基于nodejs的分布式服务构建
来源:互联网 发布:mac安装win7视频 编辑:程序博客网 时间:2024/05/17 07:54
1. 为什么要使用分布式架构
构建一个现代的大型网站,往往有着大量的访问,伴随之就是系统的压力非常之高,响应速度非常之慢。一些初期的解决办法包括设置静态页面缓存、数据缓存等虽然可以解燃眉之急,但最终仍要走向分布式架构,包括分布式缓存、分布式webserver、分布的数据库、文件系统等等。本文中,主要介绍分布式webserver。
2. 分布式服务器要解决哪些问题
分布式webserver的构建并不是单纯的增加服务器机子就可以的。有这个需求的web应用通常非常庞大,当多个团队都开始对其进行改动时,可真是相当的不方便,复用性也相当糟糕,基本是每个团队都做了或多或少重复的事情,而且部署和维护也是相当的麻烦,因为庞大的应用包在N台机器上复制、启动都需要耗费不少的时间,出问题的时候也不是很好查,另外一个更糟糕的状况是很有可能会出现某个应用上的bug就导致了全站都不可用,还有其他的像调优不好操作(因为机器上部署的应用什么都要做,根本就无法进行针对性的调优)等因素,概括起来,包括但不仅限于以下挑战:
- web应用拆成分布式后需要提供一个高性能、稳定的通信框架,并且需要支持多种不同的通信和远程调用方式;
- 将一个庞大的应用拆分需要耗费很长的时间,需要进行业务的整理和系统依赖关系的控制等;
- 如何运维(依赖管理、运行状况管理、错误追踪、调优、监控和报警等)好这个庞大的分布式应用。
- Apache的软负载或LVS软负载等无法承担巨大的web访问量(请求连接数、网络流量等)的调度了,这个时候如果经费允许的话,会采取的方案是购买硬件负载,例如F5、Netsclar、Athelon之类的,如经费不允许的话,会采取的方案是将应用从逻辑上做一定的分类,然后分散到不同的软负载集群中;
- 原有的一些状态信息同步、文件共享等方案可能会出现瓶颈,需要进行改进,也许这个时候会根据情况编写符合网站业务需求的分布式文件系统等;
3. 部署nodejs分布式服务
本文提供了nodejs下部署分布式服务的一些实践。
Node.js的cluster模块
Node.js给我们提供了cluster模块,它可以生成多个工作线程来共享同一个TCP连接。
它是如何运作的呢?
首先,Cluster会创建一个master,然后根据你指定的数量复制出多个server app(也被称之为工作线程)。它通过IPC通道与工作线程之间进行通信,并使用内置的负载均衡来更好地处理线程之间的压力,该负载均衡使用了Round-robin算法(也被称之为循环算法)。
当使用Round-robin调度策略时,master accepts()所有传入的连接请求,然后将相应的TCP请求处理发送给选中的工作线程(该方式仍然通过IPC来进行通信)。
那如何来使用呢?
下面是一个最基本的例子:
var cluster = require('cluster'); var http = require('http'); var os = require('os');var numCPUs = os.cpus().length;if (cluster.isMaster) { // Master: // Let's fork as many workers as you have CPU cores for (var i = 0; i < numCPUs; ++i) { cluster.fork(); }} else { // Worker: // Let's spawn a HTTP server // (Workers can share any TCP connection. // In this case its a HTTP server) http.createServer(function(req, res) { res.writeHead(200); res.end("hello world"); }).listen(8080);}当然,你可以指定任意数量的工作线程,线程的数量不仅限于CPU核心的数量,因为它只是作为一个运行在CPU上的子线程。
正如你所看到的,要使其正常运行,你需要将你的代码封装到cluster的处理逻辑中,并添加一些额外的代码来指定当一个线程挂掉之后如何进行处理。
使用PM2的方式
PM2内部包含了所有上述的处理逻辑,因此你不必对代码做任何修改。我们将上面的代码还原成最原始的形式:
