面试零碎知识点小计
来源:互联网 发布:数据之魅百度网盘 编辑:程序博客网 时间:2024/06/05 11:29
solrcloud搭建集群时,因为大索引量大并发量,所以也需要将zookeer搭建集群(此时他作为配置中心管理solr的配置文件)
dubbo使用zookeer是为了做注册中心
常见的数据库的优化: 1.索引 :但也不要假如过多冗余索引,因为过多的索引会导致索引碎片:
2.缓存
3.分表 :针对每个时间周期产生大量的数据,可以考虑采用一定的策略将数据存到多个数据表中
4.分库 :就是将系统按照模块相关的特征分布到不同的数据中,以提高系统整体负载能力
5.sql优化. in 和 not in 也要慎用,因为IN会使系统无法使用索引,而只能直接搜索表中的数据
当判断真假时,and尽量把假的放到右边(一个为假就为假)
尽量不要select * 很多时候用exists是一个好的选择 where语句中如果有多个过滤条件应将过滤记录数量最多的条件放在最前面
6.主从
TRUNCATE TABLE:删除内容、释放空间但不删除定义。相当于以前讲的干掉表然后重建只能删除全部,delete可以删部分
DELETE TABLE:删除内容不删除定义,不释放空间。
DROP TABLE:删除内容和定义,释放空间。
批量增删:使用foreach
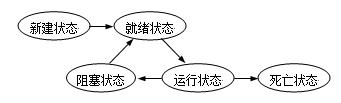
线程的五种状态
1)新建状态: 当一个线程处于新生状态时,程序还没有开始运行线程中的代码
2)就绪状态:执行线程,必须调用线程的start()方法,当线程对象调用start()方法即启动了线程,start()方法创建线程运行的系统资源,并调度线程运行run()方法.当start()方法返回后,线程就处于就绪状态。就绪状态的线程并不一定立即运行run()方法,线程还必须同其他线程竞争CPU时间
3)运行状态:当线程获得CPU时间后,它才进入运行状态,真正开始执行run()方法
4)阻塞状态:各种原因 :sleep方法进入睡眠状态 调用一个在I/O上被阻塞的操作 试图得到一个锁,而该锁正被其他线程持有 线程在等待某个触发条件;
5)死亡状态:两个原因: 1run方法正常退出而自然死亡 2 一个未捕获的异常终止了run方法而使线程猝死
stringbuffer线程安全 stringBuiler线程不安全 string是不可的,每次改变它时,都要重新创建对象,占内存,效率低下
hibernate一二级缓存: 1,session缓存 save,get,load方法会存入一级缓存 1. evit()将指定的持久化对象从缓存中清除,释放对象所占用的内存资源,指定对象从持久化状态变为脱管状态,从而成为游离对象。
2. clear()将缓存中的所有持久化对象清除,释放其占用的内存资源。
2.sessionFactory缓存 可以跨session取缓存 (应用场景:经常访问,改动不大,数量有限,不是很重要的数据)
mybatis一二级缓存: 一级缓存:session级别的,二级缓存map.xml中select语句查询后会将结果放入二级缓存,以便后来使用(不确定)
hashmap的底层实现原理:HashMap底层就是一个数组结构,数组中的每一项又是一个链表。当新建一个HashMap的时候,就会初始化一个数组.当我们往HashMap中put元素的时候,先根据key的hashCode重新计算hash值,根据hash值得到这个元素在数组中的位置(即下标),如果数组该位置上已经存放有其他元素了,那么在这个位置上的元素将以链表的形式存放,新加入的放在链头,最先加入的放在链尾。如果数组该位置上没有元素,就直接将该元素放到此数组中的该位置上。
集合方面:
List 元素是有序的、可重复
ArrayList、Vector默认初始容量为10
Vector:线程安全,但速度慢
底层数据结构是数组结构
加载因子为1:即当 元素个数 超过 容量长度 时,进行扩容
扩容增量:原容量的 1倍
如 Vector的容量为10,一次扩容后是容量为20
ArrayList:线程不安全,查询速度快
底层数据结构是数组结构
扩容增量:原容量的 0.5倍+1
如 ArrayList的容量为10,一次扩容后是容量为16
