labels. This is a file that talks about each of the images and provides some kind of description. For example, it could be the genus and species, or it could be the common name, or it could be descriptors of how it looks, feels, or smells, or some combination thereof. In the example below, Mukane & Kendule proposed a method of extracting the flower from the image using image segmentation and feature extraction to pull the main flower out of the training image, then their classifier uses texture features to do the matching.
我们来区分一下模型和数据集。先来说数据集,数据集是特定主题下的一批数据,比如一批花の图片。和这个数据集合关联的是标记集合。标记集合用于对数据集合进行描述,比如 种,属,常用名,外观,气味等。下面例子中,Mukane 和 Kendule 使用图像分割和特征提取方法从图像中提取花,然后使用分类器通过纹理特征进行匹配。
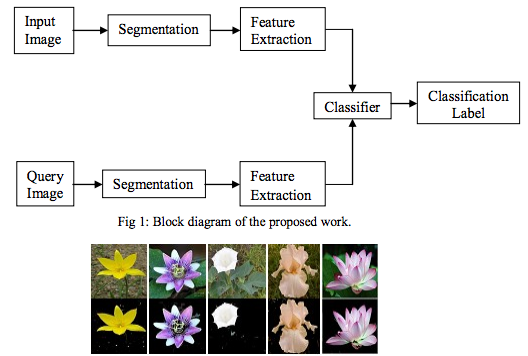
A model is what is created out of the dataset when you run it through a neural network. This is called training, where the neural network and the computer running it “learns” from the dataset. It picks apart all of the features it can find on how to recognize salient objects in the images based on features similar to other examples in the dataset and commonalities between the labels and so forth. There are a variety of types of neural networks that are designed for particular purposes which can create more accurate models than others. In the case of flowers and creating a model that is good at identifying them accurately, we would pick a convolutional neural network. We would do the same for identifying pictures of places. Take a look at the interactive example below which shows the extracted regions that the network found in common and how they link together across the layers of the network.
把数据运行在神经网络上,可产生出模型。这个过程称为训练 -- 神经网络从数据集中学到了模型。网络从图片中找到区分不同物体的关键特征,建立关键特征与数据标记的关系。我们使用卷积神经网络来建立一个模型去精确识别花的图片数据, 也用同样的方法来识别场景图片数据。 下面这个是一个互动例子,(链接 http://people.csail.mit.edu/torralba/research/drawCNN/drawNet.html). 例子中展示了网络从图片中提取到的局部特征区域,以及这些局部特征区域怎么通过网络被连接在一起。

Evaluating a Model’s Performance#
评估模型的性能
A common practice in creating a model is to evaluate its performance using two factors often called accuracy and loss. Another way to look at this is:
评估一个模型的性能常看两个因素:精度率和失败率
- accuracy: how often is it right versus wrong 精度率 : 模型正确识别的概率
- loss: how often did it fail to recognize anything when it should have 失败率 : 模型未能正确识别的概率
Each use case has different tolerances for these factors. If you’re powering an app to ID flowers, then a 92% accuracy rate is awesome; and if the loss is high, then you can rely on the user just trying a different angle with their camera until it works. If you’re looking for tumors, 92% accuracy is pretty good, but if your loss is very high, you might want to work a little harder on the model since medical imaging on its own is quite expensive and not easy to ask for more images or diferent angles if your model fails to pick something up. Evaluating for these factors is accomplished by taking the dataset and splitting it up into two parts:
- the first part is much larger and is used for training第一部分比较大一些,用于训练
- the second smaller part is used for testing第二部分比较小一些,用于测试
Splitting the Dataset#
划分数据集合
How the splits are decided or sampled, and how the labels are handled is something of another discussion. Suffice to say, think of this as an 80/20 percentage thing where you train on the 80 and test with the 20 and if the model does well on the 20 percent, then you have something you can use! “Does well” is subjective and up to you. You can get into optimizations like adjusting the dataset size, the labels, the neural network and its components, and hope to influence the speed of training, speed of detection, and accuracy, and other things that may or may not be of interest to you.
数据划分的规则和标签的处理是另外一个话题。通常可以用80%训练,用20%来测试。如果在20%的数据集上表现不错,那么这个模型就可以说是可用的了。
Many neural networking and deep learning tutorials use the MNIST handwriting dataset. When you download this dataset it usually comes ready to go in these parts, training and test, each with images and labels:
许多神经网络和深度学习教程都使用 MNIST 手写数据集来进行讲解。
MNIST Training Dataset#
- train-images-idx3-ubyte.gz: training set images (9912422 bytes)
- train-labels-idx1-ubyte.gz: training set labels (28881 bytes)
MNIST Test Dataset#
- t10k-images-idx3-ubyte.gz: test set images (1648877 bytes)
- t10k-labels-idx1-ubyte.gz: test set labels (4542 bytes)
This dataset was split up 60/10 - 60,000 training images and 10,000 test images. Don’t bother trying to open the files after unzipping them - they’re not human-readable, rather they’re in a format that requires parsing to be viewed. Further info on how the data was collected and formatted is on this research site.