var http = require('http');http.createServer(function(req, res) { res.writeHead(200); res.end("hello world");}).listen(8080);然后在控制台执行:
$ pm2 start app.js -i 4
-i 参数用来告诉PM2以cluster_mode的形式运行你的app(对应的叫fork_mode),后面的数字表示要启动的工作线程的数量。如果给定的数字为0,PM2则会根据你CPU核心的数量来生成对应的工作线程。
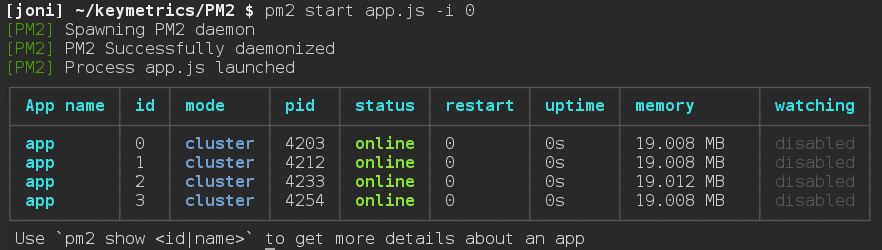
不论什么情况下,保持你的apps一直运行
如果任意一个工作线程挂掉了,不用担心,PM2会立即将其重启。当然,你也完全可以在任何时候手动重启这些线程:
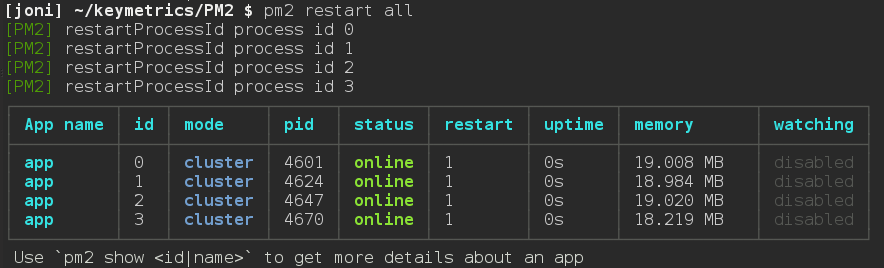
实时扩展集群
任何时候,如果你需要增加工作线程的数量,可以通过pm2 scale <app name> <n>来对集群进行扩展。参数<n>指定工作线程的数量,被用来增加或减少集群数。你也可以通过pm2 scale app +3的方式来指定要增加多少工作线程。

在产品环境实现零停机更新
PM2的reload 功能将依次重启所有的工作线程。每一个线程会等待在新的线程创建之后才会被终止掉,因此,当你在产品环境部署新的代码时,server会不间断地一直保持运行。
使用gracefulReload功能可以达到相同的目的,不同的是它不会立即终止工作线程,而是通过IPC发送一个shutdown信号来关闭所有当前的连接并处理一些自定义的任务,然后再优雅地退出。如下面的代码:
process.on('message', function(msg) { if (msg === 'shutdown') { close_all_connections(); delete_cache(); server.close(); process.exit(0); }});将PM2配置成自动启动
想要PM2在服务器重启后自动运行之前的应用,可以先通过pm2 start启动你的应用,然后执行下面的命令:
pm2 save这将在~/.pm2目录下生成一个dump.pm2文件,里面描述了当前PM2上运行着的所有应用。然后执行命令:
pm2 startup [platform]注意有必要添加可选参数platform以明确告知pm2当前的系统环境。这样,下次当服务器重启时,PM2会自动运行之前保存的应用。
参考链接:
分布式web服务器架构
nodejs分布式架构
玩转nodejs的集群
使用PM2
- 基于nodejs的分布式服务构建
- 构建基于 NodeJS 的 LESS.js 预编译 CSS 服务
- 基于Dubbo框架构建分布式服务
- 基于Dubbo框架构建分布式服务
- 基于Dubbo框架构建分布式服务(顶)
- 基于Dubbo框架构建分布式服务
- 基于Dubbo框架构建分布式服务
- 基于Dubbo框架构建分布式服务
- 基于Dubbo框架构建分布式服务
- 基于Dubbo框架构建分布式服务
- 基于Dubbo框架构建分布式服务
- 基于Dubbo框架构建分布式服务
- 基于Dubbo框架构建分布式服务
- 基于Dubbo框架构建分布式服务【续】
- 基于Dubbo框架构建分布式服务
- 基于Dubbo框架构建分布式服务
- 基于Dubbo框架构建分布式服务
- nodejs中UDP服务的构建
- 医学图像分割--Topology Aware Fully Convolutional Networks For Histology Gland Segmentation
- 获取访问者IP
- 网易2017春招笔试真题集合
- <a>标签嵌套图片使用方法
- 【微信小程序】各种页面特殊效果合集第二期
- 基于nodejs的分布式服务构建
- HBase最佳实践-读性能优化策略
- 王小波全集读后感
- gh0st源码分析与远控的编写(二)
- Android 关于Glide的拓展(高斯模糊、加载监听、圆角图片)
- React-native 第三方组件
- 《算法导论》第23章 最小生成树 个人笔记
- 33. secure world对smc请求的处理------invoke command操作在OP-TEE中的实现
- Out of memory解决办法


