图像分割、目标检测 MASK R-CNN 论文阅读笔记
来源:互联网 发布:淘宝童装裤子 编辑:程序博客网 时间:2024/06/05 20:32
图像分割、目标检测 MASK R-CNN 论文阅读笔记
原文: MASK R-CNN作者: Kaiming He, Georgia Gkioxari, Piotr Dollar, Ross Girshick下载地址: https://arxiv.org/abs/1703.068701 简介
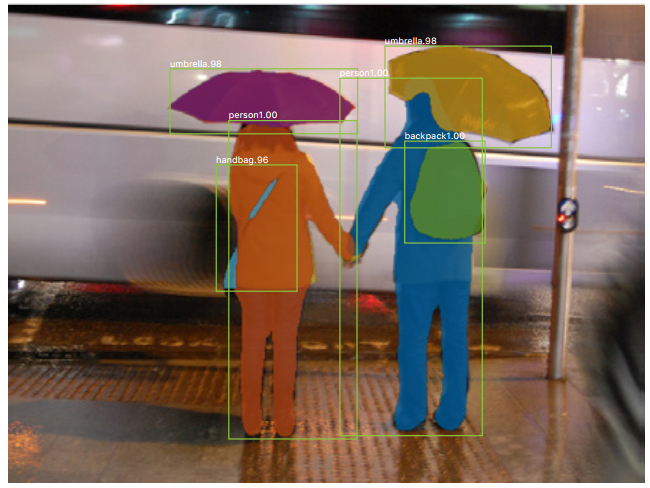
- 作者提出的Mask R-CNN是Faster R-CNN的升级版,以往Faster R-CNN可以实现分类和目标检测,现在Mask R-CNN又多了一个分割功能。以下面的图为例,绿色的矩形框是目标检测,白色的文字是分类结果,人身上的色块则是图像分割的结果。Mask R-CNN的分类、检测、分割三个输出都是并行的。
- Mask R-CNN做的是实例分割,而不是语义分割。二者的区别是:后者只需要把一张图中属于某一类的东西全部抠出来就好了,而前者要把某一类中不同的个体再细抠出来。
- 先对其性能有个大致的了解。Mask R-CNN的运行速度达到了5fps,还是相当不错的,而准确度远超过COCO 15和16的冠军。作者还谦虚表示,此模型只是一个baseline,从这里还可以发展出更多优秀的算法,并表示代码会开源。
2 模型介绍
- 在Mask R-CNN中,新增加的mask输出分支虽然和classification、bounding box两个输出是并行关系,但mask更加复杂一些,需要物体更精细的空间分布。作者接下来也是着重介绍网络中关于mask生成的部分。其中最主要的是pixel-to-pixel alignment。
2.1 Faster R-CNN 简单回顾
- 此部分可以参考我的博文 目标检测 Faster R-CNN 论文笔记。Faster R-CNN分成RPN和Fast R-CNN两个部分。前者从一张图像中提取特征图,选出候选区域,用向量表示;后者承接前面的向量,用全连接网络分别输出classification和bounding box。

2.2 Mask 表示
- Mask其实就是一个0-1二值图片,尺寸和原图完全相等。对于每个ROI,都有 K 个 m*m 分辨率的mask,其中K表示类别数量。从1个ROI到K个mask的过程,用全卷积层(FCN)传播,这样可以保持每层的尺寸不会缩减。
2.3 Mask R-CNN损失
- 在训练时,作者仿照Faster R-CNN定义一个多任务损失:
L=Lcls+Lbox+Lmask - 为表示mask的损失
Lmask ,只要对于每一个像素,用sigmod函数进行求相对熵,得到平均相对熵的误差即可。对于第k个类别,Lmask 也只由第k个mask和第k个ground truth计算得到,其他mask不参与贡献。像这样为每个class都生成一个mask有一个好处,就是不同的类之间不会出现竞争情况。
2.4 ROIAlign
- 说道此部分,首先先了解一下 Faster R-CNN 中的 ROIPool。首先量化ROI值,比如通过网络得出的ROI左上角坐标是(10.1,12.3),量化后为(10,12)。 接着量化后的ROI被分成固定的几个区域;最后每个区域聚合成一个值(见http://blog.csdn.net/cyiano/article/details/70141957#t4)。这样的结果是不论何种大小的输入都会变成同一种尺寸大小的输出。
- 顺便一提,如果ROIPool前后的尺寸不是整除关系怎么办呢(比如从7*7pooling到3*3):只要取整就好了。此时ROI被分出来的每个窗口大小是
cell(7/3) ,而窗口滑动步长是floor(7/3) ,大家可以自己在纸上比划一下。 - 上述的这种ROIPool会导致ROI和提取特征之间的misalignments。因此需要用ROIAlign来解决:

2.5 网络结构
- 作者将网络分成两个部分:用于提取特征的“backbone”,和用于classification、regression、mask prediction的“head”。
- “backbone”方面,作者用了两种不同深度的残差网络:50层的ResNet和101层的ResNeXt。这几个残差可以分成4段,特征将在最后的卷积层C4提取出来。另外,作者还使用了Feature Pyramid Network(FPN)。FPN会从不同等级的特征金字塔中提取ROI特征,实验也表明,在backbone中用FPN效果更好。
- “head”方面,根据之前的backbone是Resnet还是FPN有两种形式:

3 实例分割实验
3.1 主要结果
- 作者采用的评价框架是COCO,指标有
AP (averaged over IOU thresholds),AP50 ,AP75 ,APS ,APM ,APL 。训练图像85k张,验证图像35k张,用于剥离实验的图像5k张。 - 实验结果如下面的Table1,与前两年COCO冠军相比,Mask R-CNN取得了很好的结果。FCIS+++在重叠的实例部分展示出systematic artifacts,而Mask R-CNN则不会。


3.2 剥离实验
只说结果:
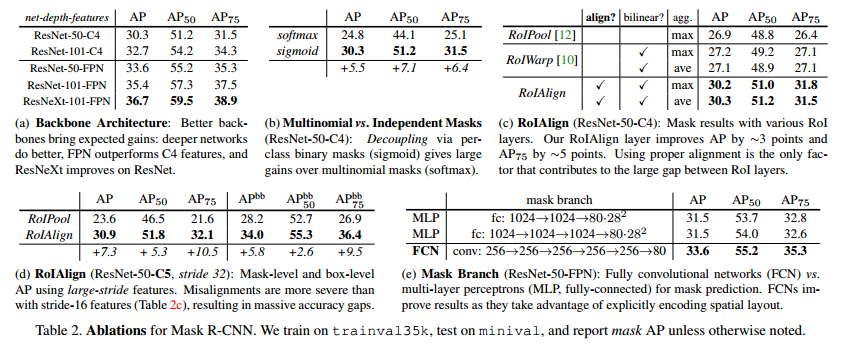
- 结构方面,使用FPN或ResNeXt可以改善AP,增加网络层数也可以进一步改善。
- Mask R-CNN分离了分类和掩膜两个任务,相比于二者联合的方法,性能提高不少。
- 对于分类不可知的mask性能没有比分类可知的差太多。
- RoIAlign对pool时用max还是average不敏感;RoIAlign与RoIPool和RoIWarp相比,效果明显更好,RoIWarp虽然用到了双三次采样,但还是引进了量化过程。
- 当RoIAlign用在更大步长的网络层中时(32),AP增长更高一些。因为大步长时,misalignment更严重,原先的RoIPool方法更加恶化。
- FCN比MLP好。
3.3 bounding box 检测结果
- 除了Mask R-CNN,作者另外训练了一个没有mask部分的网络:Faster R-CNN, RoIAlign。它与Mask R-CNN两个版本均超过了原有的方法。注意到Mask R-CNN比Faster R-CNN, RoIAlign低一些,这主要受益于多任务训练(原因不明)。
3.4 时间
- 对于ResNet-101-FPN,195ms per image on an Nvidia Tesla M40 GPU (plus 15ms CPU time resizing the outputs to the original resolution)。对于ResNet-101-C4,takes ∼400ms as it has a heavier box head。
- Training with ResNet-50-FPN on COCO trainval35k takes 32 hours in our synchronized 8-GPU implementation (0.72s per 16- image mini-batch), and 44 hours with ResNet-101-FPN.
阅读全文
0 0
- 图像分割、目标检测 MASK R-CNN 论文阅读笔记
- 目标检测分割--Mask R-CNN
- 论文阅读-《Mask R-CNN》
- Mask R-CNN(目标检测,语义分割)测试
- 目标检测 Fast R-CNN 论文笔记
- 目标检测 Faster R-CNN 论文笔记
- 论文笔记:Mask R-CNN
- 论文阅读:《Mask R-CNN》ICCV2017
- Mask R-CNN-论文笔记-理解
- R-CNN-目标检测、定位、分割
- 《Mask R-CNN》论文学习
- Mask R-CNN论文导读
- 【论文翻译】Mask R-CNN
- CNN在图像分割中的简史:从 R-CNN 到Mask R-CNN
- 目标检测算法理解:从R-CNN到Mask R-CNN
- 【深度学习:目标检测】RCNN学习笔记(7):Faster R-CNN 英文论文翻译笔记
- 卷积神经网络在图像分割中的进化史:从R-CNN到Mask R-CNN
- 用于图像分割的卷积神经网络:从R-CNN到Mask R-CNN
- HTML5 CSS3 精美案例 : 实现VCD包装盒个性幻灯片
- OpenCv像素点获取与修改
- Mac中jdk 和sdk环境变量的配置
- js检测是否含有emoji表情
- python学习 Generator Iterator
- 图像分割、目标检测 MASK R-CNN 论文阅读笔记
- 窗体部件之QActionGroup
- C++ 结构体初始化新方法
- 脚本实例
- Linux上两个版本的python的pip问题(2017.6)
- Centos6.4上安装Nginx
- 深入浅出JMS(一)--JMS基本概念
- Web前端--CSS中margin和padding的区别
- linux 查看内存,cpu使用