Set(集) 元素无序的、不可重复。
HashSet:线程不安全,存取速度快
底层实现是一个HashMap(保存数据),实现Set接口
默认初始容量为16(为何是16,见下方对HashMap的描述)
加载因子为0.75:即当 元素个数 超过 容量长度的0.75倍 时,进行扩容
(为何加载因子小于1而不等于1:当向Set中添加对象始,首先调用此对象所在类的hashCode()方法。
计算此对象的哈希值,此哈希值决定了此对象在set中的位置。存储空间不是连续的)
扩容增量:原容量的 1 倍
如 HashSet的容量为16,一次扩容后是容量为32
Map是一个双列集合
HashMap:默认初始容量为16
(为何是16:16是2^4,可以提高查询效率,另外,32=16<<1 -->至于详细的原因可另行分析,或分析源代码)
加载因子为0.75:即当 元素个数 超过 容量长度的0.75倍 时,进行扩容
扩容增量:原容量的 1 倍
如 HashSet的容量为16,一次扩容后是容量为32
ArrayList list = new ArrayList(20);中的list扩充几次?
答:0次。
解析: ArrayList list=new ArrayList(); 这种是默认创建大小为10的数组,每次扩容大小为1.5倍。
ArrayList list=new ArrayList(20); 这种是指定数组大小的创建,没有扩充。
1 HashMap不是线程安全的
hastmap是一个接口 是map接口的子接口,是将键映射到值的对象,其中键和值都是对象,并且不能包含重复键,但可以包含重复值。HashMap允许null key和null value,而hashtable不允许。
2 HashTable是线程安全的一个Collection。
HashMap是Hashtable的轻量级实现(非线程安全的实现),他们都完成了Map接口,主要区别在于HashMap允许空(null)键值(key),由于非线程安全,效率上可能高于Hashtable。
HashMap允许将null作为一个entry的key或者value,而Hashtable不允许。
HashMap把Hashtable的contains方法去掉了,改成containsvalue和containsKey。因为contains方法容易让人引起误解。
Hashtable继承自Dictionary类,而HashMap是Java1.2引进的Map interface的一个实现。
最大的不同是,Hashtable的方法是Synchronize的,而HashMap不是,在多个线程访问Hashtable时,不需要自己为它的方法实现同步,而HashMap 就必须为之提供外同步。
分布式登录系统存在问题:切换系统需要重新登录 解决办法:单点登录
集群环境登录系统存在问题:session分离 解决办法:session共享: 方式一:使用Tomcat自身的同步机制复制session到集群中的其他服务器(最佳数量5台)。
方式二:使用缓存服务器集中存储session信息达到session共享需求
- 面试零碎知识点小计
- android 项目零碎知识点小计
- Java面试零碎知识点
- 零碎知识点
- 零碎知识点
- 零碎知识点
- 零碎知识点
- 零碎知识点
- 零碎知识点
- 零碎知识点
- 零碎知识点
- 零碎知识点
- 零碎知识点
- 零碎知识点
- 零碎知识点
- 零碎知识点
- 零碎知识点
- 零碎知识点
- B2Ctt商城04 ftp 商品规格实现
- 一、学习股市常识
- GitHub学习-----github上删除自己的repository
- 从MongoDB同步数据到ElasticSearch 的五种方式
- CSS3的calc()使用
- 面试零碎知识点小计
- python 中文编码问题
- 不想每天碌碌无为的度过,也为自己留下一点回忆。
- Codeforces Dragons
- 分布式爬虫原理与实现
- format C/C++中的%010u是个什么东东?
- Linux 常用命令
- 腾讯云linux系统部署tomcat并简单部署程序到tomcat
- pytorch-containers


