spark-submit 参数设置说明
来源:互联网 发布:linux cp 两个文件 编辑:程序博客网 时间:2024/05/19 19:44
原文:https://intl.aliyun.com/help/zh/doc-detail/28124.htm
本章节将介绍如何在 E-MapReduce 场景下设置 spark-submit 的参数。
集群配置
软件配置
E-MapReduce 产品版本 1.1.0
Hadoop 2.6.0
Spark 1.6.0
硬件配置
Master 节点
8 核 16G 500G 高效云盘
1 台
Worker 节点 x 10 台
8 核 16G 500G 高效云盘
10 台
总资源:8 核 16G(Worker)x 10 + 8 核 16G(Master)
注意:由于作业提交的时候资源只计算 CPU 和内存,所以这里磁盘的大小并未计算到总资源中。
Yarn 可分配总资源:12 核 12.8G(worker)x 10
注意:默认情况下,yarn 可分配核 = 机器核 x 1.5,yarn 可分配内存 = 机器内存 x 0.8。
提交作业
创建集群后,您可以提交作业。首先,您需要在 E-MapReduce 中创建一个作业,配置如下:
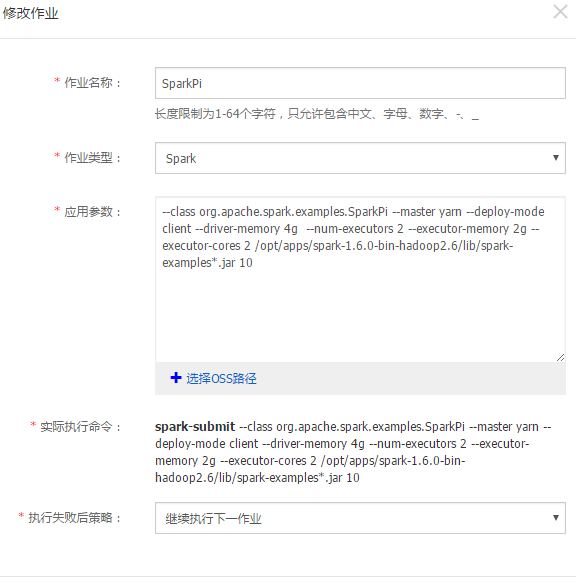
上图所示的作业,直接使用了 Spark 官方的 example 包,所以不需要自己上传 jar 包。
参数列表如下所示:
--class org.apache.spark.examples.SparkPi --master yarn --deploy-mode client --driver-memory 4g –num-executors 2 --executor-memory 2g --executor-cores 2 /opt/apps/spark-1.6.0-bin-hadoop2.6/lib/spark-examples*.jar 10
参数说明如下所示:
yarn-client等同于 –-master yarn —deploy-mode client, 此时不需要指定deploy-mode。
yarn-cluster等同于 –-master yarn —deploy-mode cluster, 此时不需要指定deploy-mode。deploy-modeclientclient 模式表示作业的 AM 会放在 Master 节点上运行。要注意的是,如果设置这个参数,那么需要同时指定上面 master 为 yarn。
clustercluster 模式表示 AM 会随机的在 worker 节点中的任意一台上启动运行。要注意的是,如果设置这个参数,那么需要同时指定上面 master 为yarn。driver-memory4gdriver 使用的内存,不可超过单机的 core 总数。num-executors2创建多少个 executor。executor-memory2g各个 executor 使用的最大内存,不可超过单机的最大可使用内存。executor-cores2各个 executor 使用的并发线程数目,也即每个 executor 最大可并发执行的 Task 数目。
资源计算
在不同模式、不同的设置下运行时,作业使用的资源情况如下表所示:
yarn-client 模式的资源计算
memdriver-memroy = 4Gworkercorenum-executors * executor-cores = 4
memnum-executors * executor-memory = 4G
作业主程序(Driver 程序)会在 master 节点上执行。按照作业配置将分配 4G(由 —driver-memroy 指定)的内存给它(当然实际上可能没有用到)。
会在 worker 节点上起 2 个(由 —num-executors 指定)executor,每一个 executor 最大能分配 2G(由 —executor-memory 指定)的内存,并最大支持 2 个(由- -executor-cores 指定)task 的并发执行。
yarn-cluster 模式的资源计算
一个很小的 client 程序,负责同步 job 信息,占用很小。workercorenum-executors * executor-cores+spark.driver.cores = 5
memnum-executors * executor-memory + driver-memroy = 8g
注意:这里的 spark.driver.cores 默认是 1,也可以设置为更多。
资源使用的优化
yarn-client 模式
若您有了一个大作业,使用 yarn-client 模式,想要多用一些这个集群的资源,请参见如下配置:
注意:
- Spark 在分配内存时,会在用户设定的内存值上溢出 375M 或 7%(取大值)。
- Yarn 分配 container 内存时,遵循向上取整的原则,这里也就是需要满足 1G 的整数倍。
--master yarn-client --driver-memory 5g –-num-executors 20 --executor-memory 4g --executor-cores 4
按照上述的资源计算公式,
master 的资源量为:
- core:1
- mem:6G (5G + 375M 向上取整为 6G)
workers 的资源量为:
- core: 20*4 = 80
- mem: 20*5G (4G + 375M 向上取整为 5G) = 100G
可以看到总的资源没有超过集群的总资源,那么遵循这个原则,您还可以有很多种配置,例如:
--master yarn-client --driver-memory 5g –num-executors 40 --executor-memory 1g --executor-cores 2
--master yarn-client --driver-memory 5g –num-executors 15 --executor-memory 4g --executor-cores 4
--master yarn-client --driver-memory 5g –num-executors 10 --executor-memory 9g --executor-cores 6
原则上,按照上述的公式计算出来的需要资源不超过集群的最大资源量就可以。但在实际场景中,因为系统,hdfs 以及 E-MapReduce 的服务会需要使用 core 和 mem 资源,如果把 core 和 mem 都占用完了,反而会导致性能的下降,甚至无法运行。
executor-cores 数一般也都会被设置成和集群的可使用核一致,因为如果设置的太多,CPU 会频繁切换,性能并不会提高。
yarn-cluster 模式
当使用 yarn-cluster 模式后,Driver 程序会被放到 worker 节点上。资源会占用到 worker 的资源池子里面,这时若想要多用一些这个集群的资源,请参加如下配置:
--master yarn-cluster --driver-memory 5g –num-executors 15 --executor-memory 4g --executor-cores 4
配置建议
如果将内存设置的很大,要注意 gc 所产生的消耗。一般我们会推荐一个 executor 的内存 <= 64G。
如果是进行 HDFS 读写的作业,建议是每个 executor 中使用 <= 5个并发来读写。
如果是进行 OSS 读写的作业,我们建议是将 executor 分布在不同的 ECS 上,这样可以将每一个 ECS 的带宽都用上。比如有 10 台 ECS,那么就可以配置 num-executors=10,并设置合理的内存和并发。
如果作业中使用了非线程安全的代码,那么在设置 executor-cores 的时候需要注意多并发是否会造成作业的不正常。如果会,那么推荐就设置 executor-cores=1。
- spark-submit 参数设置说明
- spark-submit提交参数设置
- spark submit参数说明
- Spark-submit参数说明
- spark-submit工具参数说明
- spark-submit工具参数说明
- spark-submit使用及说明
- spark-submit工具参数说明
- spark-submit工具参数说明
- spark-submit工具参数说明
- spark-submit
- spark-submit
- spark-submit
- spark-submit
- spark-submit
- spark-submit
- Spark 之 spark submit
- Spark spark-submit 参数
- 中断和异常
- Android Studio更新到3.0以后,预览无法显示 v4,v7包控件的解决方法
- 采用感知哈希算法基于python-PIL的图像去重
- 安卓Activity的退出应用程序
- FPGA学习过程记录一
- spark-submit 参数设置说明
- 关系型数据库与数据库管理系统
- 什么是servlet:1分钟理解Servlet的概念
- python学习笔记(循环)
- cocos2dx 植物大战僵尸 24 坚果和大坚果
- 三种攻击方式简介xss,crsf,sqlins
- android中 双击系统返回键退出
- 顺时针打印矩阵
- 【Python】Turtle画图04