数据集被分成了用于训练的 60000份数据和用于测试的10000份数据两部分。这里的数据格式不是直接可读的,需要进行格式转换才能够变成可视的。更多的关于MNIST数据格式信息可以参考:http://yann.lecun.com/exdb/mnist/
You can create a CNN using this dataset in the MNIST tutorial. 可以参考这里的MNIST教程创建一个CNN网络。
Caffe Model Zoo#
Caffe 模型仓库
One of the great things about Caffe and Caffe2 is the model zoo. This is a collection of projects provided by the Open Source community that describe how the models were created, what datasets were used, and the models themselves. In this way, you don’t actually have to do any of the training. You can simply download the model. You can also download the training data and test data to see how it works and verify for yourself the accuracy of the model with the provided test data.
Caffe 和 Caffe2 的吸引人的一个方面就是 Caffe 模型仓库 --- 这是一个项目的集合:项目来自于开源社区,一个项目会描述一个模型是怎样建立,使用了什么数据集,模型本身的属性。这种方式下,你不需要去做模型训练,你可以简单地下载模型来查看模型的工作方式,下载训练集和测试集来来测试模型的精度。
Custom Datasets#
It is a little trickier to test your own data though. We’ll cover that in another tutorial once you get a handle of playing with the provided models and their datasets. It is good to note while you try these out that you can combine datasets, sample/subset them, and tinker with their labels. You might decide you want less info on the labels, or more. You might also not include labels on some of the training data. This has an interesting side-effect of actually improving model performance in some cases by letting the network make some guesses during training. Our way of categorizing and annotating features doesn’t always map to how a computer’s neural network would do it. “Over-fitting” your data can lead to negative performance for the network.
测试自己的数据会稍微有一点复杂。等稍微掌握了模型仓库中的模型和数据集,会有另一篇教程介绍怎么使用自己数据。当进行项目尝试的时候,你可以合并,抽样,切分数据集,可以对标签进行修改调整。 你可以选择丰富或者减少标签信息。你也有可能在一些训练集上没有对应的标签,这种情况相当于训练过程中让网络去猜测,所以模型的性能会打折。我们对特征进行分类和标记的方法并不总是和计算机神经网络一致。“过拟合”会对网络性能有副作用。
Caffe Model Files#
Let’s jump into a specific example now that you have the overview. You will be looking at a small set of files that will be utilized to run a model and see how it works.
来看一个简单例子, 这里,几个文件展示如何运行一个模型
- .caffemodel or .pb2: these are the models; they’re binary and usually large files 模型文件:通常是大文件, 以这些名字结尾 .caffemodel 或者 .pb2
- caffemodel: from original Caffe 原始的 Caffe 产生和使用的模型
- pb2: from Caffe2 新的 Caffe2 产生和使用的模型
- deploy.prototxt: this is a json file that describes the design of neural network 结构描述文件:以 json 格式描绘了神经网络的设计
- solver.prototxt: this describes the variables that were used during training 变量描述文件:描述了训练过程中使用的变量
- train_val.prototxt:
- readme: this will have valuable info about how the model was trained and where you can find the model and dataset filesREADME文件:描述模型是怎么被训练的,以及说明模型和数据集在什么地方。
Example Models#
A small collection of pre-trained models is currently available at caffe2/models on Gihub: 一些训练好的模型。
- bvlc_alexnet
- bvlc_googlenet
- finetune_flickr_style
- squeezenet
Run a Model#
运行模型
If you want to skip over training, let’s take a look at a model that was pre-trained. Then we’re going to throw some of the test data at it and see what it does.
这里有一些训练好的模型 https://caffe2.ai/docs/tutorial-loading-pre-trained-models.html 。
稍后我们使用一些测试数据来测测 模型怎么运行
- caffe2 二 : Models and Datasets 模型和数据集
- Domain models and metadata(领域模型和元数据)
- 特征学习的matlab代码和数据集 Matlab Codes and Datasets for Feature Learning
- 数据集 DATASETS
- 一天学会MVC3之Views and Models(视图和模型)
- 结合MapReduce和数据集Combining datasets with MapReduce
- PETS-ICVS Datasets 数据集
- 指数族和广义线性模型(The exponential family and Generalized Linear Models)
- 【Model Thinking】L6 分类和线性模型 Categorical and Linear Models 学习笔记
- 计算机视觉著名数据集CV Datasets
- 深度学习数据集Deep Learning Datasets
- 计算机视觉著名数据集CV Datasets
- sklearn的数据集模块datasets
- 5 sklearn的数据集-datasets
- 计算机视觉著名数据集CV Datasets
- caffe2-- Workspaces(二)
- RDDs, DataFrames, and Datasets
- Django中的模型与数据库(Models and database)
- hadoop job yarn 命令
- bzoj 1432: [ZJOI2009]Function (数学||找规律)
- Python3简单教程(七)Python3模块
- Debian中PostgreSQL数据库安装配置实例
- 错误及解决办法:trackback (most recent call last) File “XXX文件路径” ,line 1, in <module> import pandas as pd
- caffe2 二 : Models and Datasets 模型和数据集
- 为什么说软件外包公司没前途
- 怎样将选中的单元格中的内容合并为一条字符串(string)
- java -Array数组操作
- (推荐读)java 并发编程: JVM底层又是如何实现synchronized的
- Java IO流框架概述
- 对http相关知识整理(来自MDN)
- Android中实现夜间模式
- 自用强大代码的各种整合


